赌博机专题
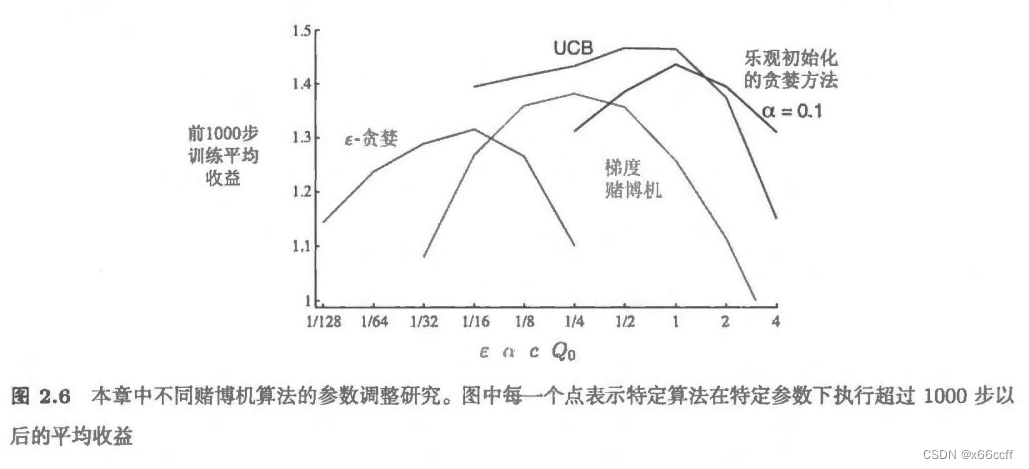
【强化学习-读书笔记】多臂赌博机 Multi-armed bandit
参考 Reinforcement Learning, Second Edition An Introduction By Richard S. Sutton and Andrew G. Barto 强化学习与监督学习 强化学习与其他机器学习方法最大的不同,就在于前者的训练信号是用来评估(而不是指导)给定动作的好坏的。 强化学习:评估性反馈 有监督学习:指导性反馈 价值函数
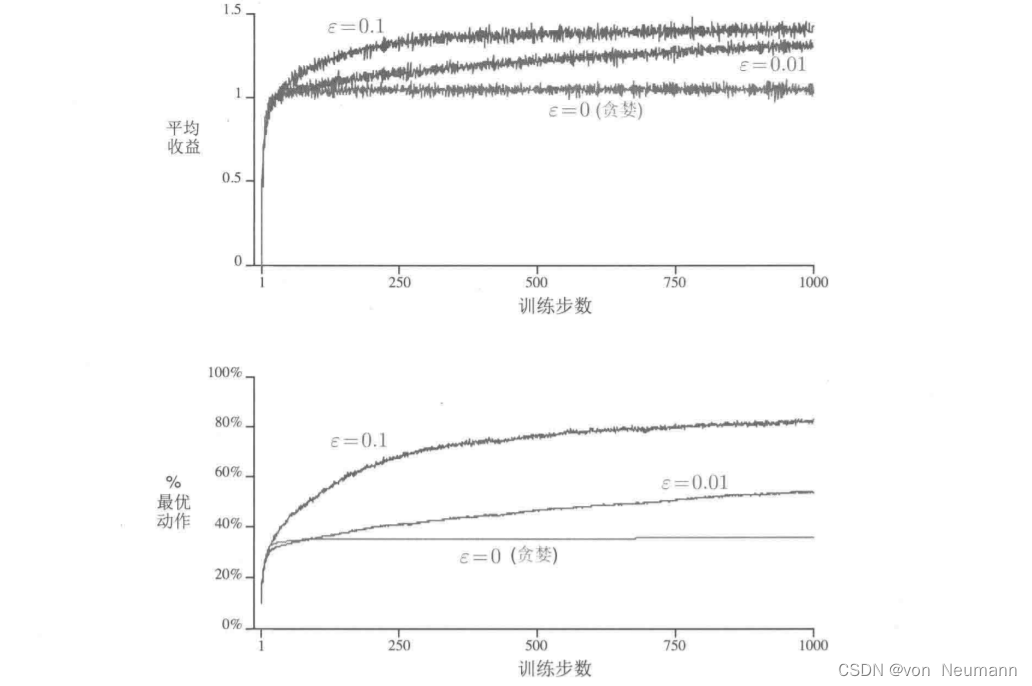
深入理解强化学习——多臂赌博机:10臂测试平台
分类目录:《深入理解强化学习》总目录 为了大致评估贪心方法和 ϵ − \epsilon- ϵ−贪心方法相对的有效性,我们将它们在一系列测试问题上进行了定量比较。这组问题是2000个随机生成的 k k k臂赌博机问题,且 k = 10 k=10 k=10。在每一个赌博机问题中,如下图显示的那样,动作的真实价值为 q ∗ ( a ) , a = 1 , 2 , ⋯ , 10 q_*(a), a=

深入理解强化学习——多臂赌博机:非平稳问题
分类目录:《深入理解强化学习》总目录 到目前为止我们讨论的取平均方法对平稳的赌博机问题是合适的,即收益的概率分布不随着时间变化的赌博机问题。但如果赌博机的收益概率是随着时间变化的,该方法就不合适。如前所述,我们经常会遇到非平稳的强化学习问题。在这种情形下,给近期的收益赋予比过去很久的收益更高的权值就是一种合理的处理方式。最流行的方法之一是使用固定步长。比如说,用于更新 n − 1 n-1 n
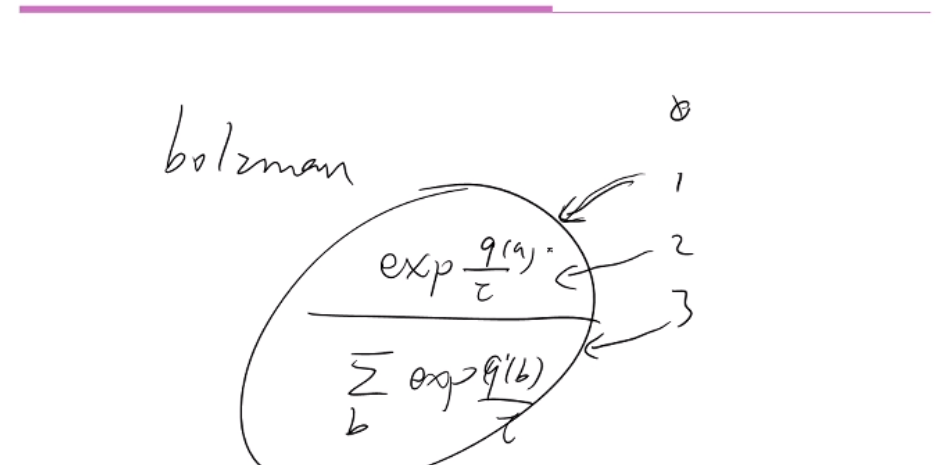
强化学习代码实战(2) --- 多臂赌博机
目录 前言 1.Python基础 2.Numpy基础 3.多臂赌博机 参考文献 前言 本文内容来自于南京大学郭宪老师在博文视点学院录制的视频,课程仅9元地址,配套书籍为深入浅出强化学习 编程实战 郭宪地址。 1.Python基础 1. print() 可以用该语句查看当前数据的情况,验证数据过程是否正确,也就是验证代码写的是否正确。 2.