文本检索专题

机器学习-11-基于多模态特征融合的图像文本检索
总结 本系列是机器学习课程的系列课程,主要介绍机器学习中图像文本检索技术。此技术把自然语言处理和图像处理进行了融合。 参考 2024年(第12届)“泰迪杯”数据挖掘挑战赛 图像特征提取(VGG和Resnet特征提取卷积过程详解) 2024 年(第 12 届)“泰迪杯”数据挖掘挑战赛——B 题:基于多模态特征融合的图像文本检索完整思路与源代码分享 【2024泰迪杯】B 题:基于多模态特征


论文:Term-Weighting Approaches in Automatic Text Retrieval翻译笔记(自动文本检索中的术语加权方法)
文章目录 论文标题:自动文本检索中的术语加权方法摘要1. 自动文本分析2. 词权重规范3. 术语加权实验4 推荐4.1 查询向量4.2 文档向量 论文标题:自动文本检索中的术语加权方法 论文链接:https://www.cs.colostate.edu/~howe/cs640/papers/salton_termWeighting.pdf 在自动文本检索中,术语加权

【2024第十二届“泰迪杯”数据挖掘挑战赛】B题基于多模态特征融合的图像文本检索—解题全流程(持续更新)
2024 年(第 12 届)“泰迪杯”数据挖掘挑战赛B题 解题全流程(持续更新) -----基于多模态特征融合的图像文本检索 一、写在前面: 本题的全部资料打包为“全家桶”, “全家桶”包含:数据、代码、模型、结果csv、教程、详细实验过程PPT、教学视频、论文借鉴大纲构思达到“以赛促学”的目的,从0到1,从环境配置开始,到模型构建、数据准备、模型训练、模型recall_TOP1、5、1

【大模型系列】根据文本检索目标(DINO/DINOv2/GroundingDINO)
文章目录 1 DINO(ICCV2021, Meta)1.1 数据增强1.2 损失函数 2 DINOv2(CVPR2023, Meta)2.1 数据采集方式2.2 训练方法 3 Grounding DINO3.1 Grounding DINO设计思路3.2 网络结构3.2.1 Feature Extraction and Enhancer3.2.2 Language-Guided Query

Mongodb 文本检索
Mongodb支持对字符串字段的文本检索。在Mongodb atlas中, 对这种文本检索的功能进行了增强。 提到文本检索, 难免不会想到实现非常火爆的AI, 聊天服务等时髦技术。mongodb提供的这种文本检索功能+适当的算法实践,似乎可以支持这些应用场景。 本文研究Mongodb文本检索文档,整理出在本地Mongo数据库中使用文本检索的方法和注意事项。 文本检索 执行文本检索前,用户需要

【腾讯云云上实验室】用向量数据库——实现高效文本检索功能
文章目录 前言Tencent Cloud VectorDB 简介Tencent Cloud VectorDB 使用实战申请腾讯云向量数据库腾讯云向量数据库使用步骤腾讯云向量数据库实现文本检索 结论和建议 前言 想必各位开发者一定使用过关系型数据库MySQL去存储我们的项目的数据,也有部分人使用过非关系型数据库Redis去存储我们的一些热点数据作为缓存,提高我们系统的响应速度,
【腾讯云云上实验室】用向量数据库——实现高效文本检索功能
文章目录 前言Tencent Cloud VectorDB 简介Tencent Cloud VectorDB 使用实战申请腾讯云向量数据库腾讯云向量数据库使用步骤腾讯云向量数据库实现文本检索 结论和建议 前言 想必各位开发者一定使用过关系型数据库MySQL去存储我们的项目的数据,也有部分人使用过非关系型数据库Redis去存储我们的一些热点数据作为缓存,提高我们系统的响应速度,

PostgreSQL 相似文本检索与去重 - (银屑病怎么治?银屑病怎么治疗?银屑病怎么治疗好?银屑病怎么能治疗好?)...
标签 PostgreSQL , 相似字符串 , 全文检索 , 去重 , 相似问题 , 医疗 , plr , plpython , madlib , 文本处理 背景 在云栖社区的问答区,有一位网友提到有一个问题: 表里相似数据太多,想删除相似度高的数据,有什么办法能实现吗? 例如: 银屑病怎么治? 银屑病怎么治疗? 银屑病怎么治疗好? 银屑病怎么能治疗好? 等等
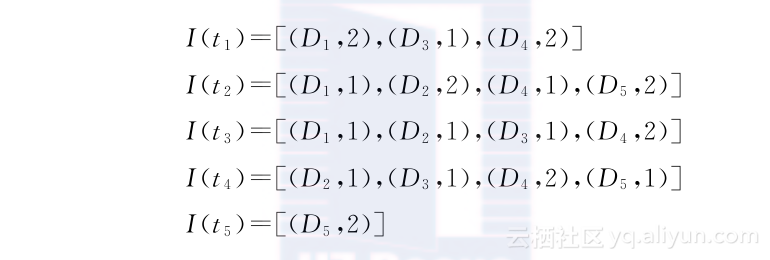
《大规模元搜索引擎技(1)》一1.2 文本检索概述
本节书摘来自华章出版社《大规模元搜索引擎技(1)》一书中的第1章,第1.2节,作者[美]孟卫一(Weiyi Meng)纽约州立大学宾汉姆顿分校於德(Clement T.Yu)伊利诺伊大学芝加哥分校,更多章节内容可以访问云栖社区“华章计算机”公众号查看 1.2 文本检索概述 对于给定的查询,文本(信息)检索解决从文本文档的集合中查找相关(有用)文档的问题。文本检索技术对Web搜索引擎有深刻而直接的