在分布式系统中,经常会碰到这样的场景:对于一个复杂的任务,仅需要从集群中选举出一台进行处理即可。诸如此类的分布式问题,我们统称为 “Master 选举” ,借助 ZooKeeper,我们可以比较方便的实现 Master选举的功能,其大体思路非常简单:
选择一个根节点,例如 /master_select ,多台机器同时向该节点创建一个 子节点 /master_select/lock,利用 ZooKeeper 的特性,最终只有一台机器能够创建成功,成功的那台机器就作为 Master
一、使用场景
现在很多时候我们的服务需要7*24小时工作,假如一台机器挂了,我们希望能有其它机器顶替它继续工作。此类问题现在多采用master-salve模式,也就是常说的主从模式,正常情况下主机提供服务,备机负责监听主机状态,当主机异常时,可以自动切换到备机继续提供服务(这里有点儿类似于数据库主库跟备库,备机正常情况下只监听,不工作),这个切换过程中选出下一个主机的过程就是master选举。 对于以上提到的场景,传统的解决方式是采用一个备用节点,这个备用节点定期给当前主节点发送ping包,主节点收到ping包后会向备用节点发送应答ack,当备用节点收到应答,就认为主节点还活着,让它继续提供服务,否则就认为主节点挂掉了,自己将开始行使主节点职责,但这种方式会存在一个隐患,就是网络故障问题
我们的主节点并没有挂掉,只是在备用节点ping主节点,请求应答的时候发生网络故障,这样我们的备用节点同样收不到应答,就会认为主节点挂掉,然后备机会启动自己的master实例。这样就会导致系统中有两个主节点,也就是双master。出现双master以后,我们的从节点会将它做的事情一部分汇报给主节点,一部分汇报给备用节点,这样服务就乱套了。为了防止这种情况出现,我们可以考虑采用zookeeper,虽然它不能阻止网络故障的出现,但它能保证同一时刻系统中只存在一个主节点。
一点额外的话:zookeeper自己在集群环境下的抢主算法有三种,可以通过配置文件来设定,默认采用FastLeaderElection,不作赘述;此处主要讨论集群环境中,应用程序利用master的特点,自己选主的过程。程序自己选主,每个人都有自己的一套算法,有采用“最小编号”的,有采用类似“多数投票”的,各有优劣,本文的算法仅作演示理解使用:
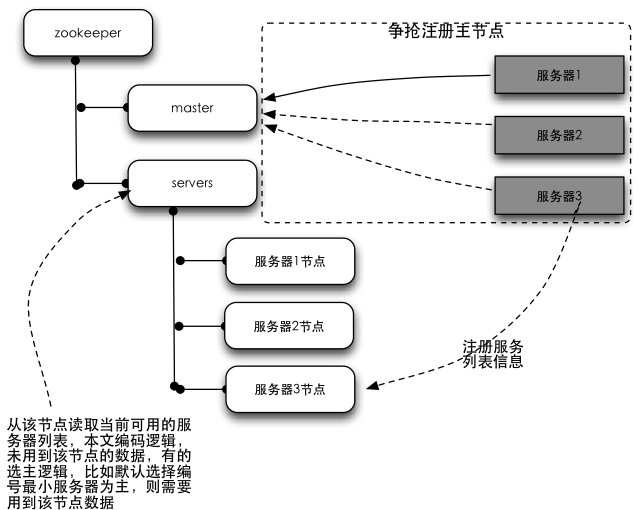
结构图解释:左侧树状结构为zookeeper集群,右侧为程序服务器。所有的服务器在启动的时候,都会订阅zookeeper中master节点的删除事件,以便在主服务器挂掉的时候进行抢主操作;所有服务器同时会在servers节点下注册一个临时节点(保存自己的基本信息),以便于应用程序读取当前可用的服务器列表。
选主原理介绍:zookeeper的节点有两种类型,持久节点跟临时节点。临时节点有个特性,就是如果注册这个节点的机器失去连接(通常是宕机),那么这个节点会被zookeeper删除。选主过程就是利用这个特性,在服务器启动的时候,去zookeeper特定的一个目录下注册一个临时节点(这个节点作为master,谁注册了这个节点谁就是master),注册的时候,如果发现该节点已经存在,则说明已经有别的服务器注册了(也就是有别的服务器已经抢主成功),那么当前服务器只能放弃抢主,作为从机存在。同时,抢主失败的当前服务器需要订阅该临时节点的删除事件,以便该节点删除时(也就是注册该节点的服务器宕机了或者网络断了之类的)进行再次抢主操作。从机具体需要去哪里注册服务器列表的临时节点,节点保存什么信息,根据具体的业务不同自行约定。选主的过程,其实就是简单的争抢在zookeeper注册临时节点的操作,谁注册了约定的临时节点,谁就是master。
ps:本文的例子中,并未用到结构图server节点下的数据。但换一种算法或者业务场景就会用到,算法比如提到的最小编号,主要逻辑是主节点挂掉后,从节点里边编号最小的成为主节点,此时会用到该节点内容。换一种业务场景:集群环境中,有很多任务要处理, 主节点负责接收任务,并根据一定算法将任务分配到不同的机器上执行;这种情况下,主节点跟从节点的职责也是不同的,主节点挂掉也会涉及到从节点进行master选举的问题。这种情况下,很显然,作为主节点需要知道当前有多少个从节点还活着,那么此时也会需要用到servers节点下的数据了。
二、编码实现
主要有两个类,WorkServer为主服务类,RunningData用于记录运行数据。因为是简单的demo,我们只做抢master节点的编码,对于从节点应该去哪里注册服务列表信息,不作编码。
WorkServer类:
package xyx.tuny.master;import com.alibaba.fastjson.JSON;
import org.I0Itec.zkclient.exception.ZkInterruptedException;
import org.I0Itec.zkclient.exception.ZkNoNodeException;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.recipes.cache.NodeCache;
import org.apache.curator.framework.recipes.cache.NodeCacheListener;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.data.Stat;import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;public class WorkServer {//客户端状态private volatile boolean running = false;private CuratorFramework client;//主节点路径public static final String MASTER_PATH = "/master";//监听(用于监听主节点删除事件)private NodeCacheListener dataListener;//服务器基本信息private RunningData serverData;//主节点基本信息private RunningData masterData;private NodeCache cache;//调度器private ScheduledExecutorService delayExector = Executors.newScheduledThreadPool(1);//延迟时间5sprivate int delayTime = 5;public WorkServer(RunningData runningData) {this.serverData = runningData;}//启动public void start() throws Exception {if (running) {throw new Exception("server has startup....");}running = true;client.start();this.cache = new NodeCache(client, MASTER_PATH, false);this.dataListener = new NodeCacheListener() {@Overridepublic void nodeChanged() throws Exception {//System.out.println("--nodes changed and previous server is " + masterData.getName() + "--");Stat stat = client.checkExists().forPath(MASTER_PATH);if(null == stat){//takeMaster();if (masterData != null && masterData.getName().equals(serverData.getName())) {//若之前master为本机,则立即抢主,否则延迟5秒抢主(防止小故障引起的抢主可能导致的网络数据风暴)System.out.println("--now server " + serverData.getName() + " has privilege to take master");takeMaster();} else {delayExector.schedule(new Runnable() {@Overridepublic void run() {takeMaster();}}, delayTime, TimeUnit.SECONDS);}}}};this.cache.getListenable().addListener(dataListener);try {cache.start();} catch (Exception e) {e.printStackTrace();}takeMaster();}//停止public void stop() throws Exception {if (!running) {throw new Exception("server has stopped.....");}running = false;delayExector.shutdown();cache.getListenable().removeListener(dataListener);releaseMaster();}//抢注主节点private void takeMaster() {if (!running) return;try {client.create().withMode(CreateMode.PERSISTENT).forPath(MASTER_PATH, JSON.toJSONString(serverData).getBytes());masterData = serverData;System.out.println("--" + serverData.getName() + " now is Master--");delayExector.schedule(new Runnable() {//测试抢主用,每5s释放一次主节点@Overridepublic void run() {if (checkMaster()) {releaseMaster();}}}, 5, TimeUnit.SECONDS);} catch (Exception e){//节点已存在String retJson = null;try {retJson = new String(client.getData().forPath(MASTER_PATH));RunningData runningData = null;runningData = (RunningData)JSON.parseObject(retJson, RunningData.class);if(runningData == null){//读取主节点时,主节点被释放takeMaster();}else{masterData = runningData;}} catch (Exception e1) {}}}//释放主节点private void releaseMaster() {if (checkMaster()) {try {client.delete().forPath(MASTER_PATH);} catch (Exception e) {e.printStackTrace();}}}//检验自己是否是主节点private boolean checkMaster() {try {String retJson = new String(cache.getCurrentData().getData());RunningData runningData = (RunningData) JSON.parseObject(retJson, RunningData.class);masterData = runningData;if (masterData.getName().equals(serverData.getName())) {return true;}return false;} catch (ZkNoNodeException e) {//节点不存在return false;} catch (ZkInterruptedException e) {//网络中断return checkMaster();} catch (Exception e) {//其它return false;}}public void setClient(CuratorFramework client) {this.client = client;}public CuratorFramework getClient() {return client;}
}
RunningData类:
package xyx.tuny.master;import java.io.Serializable;public class RunningData implements Serializable {private static final long serialVersionUID = 4260577459043203630L;//服务器idprivate long cid;//服务器名称private String name;public long getCid() {return cid;}public void setCid(long cid) {this.cid = cid;}public String getName() {return name;}public void setName(String name) {this.name = name;}
}
说明:在实际生产环境中,可能会由于插拔网线等导致网络短时的不稳定,也就是网络抖动。由于正式生产环境中可能server在zk上注册的信息是比较多的,而且server的数量也是比较多的,那么每一次切换主机,每台server要同步的数据量(比如要获取谁是master,当前有哪些salve等信息,具体视业务不同而定)也是比较大的。那么我们希望,这种短时间的网络抖动最好不要影响我们的系统稳定,也就是最好选出来的master还是原来的机器,那么就可以避免发现master更换后,各个salve因为要同步数据等导致的zk数据网络风暴。所以在WorkServer中,54-63行,我们抢主的时候,如果之前主机是本机,则立即抢主,否则延迟5s抢主。这样就给原来主机预留出一定时间让其在新一轮选主中占据优势,从而利于环境稳定。
测试代码:
package xyx.tuny.master;import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.ExponentialBackoffRetry;import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;/*** master选举*/
public class LeaderSelectorTest {//启动的服务个数private static final int CLIENT_QTY = 10;public static void main(String[] args) throws Exception{List<CuratorFramework> clients = new ArrayList<CuratorFramework>();List<WorkServer> workServers = new ArrayList<WorkServer>();try{for ( int i = 0; i < CLIENT_QTY; ++i ){//创建clientCuratorFramework client = CuratorFrameworkFactory.builder().connectString("127.0.0.1:2181").retryPolicy(new ExponentialBackoffRetry(1000, 3)).sessionTimeoutMs(5000).build();clients.add(client);//创建serverDataRunningData runningData = new RunningData();runningData.setCid(Long.valueOf(i));runningData.setName("Client #" + i);//创建服务WorkServer workServer = new WorkServer(runningData);workServer.setClient(client);workServers.add(workServer);workServer.start();}System.out.println("敲回车键退出!\n");new BufferedReader(new InputStreamReader(System.in)).readLine();}finally{System.out.println("Shutting down...");for ( WorkServer workServer : workServers ){try {workServer.stop();} catch (Exception e) {e.printStackTrace();}}for ( CuratorFramework client : clients ){try {client.close();} catch (Exception e) {e.printStackTrace();}}}}
}
测试:启用防抖动:

未启动防抖动:
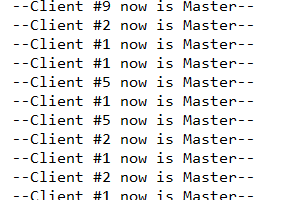
可以看到,未启用的时候,断线后重新选出的主机是随机的,没规律;启用防抖动后,每次选出的master都是id为0的机器。
三、curator recipes
Curator 也是基于这个思路,但是它将节点创建、事件监听和自动选举过程进行了封装,开发人员只需要调用简单的API即可实现Master选举。
package xyx.tuny.curator;import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.leader.LeaderSelector;
import org.apache.curator.framework.recipes.leader.LeaderSelectorListenerAdapter;
import org.apache.curator.retry.ExponentialBackoffRetry;public class Recipes_MasterSelect {static String master_path = "/curator_recipes_master_path";static CuratorFramework client = CuratorFrameworkFactory.builder().connectString("127.0.0.1:2181").retryPolicy(new ExponentialBackoffRetry(1000, 3)).build();public static void main( String[] args ) throws Exception {client.start();LeaderSelector selector = new LeaderSelector(client, master_path, new LeaderSelectorListenerAdapter() {public void takeLeadership(CuratorFramework client) throws Exception {System.out.println("成为Master角色");Thread.sleep( 3000 );System.out.println( "完成Master操作,释放Master权利" );}});selector.autoRequeue();selector.start();Thread.sleep( Integer.MAX_VALUE );}
}
Curator会在竞争到Master后自动调用该方法。开发者可以在这个方法中实现自己的业务员逻辑。需要注意的一点是,一旦执行完 takeleadership方法,Curator就会立即释放Master权力,然后重新开始新一轮的Master选举。
本例通过sleep来模拟了业务逻辑的部分,同时运行两个应用程序后,可以发现,当一个应用程序完成Master逻辑后,另一个应用程序的takeLeaderShip方法才会被调用,这就说明,当一个应用实例成为Master之后,其他应用程序实例会进入等待,直到当前Master挂了或者推出后才会开始选举新的Master。
参考:https://www.cnblogs.com/nevermorewang/p/5611807.html
https://github.com/trustnature/zookeeper_study/tree/master/src/main/java/xyx/tuny/master






