摄取专题


CUPS 以包月形式让你在纽约的合作咖啡厅里无限摄取咖啡
《内容简介》:通过每月支付一定金额数目,CUPS用户可以在纽约地区的加盟独立咖啡店里无限量饮用咖啡或茶类饮品。 如果你住在纽约又是个无咖啡不欢的成瘾分子,那么由以色列团队 CUPS 开发的同名应用 CUPS 绝对值得你在手机主页上为它留一个位置。 目前 CUPS 只服务于纽约市地区。采取包月的方式,用户可以在加盟的独立咖啡厅里尽情享用对应种类的咖啡或者茶类饮品。Americ

Elasticsearch:通过摄取管道加上嵌套向量对大型文档进行分块轻松地实现段落搜索
作者:VECTOR SEARCH 向量搜索是一种基于含义而不是精确或不精确的 token 匹配技术来搜索数据的强大方法。 然而,强大的向量搜索的文本嵌入模型只能按几个句子的顺序处理短文本段落,而不是可以处理任意大量文本的基于 BM25 的技术。 现在,Elasticsearch 可以将大型文档与向量搜索无缝结合。 简单地说,它是如何在发挥作用的呢? Elasticsearch 功能(
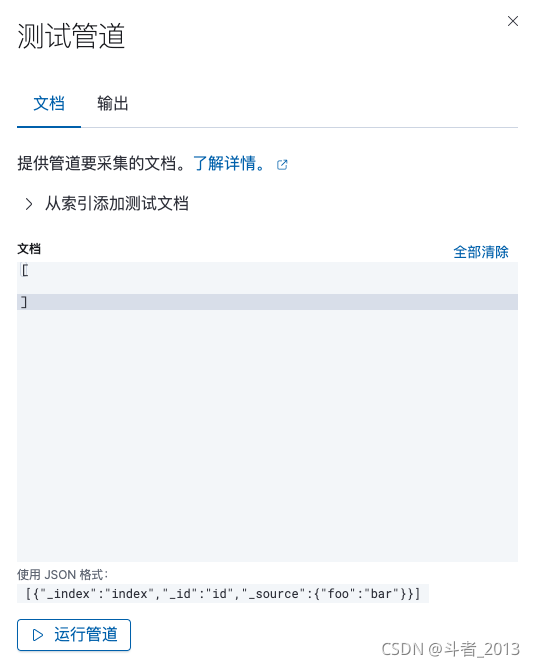
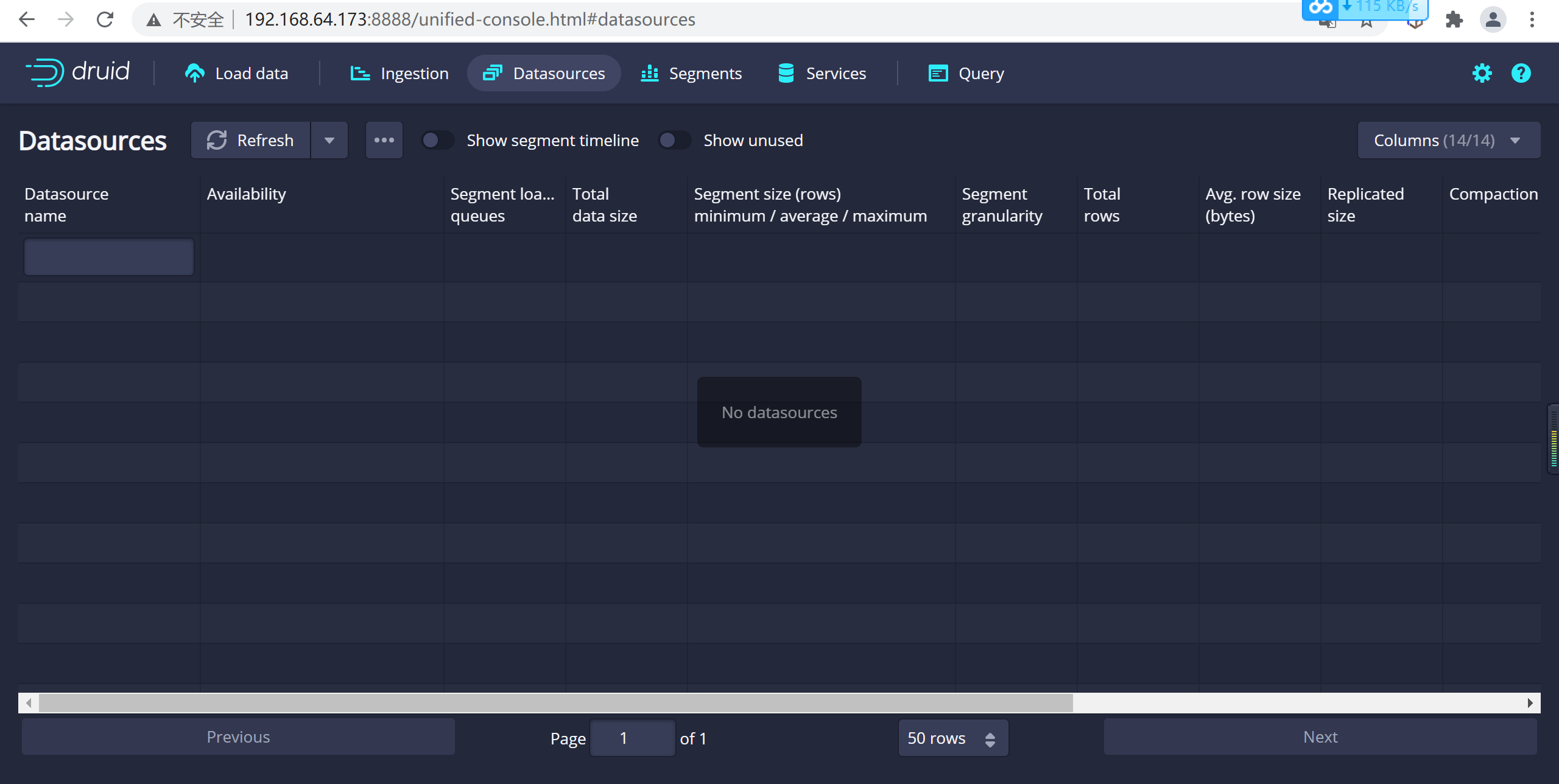
Apache Druid 数据摄取---本地数据和kafka流式数据
Durid概述 Apache Druid是一个集时间序列数据库、数据仓库和全文检索系统特点于一体的分析性数据平台。本文将带你简单了解Druid的特性,使用场景,技术特点和架构。这将有助于你选型数据存储方案,深入了解Druid存储,深入了解时间序列存储等。 Apache Druid是一个高性能的实时分析型数据库。 上篇文章,我们了解了Druid的加载方式, 咱么主要说两种,一种是加载本

Druid--数据摄取
数据摄取 Druid数据摄取分类批量(离线)数据摄取摄取本地文件摄取HDFS文件 流式(实时)数据摄取Kafka索引服务方式摄取 摄取配置文件结构说明主体结构数据解析模式数据源配置优化配置了解Druid WebUI生成 spec Druid数据摄取分类 Druid支持流式和批量两种方式的数据摄入,针对不同类型的数据,Druid将外部数据源分为两种形式: 流式数据源 指的是持

Elasticsearch:数据摄取中的使用指南
数据摄取是利用 Elasticsearch 的全部潜力进行高效搜索和分析的关键步骤。 在本文中,我们将探讨几个常用的基本实践,以确保将无缝且有效的数据摄取到 Elasticsearch 中。 通过遵循这些指南,你可以优化数据摄取流程,并在你的部署中最大限度地发挥 Elasticsearch 的优势。 准备好你的数据 在将数据提取到 Elasticsearch 之前,正确构建和准备数据至关重
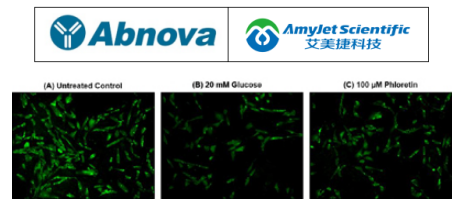
Abnova艾美捷2-NBDG 葡萄糖摄取检测试剂盒说明书
Abnova 艾美捷2-NBDG Glucose Uptake Assay Kit 提供了一种灵敏且非放射性的检测方法,用于测量培养细胞中的葡萄糖摄取。荧光信号可以通过带有 488 nm 激光和 530/30 nm 发射滤光片(FITC 通道)的荧光显微镜或流式细胞仪进行监测。该检测试剂盒是监测葡萄糖转运蛋白的最可靠工具。 Abnova艾美捷2-NBDG 葡萄糖摄取检测试剂盒参数: 适用
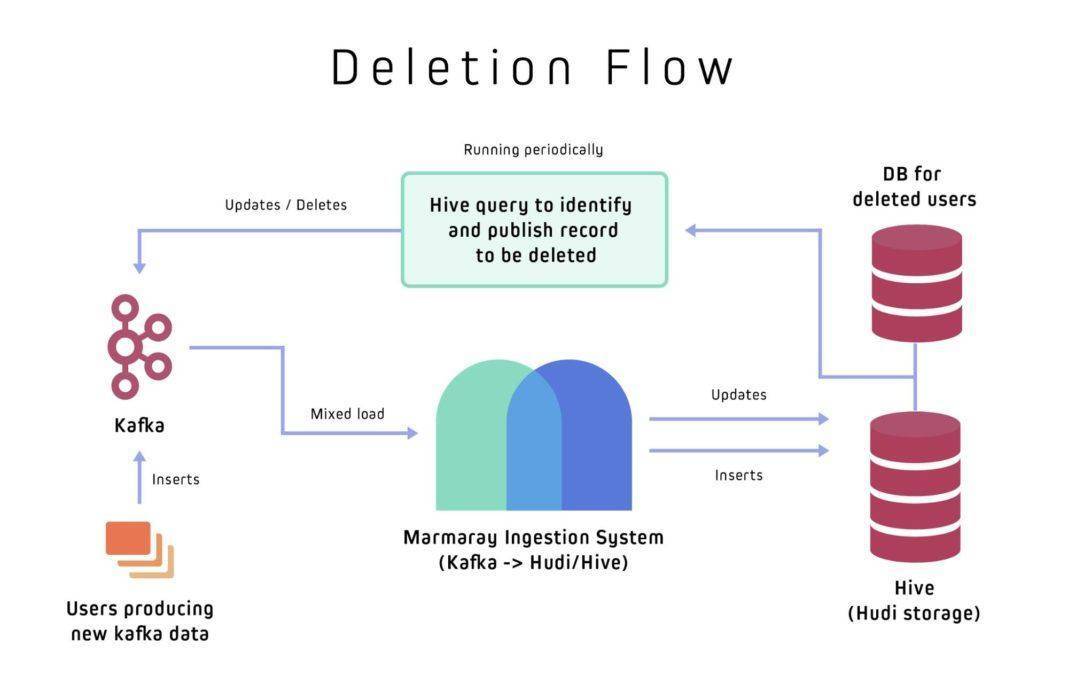
Uber开源Marmaray:基于Hadoop的通用数据摄取和分散框架
\ AI前线导读:\\ 三年前,Uber采用Apache Hadoop作为数据平台,从而可以跨计算机集群管理数PB的数据。但是,因为我们有很多团队、工具和数据源,所以需要一种可靠的方式来摄取和分散数据。Marmaray是Uber开源的Apache Hadoop数据提取和分散框架。Marmaray由我们的Hadoop平台团队设计和开发,是一个建立在Hadoop生态系统之上的基于插件的框架。用户可以

将Kafka流式数据摄取至Hudi
Hudi支持以下存储数据的视图 读优化视图 : 在此视图上的查询将查看给定提交或压缩操作中数据集的最新快照。该视图仅将最新parquet文件暴露给查询,所以它有可能看不到最新的数据,并保证与非Hudi列式数据集相比,具有相同的列式查询性能增量视图 : 对该视图的查询只能看到从某个提交/压缩后写入数据集的新数据。该视图有效地提供了更改流,来支持增量数据管道。实时视图 : 在此视图上的查询将查看某

利用高德地图模拟美团搜索相似地址以及地图摄取选择类似地址
效果图 我觉得不用废话那么多,直接上代码吧! <!doctype html><html><head><meta charset="utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="initial-scale=1.0, user-scalable=no, wi
Elasticsearch 8.11 中的合并更少,摄取更快
作者:ADRIEN GRAND Elasticsearch 8.11 改进了管理索引缓存的方式,从而减少了段合并。 我们对 Elasticsearch 8.11 从索引缓存回收内存的方式进行了重大更改,这有助于减少合并开销,从而加快索引速度。 使用我们的日志跟踪,我们观察到,当使用 1GB 堆运行时,这些变化使摄取吞吐量提高了 8%。 它在 Elasticsearch 8.10 及更
Elasticsearch 8.11 中的合并更少,摄取更快
作者:ADRIEN GRAND Elasticsearch 8.11 改进了管理索引缓存的方式,从而减少了段合并。 我们对 Elasticsearch 8.11 从索引缓存回收内存的方式进行了重大更改,这有助于减少合并开销,从而加快索引速度。 使用我们的日志跟踪,我们观察到,当使用 1GB 堆运行时,这些变化使摄取吞吐量提高了 8%。 它在 Elasticsearch 8.10 及更