本文主要是介绍Kafka-核心架构-分区、副本(含副本选举机制),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Kafka概述
Kafka-核心架构-分区
Kafka的分区是将数据在主题(Topic)中逻辑上划分成多个片段的机制。
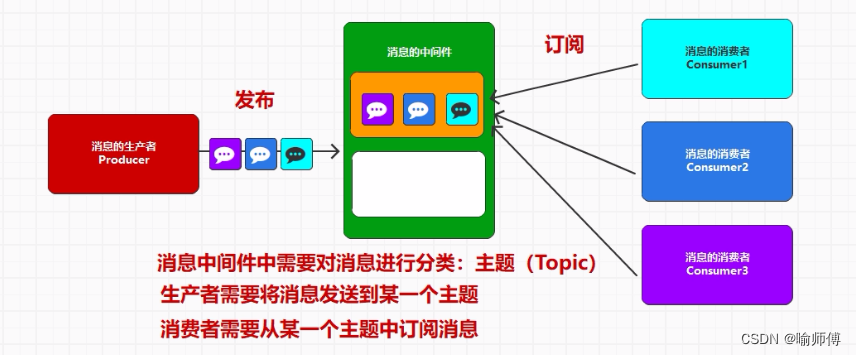
分区使得数据可以被水平扩展,提高了Kafka的可伸缩性和吞吐量,并允许数据在集群中分布和并行处理。
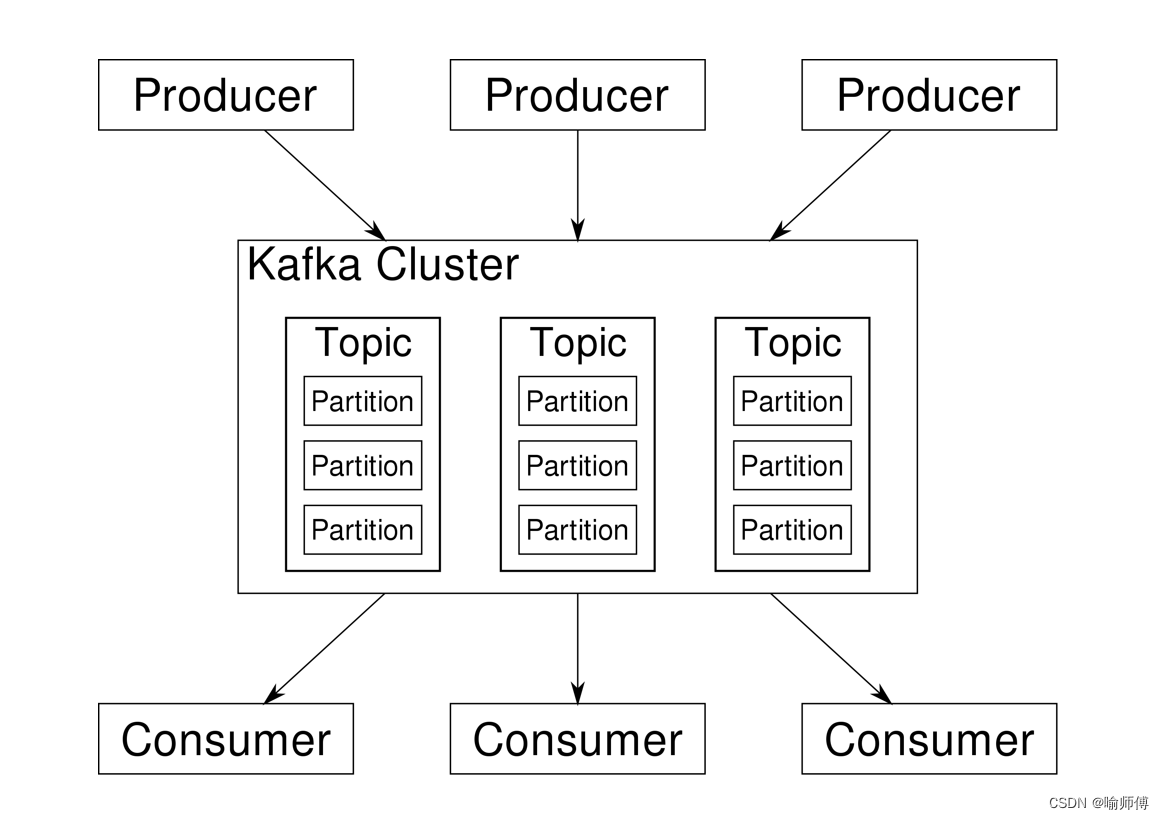
1.Kafka 分区的作用
(1)数据分布和负载均衡:
- Kafka通过将数据分割成多个分区并在集群中分布这些分区来实现数据的水平扩展和负载均衡。
- 每个分区可以在集群中的不同节点上进行复制,从而提高了容错性。
(2)并行处理:
- 每个分区在不同的消费者实例中可以并行处理,这提高了系统的吞吐量和性能。
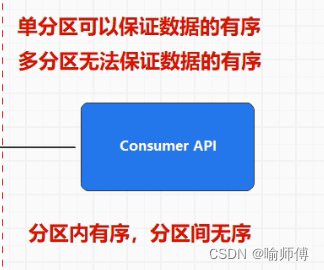
(3)顺序保证:
- Kafka保证每个分区内的消息顺序,即在同一个分区内,消息的顺序是有序的。
- 但是在不同分区之间,消息的顺序不做保证。
2.Kafka 分区的管理
(1)创建和删除:
- 可以使用kafka-topics.sh命令创建和删除主题时指定分区数量,从而创建或删除分区。
(2)动态调整:
- Kafka允许在运行时动态地调整分区数量,但这可能会影响消息的分布和顺序,需要谨慎操作。
(3)分区分配策略:
- Kafka提供了多种分区分配策略,如轮询、随机等,用于将分区分配给消费者组中的消费者,以实现负载均衡和最优分配。
(4)分区副本:
- 每个分区都有多个副本,副本的数量可以通过配置指定,副本之间会根据配置的复制策略进行数据同步,以提高数据的可靠性和持久性。
(5)分区Leader和副本:
- 每个分区都有一个
Leader副本,负责处理该分区的所有读写请求,而其他副本则作为Follower副本,从Leader副本同步数据,以实现高可用和故障转移。
Kafka-核心架构-副本
Kafka的副本(Replicas)是指在分区(Partition)级别对数据的冗余备份。每个分区可以配置多个副本,副本之间存储的是相同的数据。

1.Kafka 副本的作用
(1)数据冗余和容错性:
Kafka使用副本机制来确保数据的冗余存储和容错性。- 每个分区可以配置多个副本,这些副本分布在不同的
Broker节点上,一旦某个节点出现故障,系统可以从其他副本中继续提供服务,保证数据不丢失。
(2)提高读取性能:
- 副本可以分布在不同的节点上,允许客户端从最近的副本读取数据,这样可以降低读取延迟并提高读取吞吐量。
(3)提高写入吞吐量:
- Kafka 允许将写入请求发送给 Leader 副本,并且异步地将写入操作复制到 Followers 副本。
- 这样可以在保证数据持久性的前提下提高写入吞吐量。
(4)故障转移:
- 当 Leader 副本所在的节点发生故障时,Kafka 可以从副本中选择一个新的 Leader 副本来继续服务,从而实现故障转移,保证系统的可用性。
2.Kafka 副本的特性
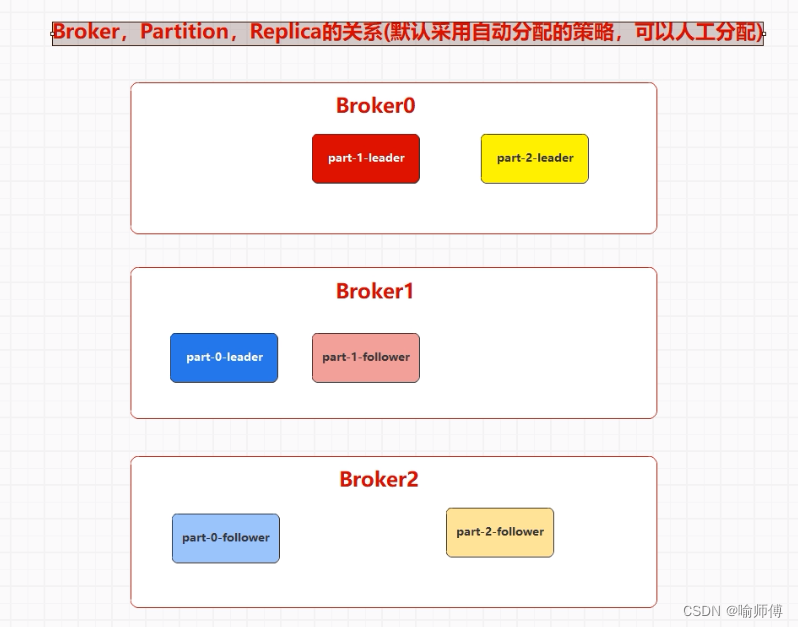
(1)Leader 和 Followers:
- 每个分区都有一个
Leader副本和零个或多个 Followers 副本。 - Leader 副本负责处理读写请求,而 Followers 副本则从 Leader 副本同步数据。
(2)数据同步:
Leader副本会将写入操作异步地复制到 Followers 副本,一般情况下,写入操作在 Leader 副本成功提交后就会被复制到 Followers 副本,从而保证数据的一致性。
(3)ISR(In-Sync Replicas):
- ISR 是指与 Leader 副本保持同步的 Followers 副本集合。
- 如果某个副本落后于 Leader 副本太多,将会被从 ISR 中移除,直到其追赶上 Leader 副本的进度。
(4)副本选举:
-
当 Leader 副本发生故障时,Kafka 集群会从 ISR 中选择一个副本作为新的 Leader 副本,以保证分区的可用性。
-
Kafka 中的副本选举是确保在领导者副本(Leader Replica)不可用时,从 ISR(In-Sync Replicas,同步副本)中选举一个新的领导者副本。
-
这个过程是自动进行的,由 Kafka 控制器负责执行。
-
下面是副本选举的一般步骤:
-
(1)领导者副本失效检测:
Kafka 集群中的每个节点都会监视分区的领导者副本的状态。如果领导者副本失效,即无法响应请求或已经停止工作,节点会检测到这一情况。 -
(2)ISR 中的副本选择: 在领导者失效后,控制器会从 ISR(同步副本集合)中选择一个副本作为新的领导者。ISR 中的副本是与领导者保持同步状态的副本,它们的数据与领导者的数据是一致的。
通常情况下,新的领导者会从 ISR 中选择。这是因为 ISR 中的副本与领导者保持同步,可以更快地接管领导者的角色,而不需要进行数据同步。 -
(3)副本选举通知:
一旦控制器选择了新的领导者副本,它会将这一信息通知给集群中的所有节点。 -
(4)选举结果确认:
所有节点接收到新领导者的选举通知后,它们会更新本地的分区信息,将新的领导者副本标记为领导者,并更新其角色状态。 -
(5)客户端重定向:
一旦新的领导者选举完成,Kafka 控制器会将分区的元数据更新到 Zookeeper(或者最新版本的 Kafka 使用自己的元数据存储),并通知客户端有关领导者副本的更改。
客户端在收到更新后,会将请求重定向到新的领导者副本,确保数据的连续性和可用性。
-
通过在 ISR 中选择一个合适的副本作为新的领导者,Kafka 能够快速地恢复分区的服务,保证系统的稳定性和可用性。
3.Kafka 副本的管理
- 副本配置:可以通过配置文件或者动态配置指定每个分区的副本数量,以满足不同的容错性和性能需求。
- 副本调整:Kafka 允许在运行时动态地调整分区的副本数量,但需要注意的是,增加副本数量可能会增加系统的负载和存储开销。
- 副本同步策略:可以配置副本之间的同步方式,包括同步和异步复制,以及复制的延迟和批量大小等参数。
- 监控和故障处理:Kafka 提供了丰富的监控工具和指标,可以用来监控副本的状态和健康情况,并及时处理副本同步延迟、故障和数据不一致等问题。
这篇关于Kafka-核心架构-分区、副本(含副本选举机制)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






