本文主要是介绍文本检索粗读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一.前情提要
1.本文理论为主,并且仅为个人理解,能力一般,不喜勿喷
2.本文理论知识较为散碎
3.如有需要,以下是原文,更为完备
Neural Corpus Indexer 文档检索【论文精读·47】_哔哩哔哩_bilibili
二.正文
(本文争议较大,因为作者在实验的时候把测试集和训练集搞混了一部分造成实验数据精度很高)
1.通过端到端的神经网络,把训练和检索放到一起,能有效提高召回率。本文提出NCI的方法,这是一种基于sequence到sequence的网络,能直接针对特定文档返回ID
2.检索常用具体方法
①将查询和文档组成一对,再去计算相关性(最大的缺点就是价格昂贵),在你搜索某个单词,比如torch的时候,torch,这个单词是一串数字,它会遍历整个文件,找到符合条件的返回出来的就是torch,而不是数字
②有一种方法是基于语义的,会把document query映射为一个向量,这是一个embedding层
③本项目使用two tower来进行学习,如下图
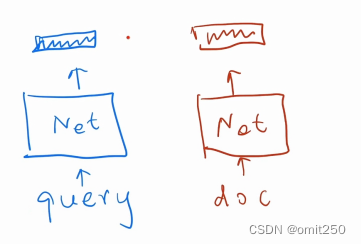
(该图最上方长方形框是对query和document都抽象出一个特点)
(但是这仍然具有缺点,缺点是单一向量的话,它会出现相错误的结果,比如苹果14和苹果13在搜索上是一样的)
④使用了ANN搜索,若为复杂搜索则不适用
具体算法简化如下:
将文本和ID对成一对,让神经网络记忆。并且query和doc会关联
⑤整体流程

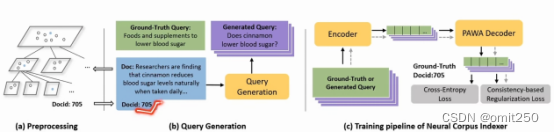
正上方该框代表组合后进入encoder
⑥层次来源
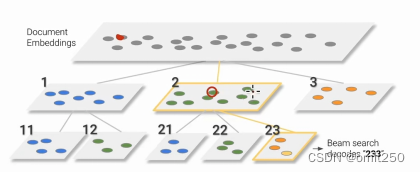
先整体k-mens聚类分为1,2,3,然后再提取关键特征,如图所示,11 12前面那个1就是关键特征,简而言之,就是先大分类,再不断小分类(并且因为是随机采样,所以多样性会好一点)
⑦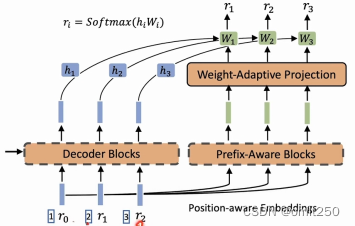
原本的输入如上图,但是作者认为持续性不够,所以自己人为添加了位置信息,比如原来是3 4 5 添加为13 14 15,并且他改变了共享权重,使之不一样,并且使用了额外编码器,来解决这一问题。(r0,r1等为输入)
⑧具体公式如下图
![]()
这篇关于文本检索粗读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!