样本量专题
ABTest如何计算最小样本量-工具篇
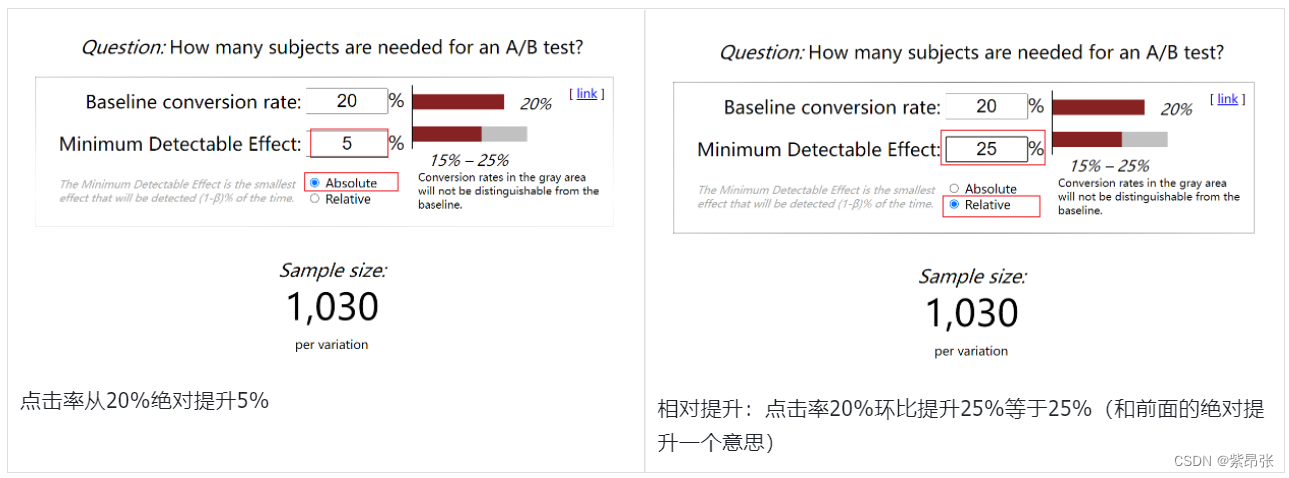
如果是比例类指标,有一个可以快速计算最小样本量的工具: https://www.evanmiller.org/ab-testing/sample-size.html 计算样本量有4个要输入的参数:①一类错误概率,②二类错误概率 (一般是取固定取值),③指标初始比例,④最小可检测效果 举个例子:如果要观测点击率20%,是否提升到25%,如何选择“绝对提升”和“相对提升”呢? 这两
python统计分析——假设概念、错误、p值和样本量
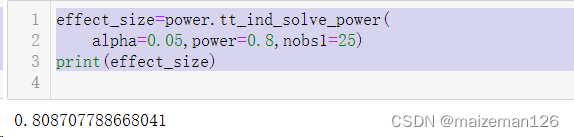
参考资料:python统计分析【托马斯】 1、例子 假设你在经营一家私立教育机构,你的合同显示:如果全国平均水平时100分时,你的学生在期末考试中得了110分,你就能获得奖金;若结果明显降低,你就会失去奖金。 学生得分数据如下:109.4,76.2,128.7,93.7,85.6,117.7,117.2,87.3,100.3,55.1 图像展示如下: # 导入库# 用于

大模型提示学习样本量有玄机,自适应调节方法好
引言:探索文本分类中的个性化示例数量 在自然语言处理(NLP)领域,预测模型已经从零开始训练演变为使用标记数据对预训练模型进行微调。这种微调的极端形式涉及到上下文学习(In-Context Learning, ICL),其中预训练生成模型的输出(冻结的解码器参数)仅通过输入字符串(称为指令或提示)的变化来控制。ICL的一个重要组成部分是在提示中使用少量标记数据实例作为示例。尽管现有工作在推理过程

来个不冷的知识,我的研究究竟需要多大的样本量?
前言 我的研究需要多大样本量?我的研究样本量已经有了,有多大概率可以得出有统计学意义的统计结果(这个样本量值得去做研究吗)?这些问题都可以通过功效分析(Power Analysis)来解决。 要进行功效分析,先要了解一下分析中涉及4个统计量:样本量(Sample Size)、效应值(Effect Size)、显著水准(Alpha)、功效(Power),知其三个可推断另外一个。 效应值是量化现

统计教程|PASS实现2x2交叉设计两均数比较时临床等效性试验的样本量估计
交叉设计(cross-over design)作为一种将自身对照和组间比较相结合的设计方法,它通过按事先设计好的试验次序(sequence),对每个受试者(subject)在整个试验的不同阶段(period)均接受不同的处理,使得相比平行组设计具有更高的试验效率,在自愈性慢性疾病、药物生物利用度和生物等效性研究方面广泛运用。 等效性检验是临床试验中评价新药疗效常用的一种方法。新药临床试验中,常采

统计教程|PASS实现单因素二元Logistic回归分析且自变量为二分类的优势比检验的样本量估计
在对临床数据的探索分析工作中,我们经常会使用Logistic回归分析去探索影响疾病的发生、发展的重要影响因素,或应用Logistic回归模型进行相关的预测分析。但是在进行Logistic回归分析时,样本含量的估计常常是令临床科研工作者最头痛的一件事了。常常纠结选哪些作为自变量或选多少个合适,因为大家通常采取的办法是选取研究中拟纳入的协变量个数的10~15倍(也有教科书上指出:经验上病例和对照的人数