每组专题

Java,统计大 csv 文件中每组的数量
大 csv 文件 data.csv 超出内存,第 3 列是分组列。 Date,Time,Sub User,Access Method 10-10-2023,00:03:06,JL,cli 10-10-2023,00:02:20,TW2JL,app 10-10-2023,00:03:26,JL,cli 10-10-2023,00:03:34,JL,cli 10-10-2023,00:03:35,
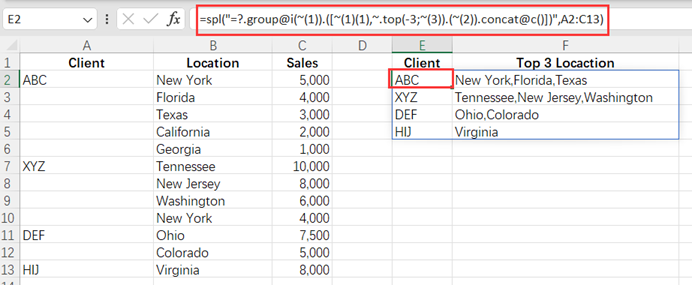
Excel 将每组的前 3 名拼成串
分组明细表如下 ABC1ClientLocationSales2ABCNew York5,0003Florida4,0004Texas3,0005California2,0006Georgia1,0007XYZTennessee10,0008New Jersey8,0009Washington6,00010New York4,00011DEFOhio7,50012Colorado5,00013H
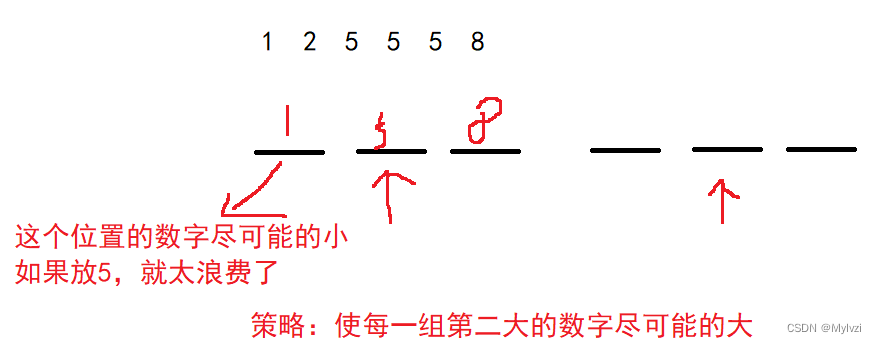
贪心算法--使每组第二大的数尽可能大
链接:组队竞赛 分析: 策略:使每一组第二大的数字尽可能的大先排序–取第二大的数字 import java.util.*;// 注意类名必须为 Main, 不要有任何 package xxx 信息public class Main {public static void main(String[] args) {Scanner in = new Scanner(System.in);i

取出分组之后每组前10条数据 oracle
--取出x || '_' || y 分组之后每组前10条数据 select * from ( select x,y,sj,ddbz, row_number() over (partition by x || '_' || y order by sj desc) rn from test

mysql 分组获取每组某字段最小或最大值记录
mysql 5.8之后分组内排序被优化忽略了;要使用就需要加上 limit -- 商品列表SELECTspu.spu_id,spu.NAME,sd.image,sd.description,sd.sku_id,sd.store_id,sd.mbr_priceFROMspu spu INNER JOIN (SELECTsku.sku_id,sku.spu_id,sku.image,sku.fi
![[华为OD] C卷 服务器cpu交换 现有两组服务器QA和B,每组有多个算力不同的CPU 100](https://img-blog.csdnimg.cn/direct/1eb87152be58441ba3aec18a40c83f7e.png)
[华为OD] C卷 服务器cpu交换 现有两组服务器QA和B,每组有多个算力不同的CPU 100
题目: 现有两组服务器QA和B,每组有多个算力不同的CPU,其中A[i]是A组第i个CPU的运算能 力,B[i]是B组第i个CPU的运算能力。一组服务器的总算力是各CPU的算力之和。 为了让两组服务器的算力相等,允许从每组各选出一个CPU进行一次交换。 求两组服务器中,用于交换的CPU的算力,并且要求从A组服务器中选出的CPU,算力尽可能 小。 输入描述 第一行输入为L1和L2,
Oracle 分组后取每组的第一条记录
根据 start_date排序 selectIsOnline,SiteCode,SiteName,StartDate,IsCheckWarningfrom(selectnvl(BL_OPEN,0) IsOnline,SITE_CODE SiteCode,SITE_NAME SiteName,START_DATE StartDate ,nvl(BL_JUDGE_WATCH,0)
字符串内有多个#号,每俩#号为一组,JavaScript 截取每组#号之间的字符
var str = "会员及家长朋友:#sys_project#中心#sys_branch#分部通知您,因#reason#原因本馆于#startyear#年#startmonth#月#startday#日—#endyear#年#endmonth#月#endday#日休假,#openmonth#月#openday#日恢复上课。给您带来的不便见谅。"; var str = str.match(/#(
关于健身运动每组次数的问题
健身需要正确的健身方法,只有掌握正确的健身方法加上不懈的坚持,才能使身体逐步强大起来。健身中,很多人因为不适合的健身方法,导致健身效果差强人意、南辕北辙。有的人目的是增肌,而锻炼的效果确是减脂塑身。 在这里,谈一下关于健身运动每组次数的问题,也就是RM的概念。 了解什么是健身RM值?请点击: http://www.yaling8.com/know/44.
C++ //练习 6.39 说明在下面的每组声明中第二条声明语句是何含义。如果有非法的声明,请指出来。
C++ Primer(第5版) 练习 6.39 练习 6.39 说明在下面的每组声明中第二条声明语句是何含义。如果有非法的声明,请指出来。 (a) int calc(int, int);int calc(const int, const int);(b) int get();double get();(c) int *reset(int *);double *reset(double *)
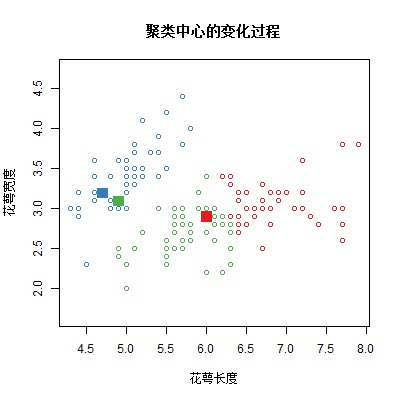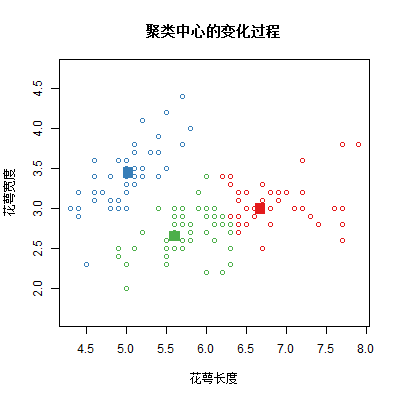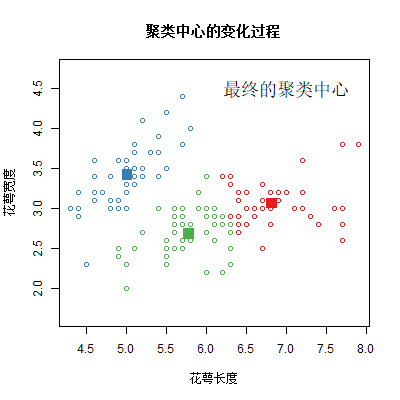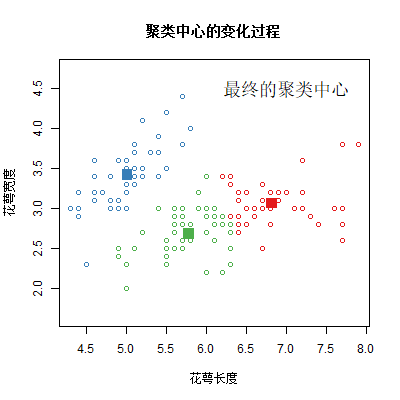
【作业】{r} :自编实现K-Means聚类算法的函数,且画出每一次迭代中每组中心点的变动情况
作业要求: 在本节中, 我们想要通过自己编写一个K-Means函数来更加深入的理解K-Means算法的流程. 并且在输出k个中心点位置和k个分组的基础上, 还想在每一次迭代中画出当前中心点的位置, 以便将这个算法动态的展示出来. ↓↓↓ 交作业点击下面链接 链接失效了 附上完整代码 (1) # 定义函数my_kmeans = function(data,
postgresql查询每组的前N条记录
方式 ROW_NUMBER() OVER (PARTITION BY "字段1","字段2..." ORDER BY 排序字段1 desc ,排序字段2 DESC) AS row_id 例如: select * from (select *,ROW_NUMBER() OVER (PARTITION BY t.src_ip, t.event_name, t.threats ) AS row_
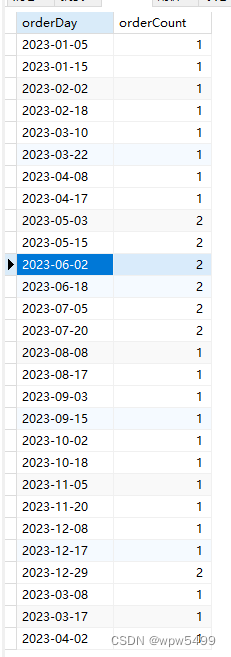
【SQL】对表中的记录通过时间维度分组,统计出每组的记录条数
场景:一般用作数据统计,比如统计一个淘宝用户在年、月、日的维度上的订单数。 业务:一个集合,以时间维度来进行分组求和。 准备一张订单表order,有一些常规属性,比如创建时间,订单号。 DDL语句如下: CREATE TABLE `order` (`order_id` INT AUTO_INCREMENT PRIMARY KEY,`order_number` VARCHAR(20) NO
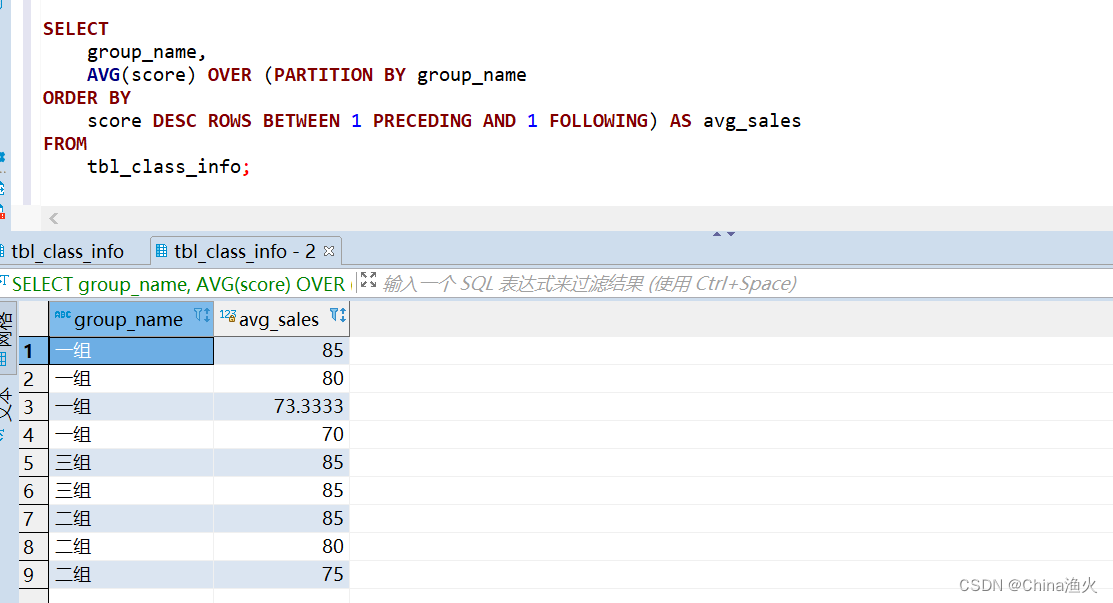
MySQL使用窗口函数ROW_NUMBER()、DENSE_RANK()查询每组第一名或每组前几名,窗口函数使用详解
MySQL数据表结构 创建 tbl_class_info 表,表中有四个字段 id、username、score、group_name 使用 ROW_NUMBER()、DENSE_RANK() 查询每组前三名 -- 查询每组前3名SELECT username, score, group_name FROM ( SELECT username, score, group_n

oracle或mysql获取分组后每组的前三条数据
文章目录 1 分组排序查询1.1 引言1.2 子查询1.2.1 方法一1.2.1.1 方法分析 1.2.2 方法二1.2.3 方法三 1.3 自定义变量1.3.1 SQL分析 1.4 窗口函数1.4.1 mysql1.4.2 oracle 1 分组排序查询 1.1 引言 排名是数据库中的一个经典题目,实际上又根据排名的具体细节可分为3种场景: 连续排名:例如薪水3000、

【Oracle】oracle sql 按某个字段分组然后从每组取出最大的一条纪录
oracle sql(按某个字段分组然后从每组取出最大的一条纪录)? 比如表 mo_partprg 字段有:listid recid 1 1 1 2 2 3 2 4 2 5 想得到的数据是 按照 listid 分组 然后取出每组中re

运动员分组比赛;有N个人参加100米短跑比赛,有8条跑道,如何分组使分组数目最少且每组人数相差最少。
#include<iostream>using namespace std;#define N 8int main(){int m;cout<<"输入人数"<<endl;cin>>m;if(m<=N){cout<<"一组"<<m<<"人"<<endl;}else if(m%8==0){cout<<"一组"<<m/8<<"人"<<endl;}else{int i=m/8+1;int j=m/
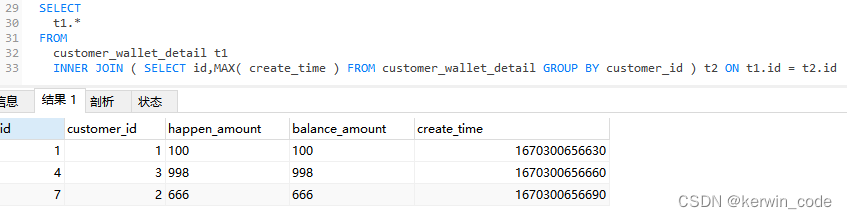
Mysql分组查询每组最新的一条数据(五种实现方法)
MySQL分组查询每组最新的一条数据 前言注意事项准备SQL错误查询错误原因 方法一方法二(适用于自增ID和创建时间排序一致)方法三(适用于自增ID和创建时间排序一致,查询性能最优)方法四(通过DISTINCT关键字打破MySQL语句优化使排序生效)方法五(以创建时间为基准获取每个用户最新的一条数据,必须要添加对应字段的索引 最好是覆盖索引)总结MAX()函数和MIN()这一类函数和GROU

vue竖线分割;分割线结尾处不显示;分割线每组最后一个不显示
实现如下图 html部分 <div class="count"> <span class="countItem" v-for="(item,index) in countList"><span>{{item.title }}:</span><span>{{item.value}}</span> <i class="line" v-if="countList.length!=index+1
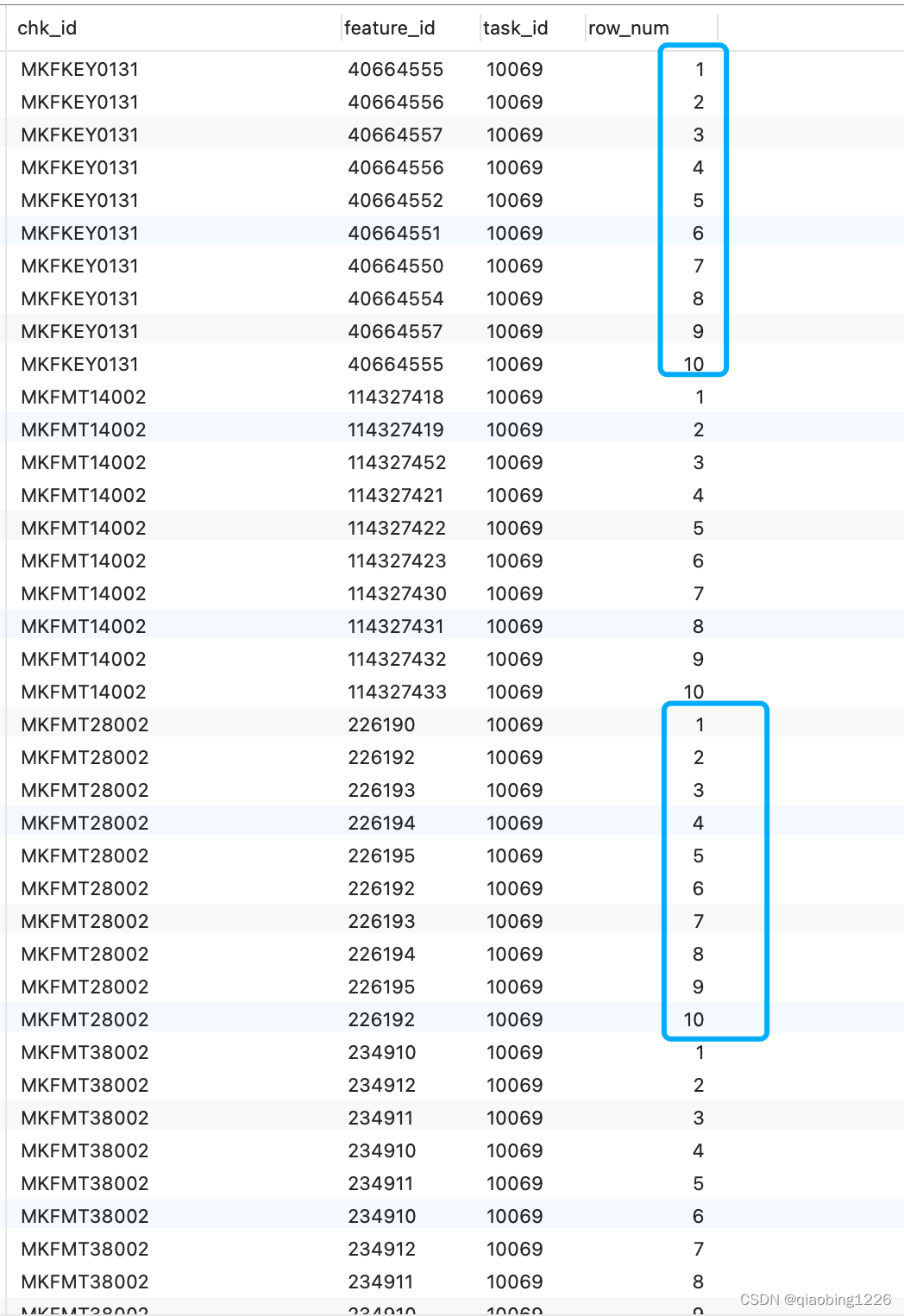
pgsql 分组查询,每组取10条
需求: 按照表的字段分组,然后每组取10条结果,返回即可 sql 如下: SELECT* FROM (SELECT chk_id,feature_id,task_id, ROW_NUMBER () OVER (PARTITION BY chk_id ORDER BY chk_id) AS row_num FROM ics_check_report WHERE task_id = '10069
分组排列,每组前几名sql
create table `shop` ( `id` int (10) PRIMARY KEY, `shop_name` varchar (100), `item_name` varchar (100), `price` int (10) ); 每个shop 中价格最高的前N 条数据 select * from shop a where
Vue 多选下拉框值每组名字的只能选一个
先普及一下,下拉框怎么实现多选 // 下拉框实现多选 select标签加一个 multiple 即可 <el-select v-model="value1" multiple placeholder="请选择"><el-optionv-for="item in options":key="item.value":label="item.label":value="item.value"></e
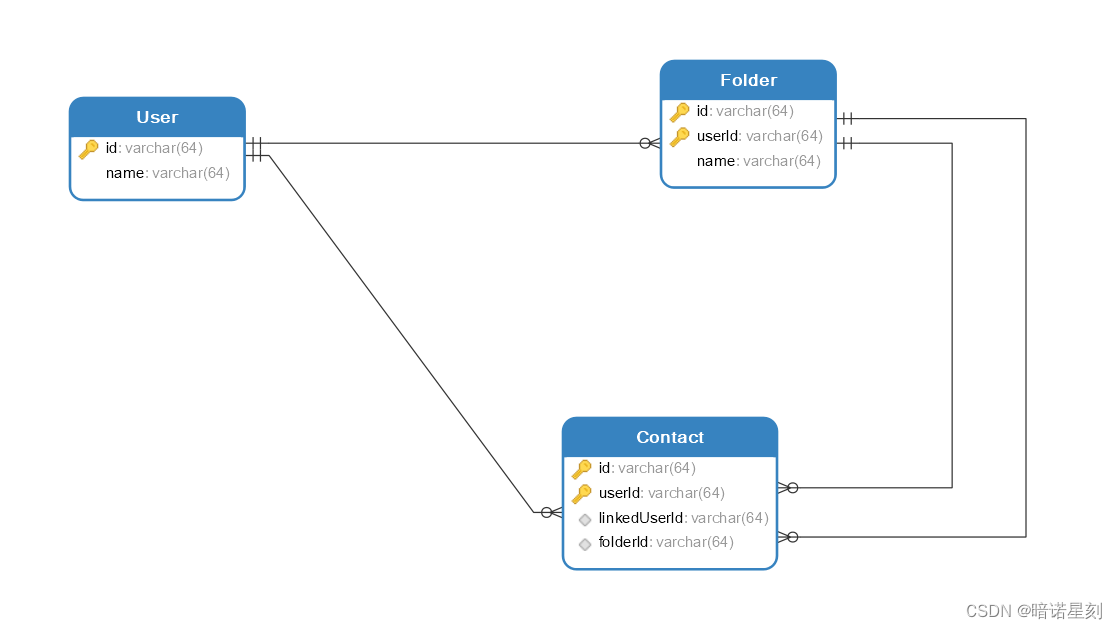
解决 MyBatis 一对多查询中,出现每组元素只有一个,总组数与元素数总数相等的问题
文章目录 问题简述场景描述问题描述问题原因解决办法 问题简述 笔者在使用 MyBatis 进行一对多查询的时候遇到一个奇怪的问题。对于笔者的一对多的查询结果,出现了这样的一个现象:原来每个组里有多个元素,查询目标是查询所查的组,以及每个组中的元素。但查询的结果却是变成了这样:每组元素变得只有一个,且总组数与元素数总数相等。举个例子,假设一共有 3 个组,每组 4 个元素。而现

v6.3.5 sequential题型 如何把N张图片分成若干组,保证每张图片在每组尽量保持一致
最近再开发一个版本,也许中间隔了一个春节,导致这版本开发,沉不下心,有点崩溃;其中有个小需求还是有必要整理复盘一下的。 #sequential 小算法 需求:P1-P6一共6张图片,100人来答题,每次随机获取3张图片进行随机排列,保证每张图片在第1位置和第2位置以及第3位置,显示的数量大概相同; 思考:数据库考虑: 代码: <?php/**@functi