本文主要是介绍【腾讯云云上实验室】用向量数据库——实现高效文本检索功能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- Tencent Cloud VectorDB 简介
- Tencent Cloud VectorDB 使用实战
- 申请腾讯云向量数据库
- 腾讯云向量数据库使用步骤
- 腾讯云向量数据库实现文本检索
- 结论和建议
前言
想必各位开发者一定使用过关系型数据库MySQL去存储我们的项目的数据,也有部分人使用过非关系型数据库Redis去存储我们的一些热点数据作为缓存,提高我们系统的响应速度,减小我们MySQL的压力。那么你有听说过向量数据库吗?知道向量数据库是用来做什么的吗?
向量数据库用来存储非结构化数据,例如,文档,图片,视频,音频和纯文本等,在保证1%信息完整的情况下,通过向量嵌入函数来精准描写非结构化数据的特征,从而提供查询、删除、修改、元数据过滤等操作。而像Mysql这样传统的数据库根本无法完成这些操作。而腾讯云向量数据库(Tencent Cloud VectorDB) 是一款专为存储、检索和分析多维向量数据而设计的全托管式企业级分布式数据库服务,就让我们一起来学习一起吧!
Tencent Cloud VectorDB 简介
向量数据库是一种创新性的数据存储系统,其独特之处在于采用高维向量来表示数据的特征或属性。这些高维向量的维度数量范围广泛,从几十到几千,具体取决于数据的复杂性和细致程度。与此同时,该数据库集成了CRUD操作、元数据过滤和水平扩展等多项功能。这些向量通常是通过对原始数据(例如文本、图像、音频、视频等)应用某种变换或嵌入函数来生成的。这些嵌入函数可能基于各种方法,包括机器学习模型、词嵌入和特征提取算法等。
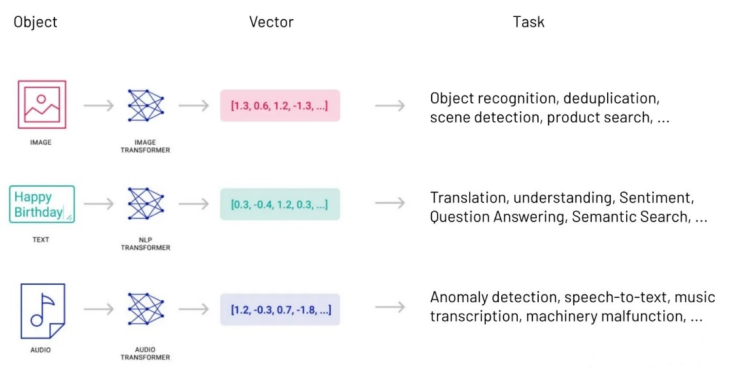
向量数据库利用嵌入模型将数据转化为高维向量后,这些向量被存储在数据库中。在用户进行查询时,系统将用户提出的问题转换成高维向量,通过在数据库中计算高维空间中两个向量的距离,迅速检索出最相似的向量,并将相应的数据返回给用户。
向量数据库的显著优势在于其能够通过向量距离或相似性进行快速、准确的相似性搜索和检索。这使得用户能够根据语义或上下文含义查找最相关的数据,而不受传统数据库中基于精确匹配或预定义标准的限制。
该数据库将向量嵌入巧妙地整合在一起,使得我们能够比较任何向量与搜索查询的向量或其他向量之间的相似度。同时,它还支持CRUD操作和元数据过滤。通过将传统数据库功能与搜索和比较向量的能力相结合,向量数据库成为一个极具威力的工具。其在相似性搜索方面表现出色,通常被称为“向量搜索”技术。
腾讯云向量数据库(Tencent Cloud VectorDB) 是一款专为存储、检索和分析多维向量数据而设计的全托管式企业级分布式数据库服务。其独特之处在于支持多种索引类型和相似度计算方法,拥有卓越的性能优势,包括高QPS(每秒查询率)、毫秒级查询延迟,以及单索引支持数亿级向量数据规模。通过简单易用的可视化界面,用户可以快速创建数据库实例,进行数据操作,执行查询操作,并配置嵌入式数据转换,提供更广泛的数据处理能力。该数据库适用于多种场景,如构建大型知识库、推荐系统、智能问答系统以及文本/图像检索任务,为企业提供了强大的工具,助力各种应用场景下的高效数据管理和智能应用实现。

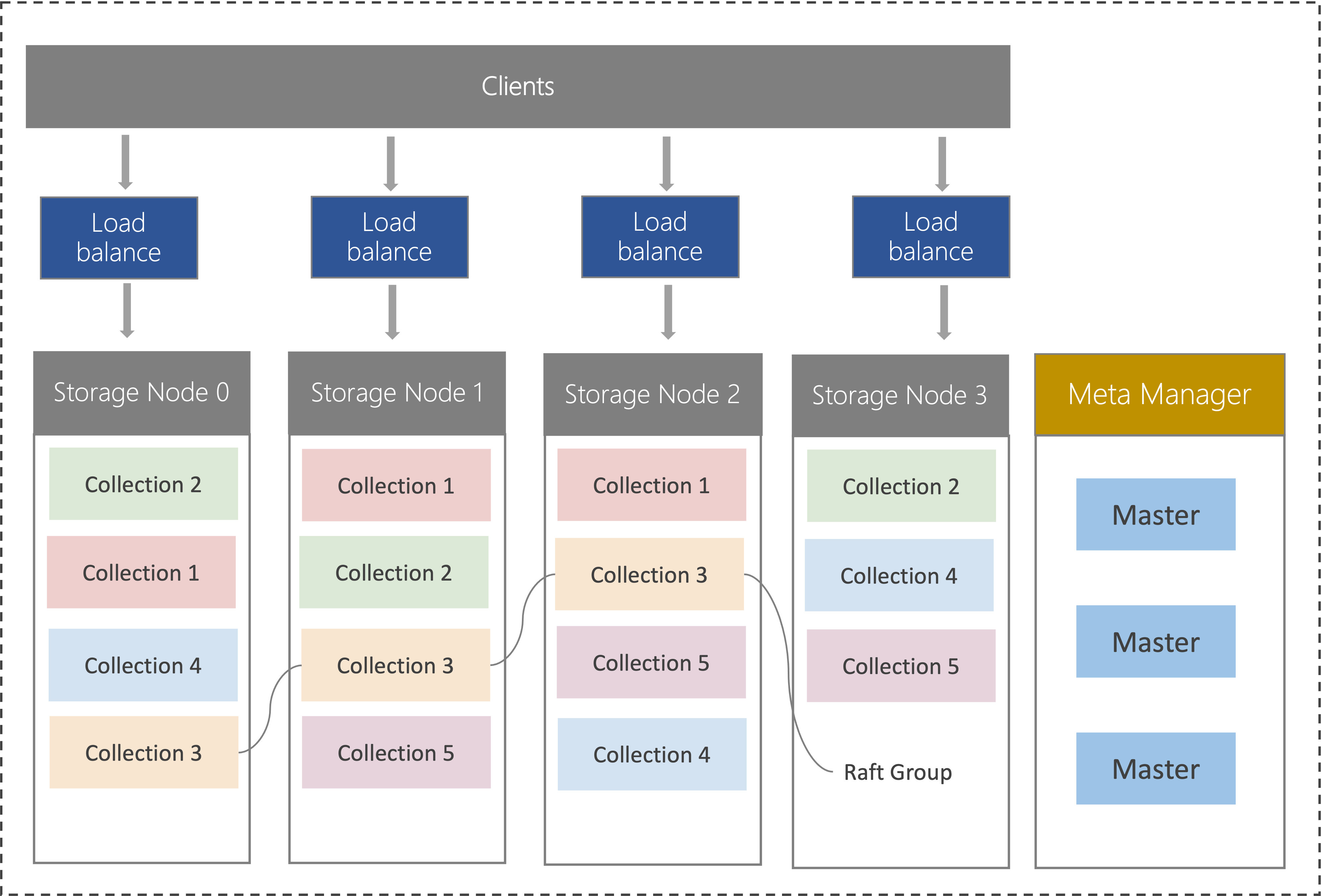
腾讯云向量数据库 Tencent Cloud VectorDB 基于腾讯集团每日处理千亿次检索的向量引擎 OLAMA,底层采用 Raft 分布式存储,通过 Master 节点进行集群管理和调度,实现系统的高效运行。同时,腾讯云向量数据库支持设置多分片和多副本,进一步提升了负载均衡能力,使得向量数据库能够在处理海量向量数据的同时,实现高性能、高可扩展性和高容灾能力。
Tencent Cloud VectorDB 使用实战
申请腾讯云向量数据库
点击下面的链接或者腾讯云搜索向量数据库,可用微信进行扫码实名认证登录,腾讯云向量数据库免费实例领取链接:点击申请

以上我们就申请好了腾讯云向量数据库,然后我们可以进行一些实操。
腾讯云向量数据库使用步骤
领取资源后可创建一个向量数据库,点击新建
默认没有网络和安全组,请点击新建私用网络和自定义安全组进行新建
下面是创建私有网络
下面是创建安全组
创建向量数据库后需要开启外网访问才可登录并远程控制
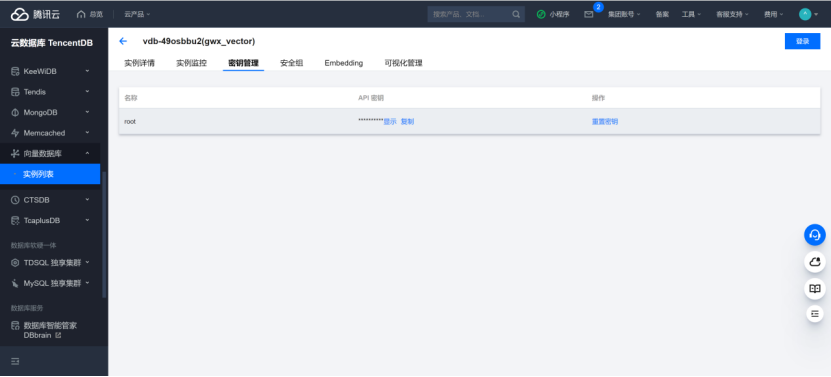
账号名为root 密码为向量数据库实例中复制API 密钥
点击新建数据库
有两种模式:一种是不开启embedding ,一种是开启embedding
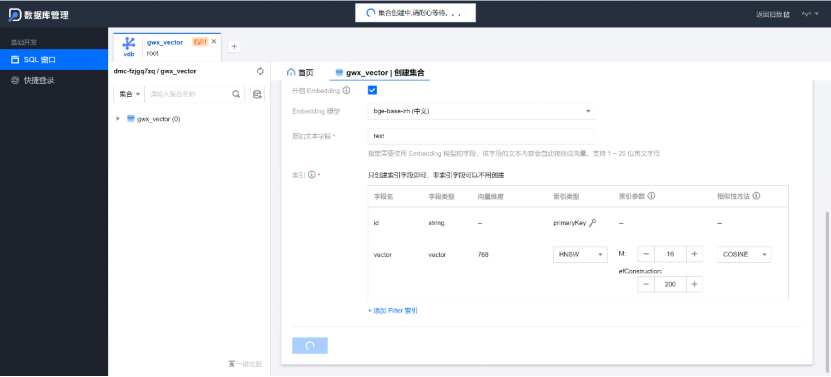
创建了两个数据库一个时一种是开启embedding ,一种是不开启embedding,分别是test_1和test_2 表
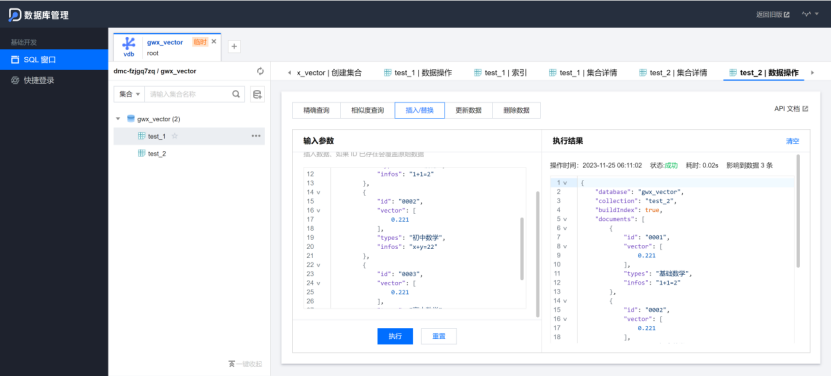
{"database": "gwx_vector","collection": "test_1","buildIndex": true,"documents": [
{"id": "0001","types": "基础数学","infos": "1+1=2","text":"小学生数学课程"},{"id": "0002","types": "初中数学","infos": "x+y=22","text":"初中生学习课程"},{"id": "0003","types": "高中数学","infos": "f(x)","text":"高中生学习课程"}]
}
将上面的代码分别放入test_1进行数据操作然后执行,可在精准查询和相似度查询对向量数据库里面的数据进行检索
腾讯云向量数据库实现文本检索
文本检索任务是指在大规模文本数据库中搜索出与指定图像最相似的结果,在检索时使用到的文本特征可以存储在向量数据库中,通过高性能的索引存储实现高效的相似度计算,进而返回和检索内容相匹配的文本结果。
如果想用IDE 通腾讯向量数据库进行开发则可通过python 或java 开发,下面用python 进行演示
环境依赖安装:
pip install tcvectordb
或者通过 https://github.com/Tencent/vectordatabase-sdk-python 链接源码安装
首先在腾讯云上面购买向量数据库服务器后,在本地创建VectorDBClient,一个向量数据库的客户端对象,用于与向量数据库服务器连接并进行数据交互。
具体代码如下:
import tcvectordb
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency#create a database client object
client = tcvectordb.VectorDBClient(url='http://10.0.X.X', username='root', key='eC4bLRy2va******************************', read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
然后创建数据库,并查询集群中所有的向量数据库。
read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
# 创建数据库
client.create_database('db-test')
client.create_database('db_test0')
client.create_database('db_test1')
# list databases
db_list = client.list_databases()for db in db_list:print(db.database_name)
下面写入原始文本数据:
import tcvectordb
from tcvectordb.model.collection import Embedding, UpdateQuery
from tcvectordb.model.document import Document, Filter, SearchParams
from tcvectordb.model.enum import FieldType, IndexType, MetricType, EmbeddingModel
from tcvectordb.model.index import Index, VectorIndex, FilterIndex, HNSWParams, IVFFLATParams
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency
#create a database client object
client = tcvectordb.VectorDBClient(url='http://10.0.X.X', username='root', key='eC4bLRy2va******************************', read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
# 指定写入原始文本的数据库与集合
db = client.database('db-test')
coll = db.collection('book-emb')
# 写入数据。
# 参数 build_index 为 True,指写入数据同时重新创建索引。
res = coll.upsert(
documents=[
Document(id='0001', text="话说天下大势,分久必合,合久必分。", author='罗贯中', bookName='三国演义', page=21),
Document(id='0002', text="混沌未分天地乱,茫茫渺渺无人间。", author='吴承恩', bookName='西游记', page=22),
Document(id='0003', text="甄士隐梦幻识通灵,贾雨村风尘怀闺秀。", author='曹雪芹', bookName='红楼梦', page=23)
],
build_index=True
)
下面进行查询
1、基于精确匹配的查询方式:query() 用于精确查找与查询条件完全匹配的向量,具体支持如下功能。
支持根据主键 id(Document ID),搭配自定义的标量字段的 Filter 表达式一并检索。
支持指定查询起始位置 offset 和返回数量 limit,实现数据 SCAN 能力。
#create a database client object
client = tcvectordb.VectorDBClient(url='http://10.0.X.X', username='root', key='eC4bLRy2va******************************', read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
db = client.database('db-test')
coll = db.collection('book-vector')
# Set filter
filter_param=Filter(Filter.In("bookName",["三国演义", "西游记"]))
# query
doc_list = coll.query(document_ids=['0001','0002','0003'], retrieve_vector=True, filter=filter_param, limit=3, offset=0, output_fields=['bookName','author'])
for doc in doc_list:
print(doc)
2、基于相似度匹配的查询方式:search()接口用于查找与给定查询向量相似的文档,返回指定的 Top K 个最相似的文档,并支持搭配自定义的标量字段的 Filter 表达式一并进行相似度检索。
doc_lists = coll.search(
vectors=[[0.3123, 0.43, 0.213],[0.315, 0.4, 0.216],[0.40, 0.38, 0.26]],
filter=Filter(Filter.In("bookName",["三国演义", "西游记"])),
params=SearchParams(ef=200),
retrieve_vector=True,
limit=3,
output_fields=['bookName','author']
)
for i, docs in enumerate(doc_lists):
print(i)
for doc in docs:
print(doc)
更新数据代码如下
#create a database client object
client = tcvectordb.VectorDBClient(url='http://10.0.X.X', username='root', key='eC4bLRy2va******************************', read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
# 指定需更新文档所属的数据库
db = client.database('db-test')
# 指定集合
coll = db.collection('book-vector')
#设置需更新的字段,或增加新的字段
update_doc = Document(vector=[0.2123, 0.290, 0.213], page=30, test_new_field="new field value")
# 对满足查询条件的 Document 更新字段
coll.update(data=update_doc, document_ids=['0001','0002','0003'], filter=Filter(Filter.In("bookName",["三国演义", "西游记"])))
# 更新之后,确认字段已更新
doc_list = coll.query(document_ids=['0001','0002'], retrieve_vector=True, limit=3)
# 输出确认结果
for doc in doc_list:
print(doc)
注意:
1、VectorDBClient 中的 url 和 key 填写成自己申请的向量数据库的哦(key就是秘钥)
2、read_consistency :设置读一致性,是非必填参数,默认取值EVENTUAL_CONSISTENCY,可取值如下:
- ReadConsistency.STRONG_CONSISTENCY:强一致性。
- ReadConsistency.EVENTUAL_CONSISTENCY:最终一致性。
结论和建议
整体使用腾讯云向量数据下来,我觉得腾讯数据库是一个非常棒的产品,即使你是一个小白,你也可以很快的入手,因为它的文档 产品文档 是非常详细的
它能够带你快速入门,文档基本覆盖了你所有可能遇到的问题,而且在实战使用过程中它的速度也是非常快的,完全可以满足企业的要求,有这方面需要的伙伴可以快速入手了。
选择一款合适的向量数据库是一件非常重要的事,不仅要考虑成本而且还要考虑效率等方面,腾讯云向量数据库用于大模型预训练数据的分类、去重和清洗相比传统方式可以实现10倍效率的提升,如果将腾讯云向量数据库作为外部知识库用于模型推理,则可以将成本降低2-4个数量级。所以我觉得不管是个人还是企业腾讯云向量数据库都是我们的第一选择。比如企业原先接入一个大模型需要花1个月左右时间,使用腾讯云向量数据库后,3天时间即可完成,极大降低了企业的接入成本。
目前腾讯云向量数据库只支持文本向量化写入,但对图片这些非结构化数据暂时不支持,浅浅的期待一波,等上线后,俺第一个使用。

这篇关于【腾讯云云上实验室】用向量数据库——实现高效文本检索功能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






