本文主要是介绍ES中摄取管道详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、什么是摄取管道
摄取管道 Ingest pipelines
摄取管道主要用来在数据被索引之前对数据执行常见的转换。
例如,您可以使用管道来移除字段、从文本中提取值以及丰富数据。
管道由一系列称为处理器的可配置任务组成。每个处理器按顺序运行,对传入的文档进行特定的更改。在处理器运行之后,Elasticsearch 将转换后的文档添加到数据流或索引中。
管道的工作流程图如下:

二、摄取管道使用
1.创建管道
方式一:在kibana中创建
Stack Management > Ingest Pipelines
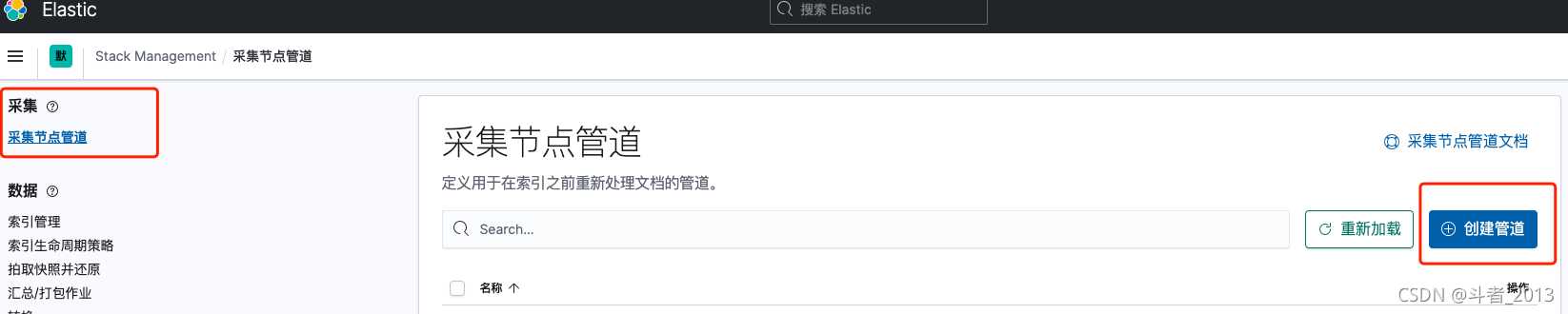
方式二:采用API创建
下面的 create pipeline API 请求创建一个包含两个 set 处理器和一个小写处理器的管道。处理器按指定的顺序顺序运行。
PUT _ingest/pipeline/my-pipeline
{"description": "My optional pipeline description","processors": [{"set": {"description": "My optional processor description","field": "my-long-field","value": 10}},{"set": {"description": "Set 'my-boolean-field' to true","field": "my-boolean-field","value": true}},{"lowercase": {"field": "my-keyword-field"}}]
}
2.测试管道
方式一:在kibana中测试
选择创建的管道,打开编辑页面,测试管道——》添加文档
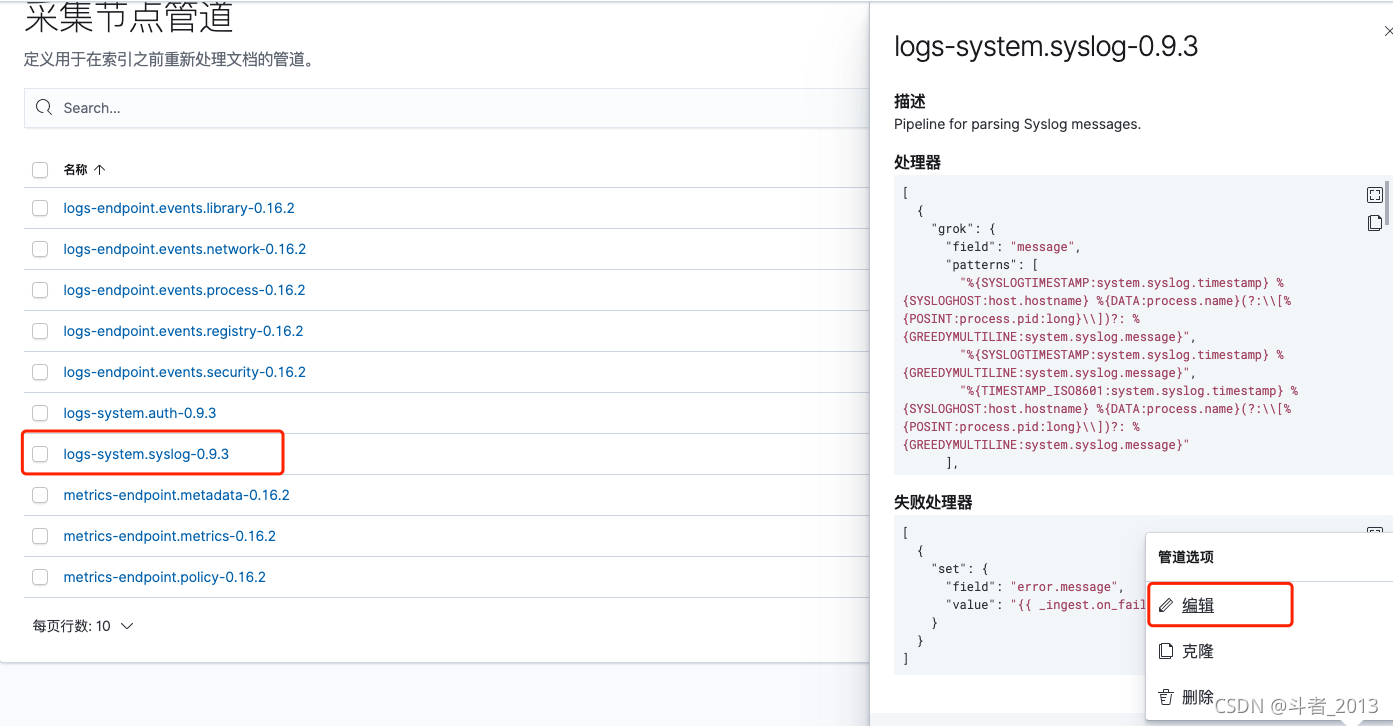

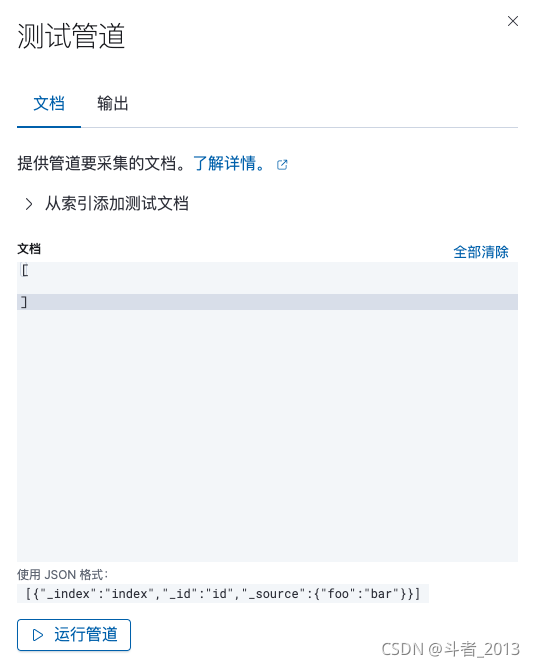
方式二:采用_simulate的API测试
1、在请求URL中指定管道
POST _ingest/pipeline/my-pipeline/_simulate
{"docs": [{"_source": {"my-keyword-field": "FOO"}},{"_source": {"my-keyword-field": "BAR"}}]
}
2、在请求body中指定管道
POST _ingest/pipeline/_simulate
{"pipeline": {"processors": [{"lowercase": {"field": "my-keyword-field"}}]},"docs": [{"_source": {"my-keyword-field": "FOO"}},{"_source": {"my-keyword-field": "BAR"}}]
}
3.在索引请求中使用管道
说明:在向索引my-data-stream添加数据时,使用管道y-pipeline
POST my-data-stream/_doc?pipeline=my-pipeline
{"@timestamp": "2099-03-07T11:04:05.000Z","my-keyword-field": "foo"
}PUT my-data-stream/_bulk?pipeline=my-pipeline
{ "create":{ } }
{ "@timestamp": "2099-03-07T11:04:06.000Z", "my-keyword-field": "foo" }
{ "create":{ } }
{ "@timestamp": "2099-03-07T11:04:07.000Z", "my-keyword-field": "bar" }
在使用_update_by_query和_reindex时使用管道:
POST my-data-stream/_update_by_query?pipeline=my-pipelinePOST _reindex
{"source": {"index": "my-data-stream"},"dest": {"index": "my-new-data-stream","op_type": "create","pipeline": "my-pipeline"}
}
4.给索引设置默认管道
通过index.default_pipeline属性,可以给索引设置默认的管道。
5.索引模板中设置默认管道
PUT _component_template/logs-my_app-settings
{"template": {"settings": {"index.default_pipeline": "logs-my_app-default","index.lifecycle.name": "logs"}}
}
6.管道异常处理
PUT _ingest/pipeline/my-pipeline
{"processors": [ ... ],"on_failure": [{"set": {"description": "Index document to 'failed-<index>'","field": "_index","value": "failed-{{{ _index }}}"}}]
}
三、管道功能演示
1、字段重命名
PUT _ingest/pipeline/my-pipeline
{"processors": [{"rename": {"description": "Rename 'provider' to 'cloud.provider'","field": "provider","target_field": "cloud.provider","ignore_failure": true}}]
}
2、删除特定记录
这里采用if配置管道处理函数的触发条件。
PUT _ingest/pipeline/my-pipeline
{"processors": [{"drop": {"description": "Drop documents with 'network.name' of 'Guest'","if": "ctx?.network?.name == 'Guest'"}}]
}
更复杂的条件可以采用scripts脚本:
PUT _ingest/pipeline/my-pipeline
{"processors": [{"drop": {"description": "Drop documents that don't contain 'prod' tag","if": """Collection tags = ctx.tags;if(tags != null){for (String tag : tags) {if (tag.toLowerCase().contains('prod')) {return false;}}}return true;"""}}]
}
注意⚠️:
尽量避免使用复杂或昂贵的条件脚本,昂贵的条件脚本会降低索引速度。
3、给字段赋值
PUT _ingest/pipeline/my-pipeline
{"processors": [{"set": {"field": "_source.my-long-field","value": 10}}]
}
采用元数据赋值
PUT _ingest/pipeline/my-pipeline
{"processors": [{"set": {"description": "Index the ingest timestamp as 'event.ingested'","field": "event.ingested","value": "{{{_ingest.timestamp}}}"}}]
}
总结
本文主要介绍了ES中摄取管道pipeline的使用。
摄取管道主要用来在数据被索引之前对数据执行常见的转换。
可以使用管道来移除字段、从文本中提取值以及丰富数据。
这篇关于ES中摄取管道详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





