计算速度专题

caffe2与pytorch计算速度比较
说明 caffe2 是读取的onnx模型,pytorch是加载的原始pth模型 测试结果 模型:mobilenet-v2 devicecaffe2pytorchcuda90ms8mscpu24ms10ms 附caffe2推理代码 import onnximport datetime# Load the ONNX modelmodel = onnx.load("model/mobi

神经形态计算的新方法:人造神经元计算速度超过人脑
来源:科学网 【新智元导读】一种以神经元为模型的超导计算芯片,能比人脑更高效快速地加工处理信息。近日刊登于《科学进展》的新成果,或许将成为科学家们开发先进计算设备来设计模仿生物系统的一项主要基准。尽管在其商用之前还存在许多障碍,但这项研究为更多自然机器学习软件打开了一扇大门。 当下,人工智能软件越来越多地开始模仿人类大脑。而诸如谷歌公司的自动图像分类和语言学习程序等算法也能够
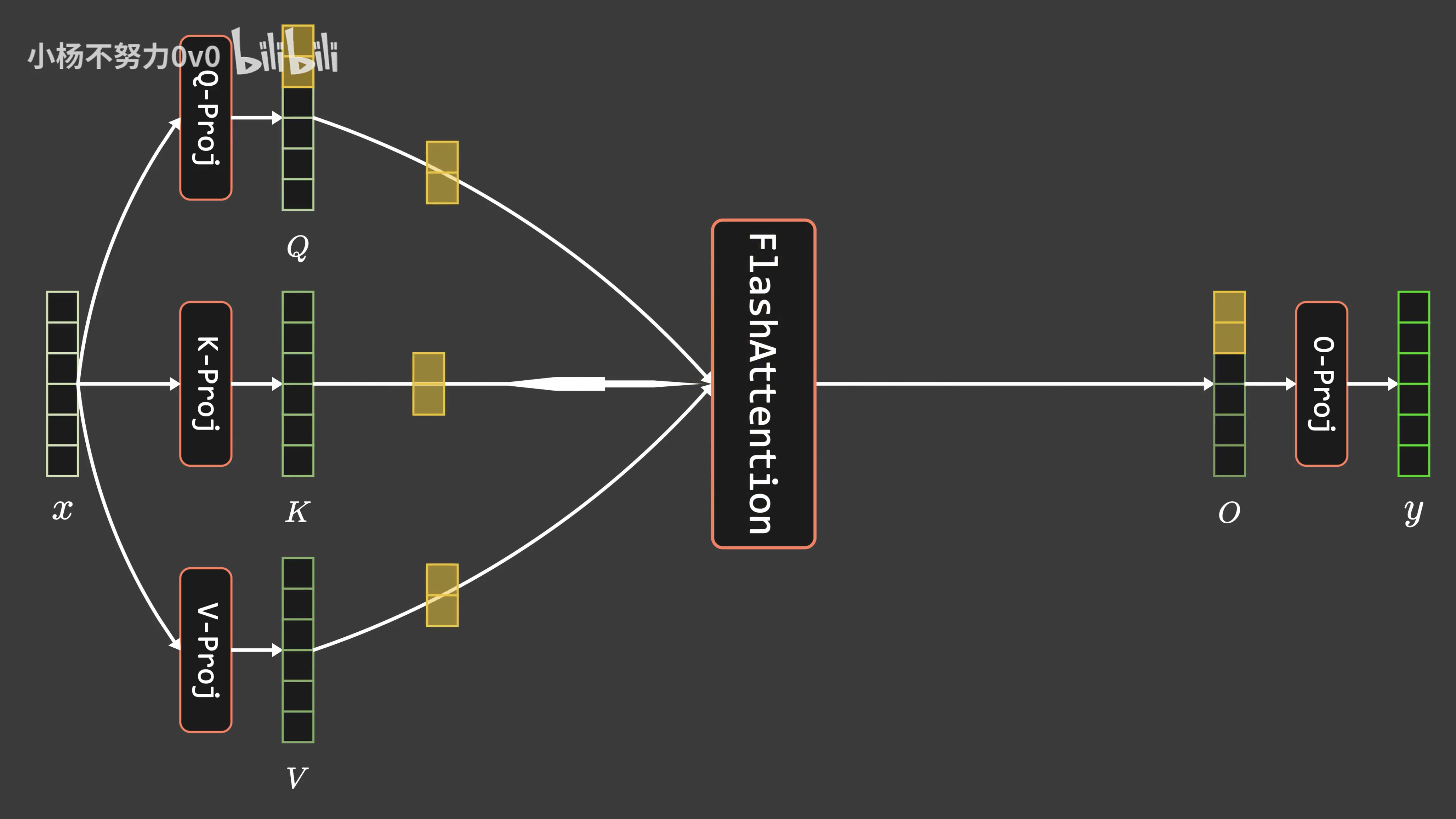
通透理解FlashAttention与FlashAttention2:全面降低显存读写、加快计算速度
前言 成就本文有两个因素 第一个因素是,我带长沙的LLM项目团队做论文审稿GPT这个项目时,遇到了不少工程方面的问题(LLM方面的项目做多了,你会逐步发现,现在模型没啥秘密 技术架构/方向选型也不是秘密,最终都是各种工程细节的不断优化),比如数据的问题,再比如大模型本身的上下文长度的问题 前者已经得到了解决,详见此文《学术论文GPT的源码解读与微调:从ChatPaper到七月论文审稿GPT第1

关于线程中的pandas计算速度问题tqdm
问题来源:Youtube2016数据处理 下面简化后复现 RuntimeError: cannot join thread before it is started 上面错误暂时不管。避免了。 从500多的bit/s的速度到下面的结果,现在速度还在降低 最后的速度可能会到40多,我想知道这是为啥子 最后用时估计会在一个小时 不用线程发现速度也是很慢,那么就是程序写的不行了。

linux超线程会拖慢vasp计算速度,VASP跑MD的问题
17 个回复 willykohn 耳朵 2008-04-16 1. 1000步太少了。 2. 初始态离平衡态太远了 【 在 abalone (纳米光学?) 的大作中提到: 】 : 想在300K下跑一个NVE : 于是先把系统在300K下跑了1000步NVT : 然后用了两种方法跑NVE : ................... abalone 纳米光学? 2008-04-16 初始态是0K

python分别使用dtw、fastdtw、tslearn、dtaidistance四个库计算dtw距离,哪个计算速度最快?
文章目录 DTW是干什么的?代码结果说明及分析比较Reference DTW是干什么的? 动态时间规整算法,故名思议,就是把两个代表同一个类型的事物的不同长度序列进行时间上的“对齐”。比如DTW最常用的地方,语音识别中,同一个字母,由不同人发音,长短肯定不一样,把声音记录下来以后,它的信号肯定是很相似的,只是在时间上不太对整齐而已。所以我们需要用一个函数拉长或者缩短其中一个信号,

浪潮M6系列服务器,浪潮发布两款M6系列四路服务器,首引Bfloat16指令集提升AI计算速度...
6月19日,全球领先的IT基础架构产品及方案提供商浪潮发布两款支持最新英特尔®第三代至强®可扩展处理器的M6系列四路服务器,包括面向云场景优化的2U4路服务器NF8260M6和面向传统企业级客户关键应用场景的4U4路服务器NF8480M6。英特尔®第三代至强®可扩展处理器面向四、八路服务器,单CPU最高可达28核,首次引入Bfloat16指令集用于增强人工智能深度学习性能,提升计算速度。同时,在
为何GPU可以用于加速人工智能或者机器学习的计算速度(并行计算能力)
一、Why GPU 其实GPU计算比CPU并不是“效果好”,而是“速度快”。 计算就是计算,数学上都是一样的,1+1用什么算都是2,CPU算神经网络也是可以的,算出来的神经网络放到实际应用中效果也很好,只不过速度会很慢罢了。 GPU的起源 GPU全称叫做graphics processing unit,图形处理器,顾名思义就是处理图形的。 电脑显示器上显示的图像,在显示在显示器上之前,要
第章光子超级计算机,中国科学家实现 “量子霸权”,计算速度比超级计算机快100万亿倍...
责编 | 陈晓雪 ●●● 中国科学技术大学潘建伟、陆朝阳团队构建的一套光量子计算系统,最近在高斯玻色采样(Gaussian Boson Sampling)问题上取得重要突破,求解速度达到目前全球最快的超级计算机的一百万亿倍,远远超过经典计算机。 这意味着中国科学家首次实现 “量子霸权”(quantum supremacy),另一个说法是量子优越性(quantum computational ad
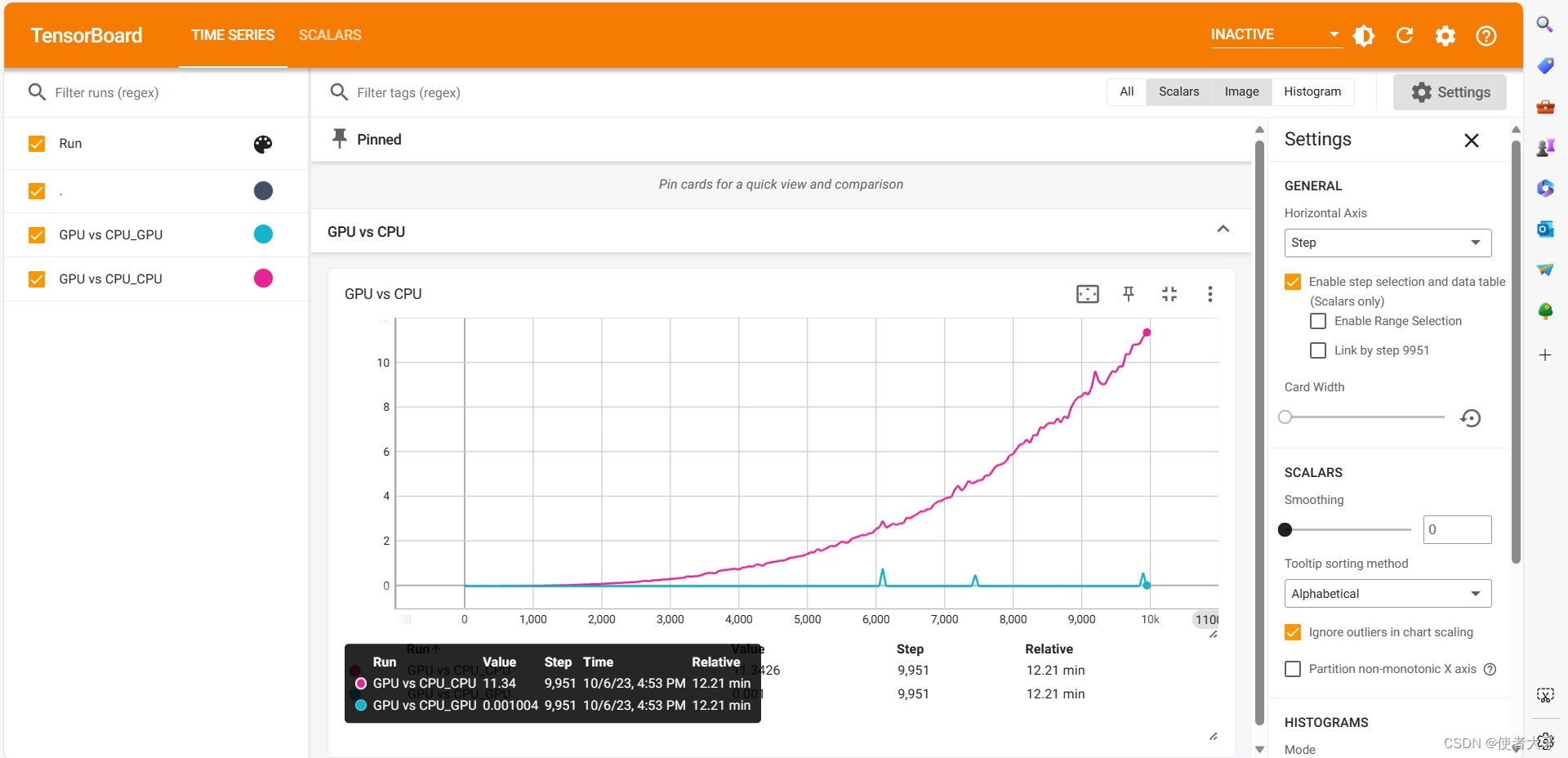
【PyTorchTensorBoard实战】GPU与CPU的计算速度对比(附代码)
0. 前言 按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。 本文基于PyTorch通过tensor点积所需要的时间来对比GPU与CPU的计算速度,并介绍tensorboard的使用方法。 我在前面的科普文章——GPU如何成为AI的加速器GPU如何成为AI的加速器_使者大牙的博客-CSD

大数据学习(9)-hadoop集群计算速度影响因素
&&大数据学习&& 🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博>主哦🤞 Hadoop集群的计算速度会受到多种因素的影响,以下是一些可能导致计算速度变化的原因: 数据量:当你处理的数据量增大时,计算时间可能会增加。这是因为更大的数据量可能需要更多的计算资源和时间来处理。集群负载:如果你的集

多体量子动力学的计算速度提高10000倍
(来源:https://iopscience.iop.org/) 一个电子在原子中的行为,或者它在固体中的运动,可以用量子力学方程式精确地预测出来,即这些理论计算与实验结果一致。但是,目前尚不能精确描述包含许多电子或基本粒子的复杂量子系统。现在,一个由凯尔大学理论物理和天体物理研究所的Michael Bonitz 教授领导的一个团队(CAU)已经开发出一种仿真方法G1-G2,该方法可以使