正规化专题
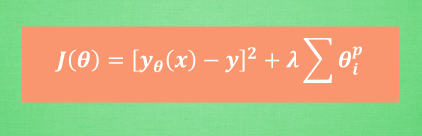
L1 / L2 正规化 (Regularization)
过拟合 我们知道, 过拟合就是所谓的模型对可见的数据过度自信, 非常完美的拟合上了这些数据, 如果具备过拟合的能力, 那么这个方程就可能是一个比较复杂的非线性方程 , 正是因为这里的 x^3 和 x^2 使得这条虚线能够被弯来弯去, 所以整个模型就会特别努力地去学习作用在 x^3 和 x^2 上的 c d 参数. 但是我们期望模型要学到的却是 这条蓝色的曲线. 因为它能更有效地概括数据.而

复习交换代数——Noether正规化
目录 简介初等启发证明过程几何意义定理应用参考资料 简介 在交换代数中有如下定理 Noether正规化引理 令$R$是一个有限生成$k$-代数整环,则存在$t_1,\ldots,t_n\in R$使得$$k\subseteq_{\textrm{纯超越}} k[t_1,\ldots,t_n]\subseteq_{\textrm{整}} R$$其中纯超越指的是$t_1,\ldots,t_n
正规化方程Normal Equations解析
如果需要代做算法,可以联系我...博客右侧有联系方式。 一、正规化方程概念 假设我们有m个样本。特征向量的维度为n。因此,可知样本为{(x(1),y(1)), (x(2),y(2)),... ..., (x(m),y(m))},其中对于每一个样本中的x(i),都有x(i)={x1(i), xn(i),... ...,xn(i)}。令 H(θ)=θ0 + θ1x1 +θ2x2 +... +

正规化和正则化的区别
“正规化”(Normalization)和"正则化"(Regularization)虽然听起来相似,但它们在机器学习和数据分析中具有不同的含义和用途。 正规化(Normalization): 正规化是一种数据处理技术,用于将不同特征的数据缩放到相似的尺度范围内,以便更好地训练和优化机器学习模型。正规化通常是将数据重新缩放到0到1的范围,或者将数据标准化为均值为0,标准差为1的分布,以便不同特征