词语专题

NLP-文本处理:依存句法分析(主谓、动宾、动补...)【基于“分词后得到的词语列表A”+“A进行词性标注后得到的词性列表B”来进行依存句法分析】【使用成熟的第三方工具包】
句法分析(syntactic parsing)是自然语言处理中的关键技术之一,它是对输入的文本句子进行分析以得到句子的句法结构的处理过程。对句法结构进行分析,一方面是语言理解的自身需求,句法分析是语言理解的重要一环,另一方面也为其它自然语言处理任务提供支持。例如句法驱动的统计机器翻译需要对源语言或目标语言(或者同时两种语言)进行句法分析。 第三方工具包: 哈工大LTP首页 哈工大LTP4 文档

NLP-文本处理:词性标注【使用成熟的第三方工具包:中文(哈工大LTP)、英文()】【对分词后得到的“词语列表”进行词性标注,词性标注的结果用于依存句法分析、语义角色标注】
词性: 语言中对词的一种分类方法,以语法特征为主要依据、兼顾词汇意义对词进行划分的结果, 常见的词性有14种, 如: 名词, 动词, 形容词等. 顾名思义, 词性标注(Part-Of-Speech tagging, 简称POS)就是标注出一段文本中每个词汇的词性. 举个栗子: 我爱自然语言处理==>我/rr, 爱/v, 自然语言/n, 处理/vnrr: 人称代词v: 动词n: 名词vn

ChatGPT魔法背后的原理:如何做到词语接龙式输出?
介绍 我们都知道 ChatGPT 是 AIGC 工具,其实就是生成式人工智能。大家有没有想过这些问题 🤔️: 1、我们输入一段话,就可以看见它*噼里啪啦的一顿输出*,那么它的原理到底是什么? 2、到底它是怎么锁定这些文字,然后把相应的答案输出给我们的? 当我第一次面对这些问题时,我最开始并没有多想,就觉得它很牛就对了 🐮! 带着这些疑问,我们一起开始今天的分享。 原理 在分享

30多万汉字词语押韵查询ACCESS\EXCEL数据库
押韵,也作“压韵”。作诗词曲赋等韵文时在句末或联末用同韵的字相押,称为押韵。诗歌押韵,使作品声韵和谐,便于吟诵和记忆,具有节奏和声调美。旧时押韵,要求韵部相同或相通,也有少数变格。现代新诗押韵,不受古代韵书限制。 押韵的用途很广,有闲时可以做个打油诗,有才时可以做个歌词说唱,有用时可以做个文案句,直播时也可以来个幽默串。这个数据包含3万多汉字多音字表以及34万多词语最后一字拼音,可自由使用查询。

小学1-6年级语文词语分类汇总,知识点齐全又实用
小学1-6年级语文词语分类汇总,知识点齐全又实用 作者: 添加时间:2018-11-22 小学1-6年级语文词语分类汇总,知识点齐全又实用!┃家长必读 红领巾集结号 红领巾集结号 微信号honglingjinjijiehao 功能介绍未来网红领巾集结号欢迎您!这里有亲子教育,儿童成长,生活趣闻等关于孩子们健康成长的精彩内容!红领巾集结号更是提供给全国少先队工作者、辅导员和少先队员们沟通交流、

【自然语言处理共现矩阵应用】共现矩阵用于表示文本中词语之间的共现关系
代码实现了共现矩阵的构建,共现矩阵用于表示文本中词语之间的共现关系。下面是代码实现原理的详细解释: create_co_occurrence_matrix 函数: 这个函数接受一个文本语料 corpus 和一个窗口大小 window_size。 corpus 是一个包含多个句子的列表,每个句子是一个字符串。 window_size 参数表示在一个窗口内的词语将会被认为是共现的,默认为2,意味着

笔试题-根据词典中的词语,对文本进行分词
def get_res(lexicon, data):'''第一行是一个字符串数组,表示一组词库第二行是一个文本,表示要检查的文本内容想法:想划分最长的词语问题:有一些情况无法被考虑到'''# 80 %lexicon = sorted(lexicon, key=lambda x :len(x), reverse=False)# print(lexicon)cur_data = data[:]for
爬取飞卢小说,并计算文本中词语出现的次数
'''打开开发者工具方法:F12(键盘)/fn+f12/ctrl+shift+i'''import requestsimport parselimport reimport osurl = 'https://b.faloo.com/724903.html'headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64)

词语的魔力:语言在我们生活中的艺术与影响
Words That Move Mountains: The Art and Impact of Language in Our Lives 词语的魔力:语言在我们生活中的艺术与影响 Hello there, wonderful people! Today, I’d like to gab about the magical essence of language that’s
穿越语言微妙之旅:探索词语的二重性与语言的艺术
Navigating Linguistic Nuances: Exploring the Duality of Words and the Artistry of Language 穿越语言微妙之旅:探索词语的二重性与语言的艺术 Today, we explore the enigmatic origins of the modern computer, a technological mar
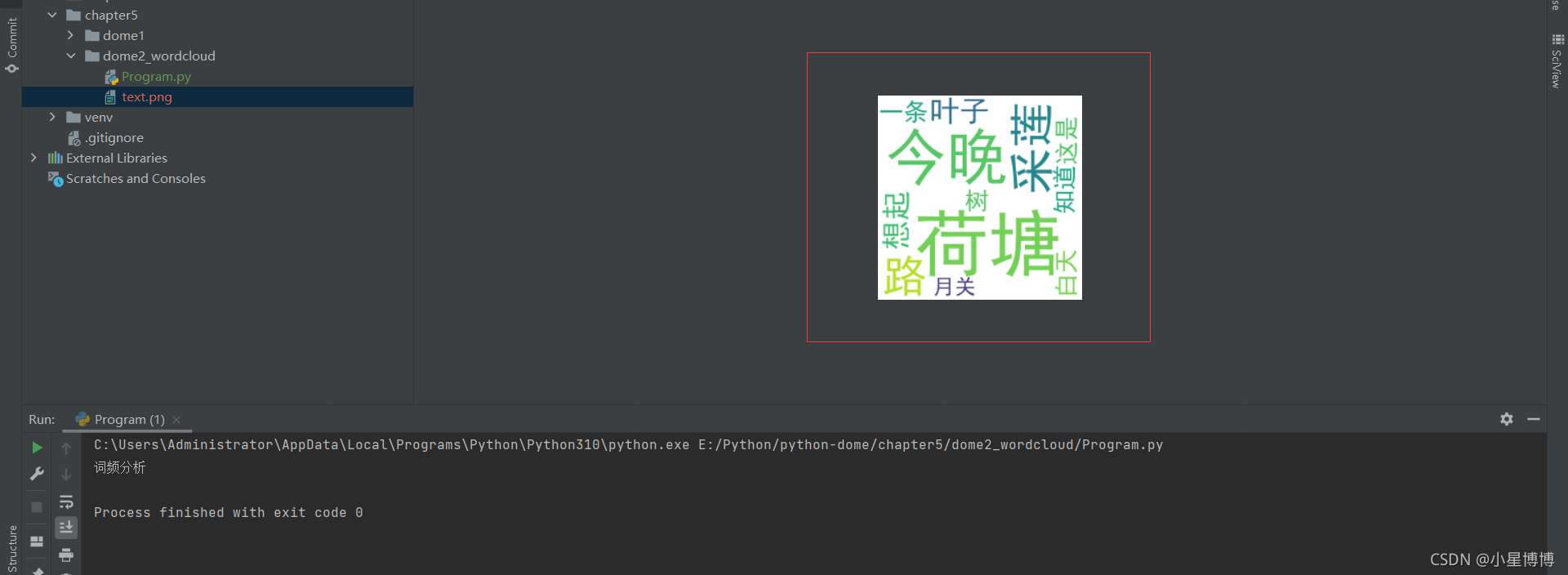
Wordcloud统计词频,与词语可视化,根据出现次数显示不同大小的词图片
1、首先还是pip安装Wordcloud 直接命令:(具体安装步骤看下面链接中的文章)https://blog.csdn.net/baidu_39105563/article/details/121429734https://blog.csdn.net/baidu_39105563/article/details/121429734https://blog.csdn.net/baidu_3910
行测备考:词语感情色彩法在逻辑填空中的用法小结(2)
有些考生会问,如何判定一个词是褒义词还是贬义词。其实很简单,现代汉语的词大多是由两个或两个以上的语素构成,其中一个语素表示词的理性义,一个语素表示词的色彩义,因此考生只要把握住表示词的色彩义的语素的感情色彩就可判断整个词的感情色彩。如“风尚”中的“尚”是表示好的意思,由它组成的词一般都是褒义词,如崇尚、高尚等。 【例2】“诗是不可译的,中国古典诗歌更是不可译的。”爱好古典诗歌的中

自然语言处理第2天:自然语言处理词语编码
☁️主页 Nowl 🔥专栏 《自然语言处理》 📑君子坐而论道,少年起而行之 文章目录 一、自然语言处理介绍二、常见的词编码方式1.one-hot介绍缺点 2.词嵌入介绍说明 三、代码演示四、结语 一、自然语言处理介绍 自然语言处理(Natural LanguageProcessing)简称NLP,与一般的机器学习任务都不相同,自然
自然语言处理第2天:自然语言处理词语编码
☁️主页 Nowl 🔥专栏 《自然语言处理》 📑君子坐而论道,少年起而行之 文章目录 一、自然语言处理介绍二、常见的词编码方式1.one-hot介绍缺点 2.词嵌入介绍说明 三、代码演示四、结语 一、自然语言处理介绍 自然语言处理(Natural LanguageProcessing)简称NLP,与一般的机器学习任务都不相同,自然
第 0012 题: 敏感词文本文件 filtered_words.txt,里面的内容 和 0011题一样,当用户输入敏感词语,则用 星号 * 替换,
import redef get_filters(path):if path is None:returnfilters = ["北京", "程序员", "公务员", "领导", "牛比", "牛逼", "你娘", "你妈", "love", "sex", "jiangge"]with open(path,encoding="utf-8") as f:line = f.read()# for l

莫烦NLP学习系列:把词语向量化
原文:莫烦NLP 计算机的理解模式 向量化思维在机器学习中也非常常见,我们可以认为,一张图片是一个向量,一篇文章是一个向量,一句话也可以是一个向量。 这样的向量化表示优点也很明显,就是能被计算机计算,是计算机能够理解的模式。 转成词向量有什么用 把这些对词语理解的向量通过特定方法组合起来,就可以有对某句话的理解了;可以在向量空间中找寻同义词,因为同义词表达的意思相近,往往在空间中距离也非常
【小程序源码】简洁UI好玩的文字转换emoji表情支持句子词语转换
这是一款好玩的文字转换emoji的一款小程序 支持自定义文字输入,支持随机切换,支持句子转换 用emoji来做暗语啥的是不是很刺激,反正至于怎么玩就看各位的脑洞了 这款小程序安装方法简单,无需服务器域名 直接使用微信开发者工具打开源码,然后上传提交审核就可以了 下面是小编的测试演示图: 小程序源码下载地址:【小程序源码】简洁UI好玩的文字转换emoji表情支持句子词语转换-小程
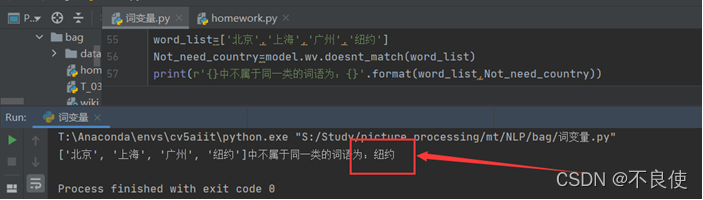
自然语言处理=======python利用word2vec实现计算词语相似度【gensim实现】
💥实验目的 🚀1、要利用已训练过的词向量模型进行词语相似度计算,实验中采用的词向量模型已事先通过训练获取的。 🚀2、于数据采用的是 2020 年特殊年份的数据,“疫情”是主要 话题。 🚀3、在计算词语之间的相似度时,采用的词语与“疫情”相关 💥实验内容 🚀1、加载已训练的词向量模型,直接调用 models.word2vec.Word2Vec.load 加载模型 wiki.
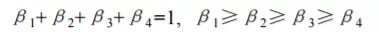
如何计算词语的相似性(附github)
前言 文本的相似性计算方法有很多,前面也讲了很多方式,下面继续讨论一种词语相似度的计算方法——基于知网的词语相似性计算。 词语语义 词语相似度也是没有一种明确的客观标准可用来衡量,相似度涉及到词语的词法、句法、语义、语用等,很难有一个统一的定义。 两类方法 词语相似度一般可分为两类方法,一种是基于 Ontology 或 Taxonomy 来计算,另外一种是基于大规模语料进行统计。 第一类方法一般
视屏消音工具,支持指定词语,或者短句静音,删除视频片段
功能说明 一个使用python开发的视频消音工具旧版:功能说明旧版:下载链接新版功能进度:新版:下载链接新版功能说明:1.视屏消音功能2.直播录制 一个使用python开发的视频消音工具 旧版:功能说明 1.支持上传文件字幕,进行视屏整段语句进行静音处理 2.支持通过指定的词语或者句子进行精确的消音处理 3.支持输入多个词语,或者断句进行消音处理 页面比较简陋,但功能应
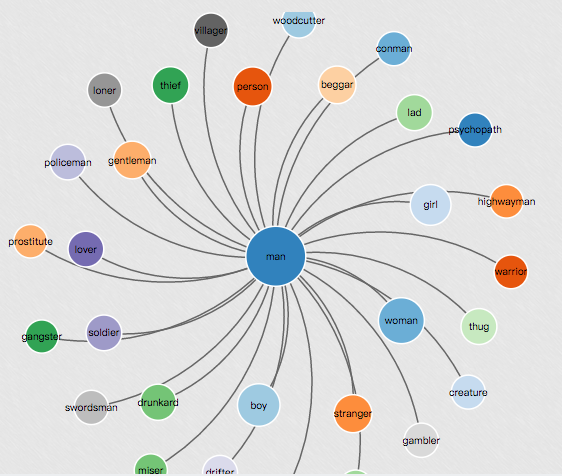
维基百科语料中的词语相似度探索
之前写过《中英文维基百科语料上的Word2Vec实验》,近期有不少同学在这篇文章下留言提问,加上最近一些工作也与Word2Vec相关,于是又做了一些功课,包括重新过了一遍Word2Vec的相关资料,试了一下gensim的相关更新接口,google了一下"wikipedia word2vec" or "维基百科 word2vec" 相关的英中文资料,发现多数还是走得这篇文章的老路,既通过gensi

知网 - 情感分析用词语集(beta版)- 情感词库
找了很久的资源,免费的东西很多人收费下载,分享一下 http://www.keenage.com/html/c_index.html 也有很多其他的情感词库,知乎推荐 https://www.zhihu.com/question/20631050/answer/23454243 ---------------------------更新:20230619--------------------
词语向量化 — word2vec简介和使用(一)
前期回顾 文本向量化 词向量介绍 一句话概括词向量用处:就是提供了一种数学化的方法,把自然语言这种符号信息转化为向量形式的数字信息。这样就把自然语言问题要转化为机器学习问题。 最常用的词向量模型无非是 one-hot Representation模型和 distributed representation 模型。 One-hot Representation One-hot R