子句专题

【C++】try 语句捕获异常,catch子句处理异常
#include <iostream>#include <stdexcept>using namespace std;int main(){int i1, i2;while(cin >> i1 >> i2){try{if (i2 == 0)throw runtime_error("分母为0!");cout << "i1除以i2的结果是: " << i1/i2 << endl;}catch(ru

MySQL必会知识精华5(WHERE简单子句)
我们的目标是:按照这一套资料学习下来,大家可以完成数据库增删改查的实际操作。同时轻松应对面试或者笔试题中MySQL相关题目。 上篇文章我们先做一下数据库的SELECT简单查询的方法。本篇文章主要介绍查询的WHERE子句的使用方法。 1、使用WHERE简单子句 数据库有很多数据,很多时候我们只是需要一部分,这时候就牵涉到筛选的功能。 可以使用WHERE 子句 SELECT

PostgreSQL LIMIT 子句的使用与优化
PostgreSQL LIMIT 子句的使用与优化 引言 PostgreSQL 是一款功能强大的开源关系型数据库管理系统,它以其稳定性、可扩展性和高性能而闻名。在处理大量数据时,我们经常需要限制返回的记录数量,以提高查询效率和减少数据传输量。这时,LIMIT 子句就变得非常有用。本文将详细介绍 PostgreSQL 中 LIMIT 子句的使用方法,并提供一些优化建议。 LIMIT 子句的基本

问题解决:除非另外还指定了 TOP 或 FOR XML,否则,ORDER BY 子句在视图、内联函数、派生表、子查询和公用表表达式中无效
文章目录 问题场景问题环境问题原因解决方案结果总结随缘求赞 问题场景 因为项目需要,需要在公共框架里面引入sqlserver方言类。而在实现sqlserver方言类之后,调用方言类的方法的时候,发现一个错误 错误提示如下: >[错误] 脚本行:1-10 --------------------------------------Id 1033, Level 15, State

Partition by子句
上篇博客写到使用开窗函数来进行数据查询,那么over关键字可以加什么查询条件呢?下面先介绍一下其中之一的partition by子句。 开窗函数的over关键字后括号中可以使用Partition by字句来定义行的分区来进行聚合运算。与group by 字句不同,partition by字句创建的分区是独立于结果集的,创建的分区只是提供聚合计算的,而且不同的开窗函数所创建的分区也不相互影响。

【MySQL进阶之路】 group by子句——分组查询
目录 引言 聚合函数 案例 个人主页:东洛的克莱斯韦克-CSDN博客 引言 GROUP BY 子句在 SQL 中用于将查询结果集按照一个或多个列进行分组。当与聚合函数(如 COUNT(), SUM(), AVG(), MAX(), MIN())一起使用时,GROUP BY 可以帮助我们对每个分组执行计算。 语法 SELECT column_name(s), AGGREG

选择列表中的列 'XXXX' 无效,因为该列没有包含在聚合函数或 GROUP BY 子句中
其实初学的时候看到这个会很困惑,为什么没有包含?聚合函数又是什么?小朋友,你是否有很多问号?首先讲一些很浅显的,也就是这个问题的解决方案。其实就如字面意思说的那样,你没有包含该列,因此你不能GROUP BY.。文字总是苍白的,我也不想敲太多,放两张图的事就明白了。方法一:把该列包含进去 方法二:用ORDER BY 接下来就是深层次的东西了,为什么要包含进去,为什么ORDER BY可以而GROUP
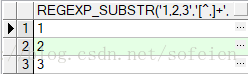
Oracle存储过程中的IN子句传参字符串的问题
在实际使用中,经常会有带in的子查询,如where id in (1,2,3),或者where name in ('a','b','c')这样的情况,但是到存储过程中,如果使用变量当作查询条件会有问题。 示例: CREATE OR REPLACE PROCEDURE test (vi_types in VARCHAR2)AS vs_str VARCHAR2(100);BEGIN-
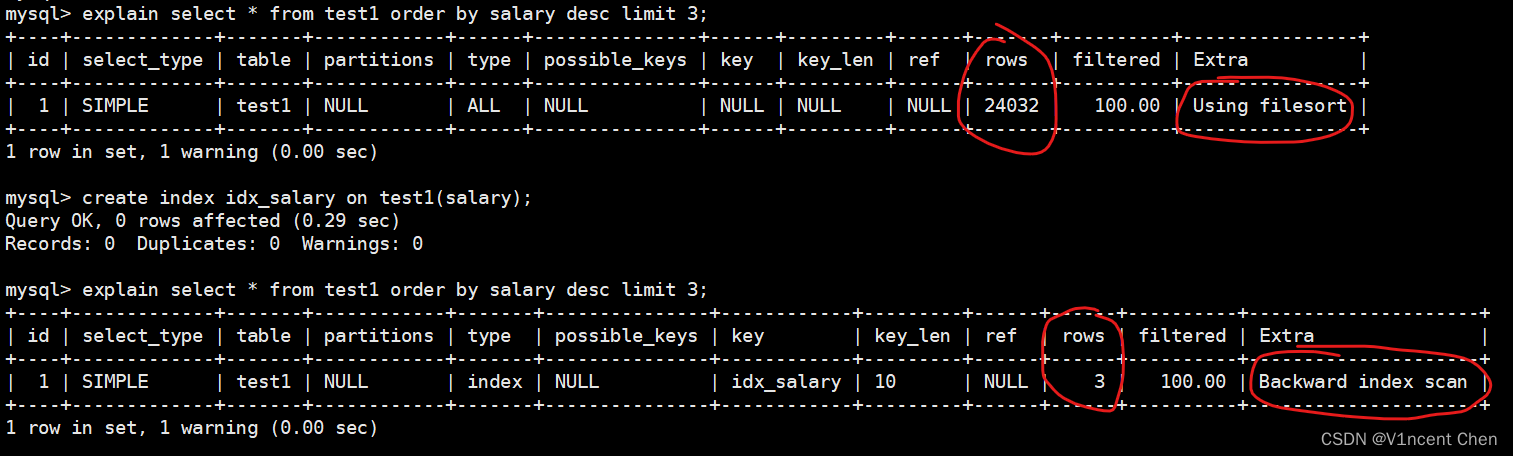
MySQL limit子句用法及优化(Limit Clause Optimization)
在MySQL中,如果只想获取select查询结果的一部分,可以使用limit子句来限制返回记录的数量,limit在获取到满足条件的数据量时即会立刻终止SQL的执行。相比于返回所有数据然后丢弃一部分,执行效率会更高。 文章目录 一、limit子句用法示例1.1 基本用法1.2 limit和order by1.2.1 排序瓶颈优化 二、limit分页优化2.1 延迟关联2.2 转换为位置查询2

postgresql报错:列“XXX”必须出现在GROUP BY子句中或在聚合函数中使用
背景 我在做一个对关联的几张表进行select的操作时,因为有写重复数据,我只需要其中一条,所以我按照字段写了一个group by,希望每个分组只保留一条数据给我就行了。但是一致性就报如题所示的错误。 原因 据了解,postgresql认为select出来的字段必须要在GROUP BY子句中或在聚合函数中使用才行,真没想到就是报错信息的字面意思。 解决 网上搜索到的信息认为要对selec

ON DUPLICATE KEY UPDATE 子句
ON DUPLICATE KEY UPDATE 是 MySQL 中的一个 SQL 语句中的子句,主要用于在执行 INSERT 操作时处理可能出现的重复键值冲突。当尝试插入的记录导致唯一索引或主键约束冲突时(即试图插入的记录的键值已经存在于表中),此子句会触发一个更新操作,而不是抛出错误。 官方文档:https://dev.mysql.com/doc/refman/8.4/en/insert-on
SQLServer2022新特性Window子句
SQLServer2022新特性Window子句 参考官方文档 https://learn.microsoft.com/zh-cn/sql/t-sql/queries/select-window-transact-sql?view=sql-server-ver16 1、本文内容 语法参数一般备注示例 1.1、新特性适用于: SQL Server 2022 (16.x)Azure SQL

SQL WHERE 子句中的单引号
由于对SQL 语句的不熟悉,在机房收费系统中一个很的简单问题也可能耽误很长时间。这篇谈及一个简单的单引号的使用。 如需有条件地从表中选取数据,可将 WHERE 子句添加到 SELECT 语句。 我开始没在sql语句中插入单引号导致错误 给msgtext 加监视后: 在sql server 中查询: 而加入单引号: 涉及到
Mysql:GROUP BY 子句中可以使用SELECT 子句中定义别名
示例 GROUP BY 子句中可以使用SELECT 子句中定义别名 SELECT DATE(add_time) AS addTime, COUNT(*) AS totalFROM userGROUP BY addTimeORDER BY addTime
ES dsl查询filter(或must)和should并用时should子句不生效
记录下今天编码时遇到的问题,在filter和should同级并用的查询下,should子句并没有生效,只有filter子句生效。 例如以下dsl {"query": {"bool": {"filter": [{"term": {"status": 3}}],"should": [{"bool": {"filter": [{"bool": {"must_not": {"exists": {"fi
join 子句中其中一个表达式的类型不正确。对“GroupJoin”的调用中的类型推理失败。
from a in defaultdata join b in airData on new {a.CITYCODE,a.MONIDATE} equals new {b.CITYCODE,b.MONIDATE} into temp
SQL select的ORDER BY子句
SQL select的ORDER BY子句 SELECT语句获得的数据一般是没有排序的。为了方便阅读和使用,最好对查询的结果进行一次排序。SQL语言中,用于排序的是ORDER BY子句。 语法格式为:ORDER BY 表达式1 [ ASC | DESC] [,表达式2[ ASC | DESC][,…n]] ASC 升序/顺序 (1,2,3) DESC
SQL select的from 子句
SQL select的from 子句 在每一条要从表或视图中检索数据的 SELCET 语句中,都需要使用 FROM 子句。用 FROM 子句可以: 列出选择列表和 WHERE 子句中所引用的列所在的表和视图。可用 AS 子句为表和视图的名称指定别名。
SQL SELECT WHERE 子句 介绍
SQL WHERE 子句 介绍 使用WHERE子句的目的是为了从表格的数据集中过滤出符合条件的行。 语法格式如下: SELECT 列名1[,列名2,…列名n] FROM 表名 WHERE 条件 1.使用算术表达式 使用算术表达式作为搜索条件的一般表达形式是:表达式 算术操作符 表达式
【postgresql 基础入门】分组查询 group by 子句的写法,分组条件过滤having子句的写法,多列的分组以及与join联合的多表分组
分组查询与分组条件过滤 专栏内容: postgresql内核源码分析手写数据库toadb并发编程 个人主页:我的主页 管理社区:开源数据库 座右铭:天行健,君子以自强不息;地势坤,君子以厚德载物. 文章目录 分组查询与分组条件过滤一、前言 二、概述 三、分组group by 介绍 基本分组使用分组中使用聚合函数多表join中使用分组多列的分组 四、分组条件having介绍

SQL 第三章 (WHERE子句查询)
目录 WHERE子句操作符使用示例练习 🚀上一章练习题答案 使用AS关键字可以对列名称重命名。 SELECT name,unit_price,unit_price * 1.1 AS "new price"FROM products WHERE子句 本节将学习到WHERE子句的用法,以及搭配运算符和操作符的使用。下面举例一些使用这些符号的例子,举一反三,替换搭
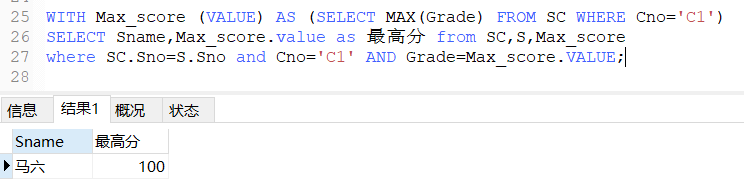
SQL语言中的With子句是什么?MySQL-With...as子句如何使用?
目录 With子句是什么? MySQL-With...as子句如何使用? 单个WITH AS 子句(创建一张临时视图) 多个WITH AS 子句(创建多张临时视图) 总结 With子句是什么? With子句是在SQL 99中引入的,目前只有部分数据库支持这一子句。如果我们将一个复杂查询分解成一些小视图,然后将它们组合起来,就像将一个程序按其任务分解,简化复杂的查询为一个

在from子句中使用子查询
目录 查询每个部门的编号、名称、位置、部门人数、平均工资 多表查询分组统计 子查询分组统计 Oracle从入门到总裁:https://blog.csdn.net/weixin_67859959/article/details/135209645 为了解释这种查询的作用,下面做一个简单的查询 查询每个部门的编号、名称、位置、部门人数、平均工资 这个前面已经讲过了 SQL> s
SQLite Having 子句
HAVING 子句允许指定条件来过滤将出现在最终结果中的分组结果。 WHERE 子句在所选列上设置条件,而 HAVING 子句则在由 GROUP BY 子句创建的分组上设置条件。 语法 下面是 HAVING 子句在 SELECT 查询中的位置: <span style="color:#000000">SELECTFROMWHEREGROUP BYHAVINGORDER BY</s
SQLite Glob 子句
SQLite 的 GLOB 运算符是用来匹配通配符指定模式的文本值。如果搜索表达式与模式表达式匹配,GLOB 运算符将返回真(true),也就是 1。与 LIKE 运算符不同的是,GLOB 是大小写敏感的,对于下面的通配符,它遵循 UNIX 的语法。 星号 (*) 问号 (?) 星号(*)代表零个、一个或多个数字或字符。问号(?)代表一个单一的数字或字符。这些符号可以被组合使用。 语法