本文主要是介绍ON DUPLICATE KEY UPDATE 子句,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ON DUPLICATE KEY UPDATE 是 MySQL 中的一个 SQL 语句中的子句,主要用于在执行 INSERT 操作时处理可能出现的重复键值冲突。当尝试插入的记录导致唯一索引或主键约束冲突时(即试图插入的记录的键值已经存在于表中),此子句会触发一个更新操作,而不是抛出错误。
官方文档:https://dev.mysql.com/doc/refman/8.4/en/insert-on-duplicate.html
基本语法
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...)
ON DUPLICATE KEY UPDATEcolumn1 = value1,column2 = value2,...;
ON DUPLICATE KEY UPDATE子句处理逻辑
语句是根据唯一索引判断记录是否重复的。当执行插入操作时,如果唯一键不冲突(表中不存在记录),则执行插入操作;如果遇到唯一键冲突(表中存在记录),则会执行更新操作,使用给定的新值来更新冲突行中的列。
示例
假设我们有一个用户表 users,包含 id(主键)、username(用户名,唯一)和 email 三个字段。现在我们要插入或更新一条用户记录,如果用户名已经存在,则只更新用户的邮箱地址。
表结构如下:
CREATE TABLE `users` (`id` INT AUTO_INCREMENT PRIMARY KEY,`username` VARCHAR(255) UNIQUE NOT NULL,`email` VARCHAR(255)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
不存在记录,插入的情况
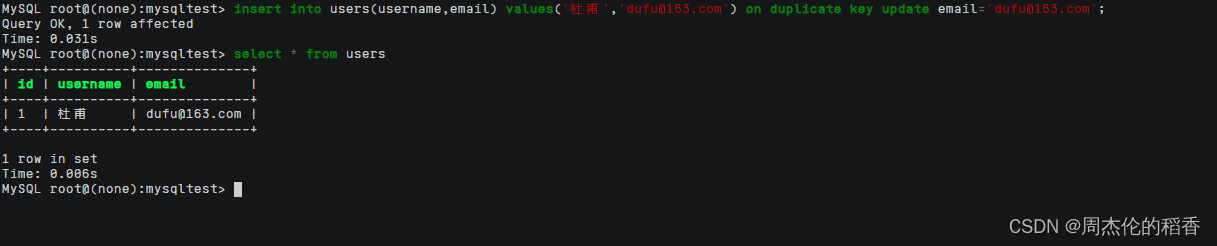
使用insert into插入已有的username,可以看到会报错

使用ON DUPLICATE KEY UPDATE 子句插入已有的username,没有报错执行成功

总结:在上面这个例子中,如果尝试插入的用户名
'杜甫'已经存在于表中,由于username字段设置了唯一约束,这将触发ON DUPLICATE KEY UPDATE子句。然后,这条 SQL 语句不会插入新的记录,而是执行更新操作,将该用户名对应的邮箱地址更新为'libai@163.com'。如果用户名不存在,则正常插入新记录。
可能看到这里就会有人问了那么为什么不使用update呢,简单的来说不都是更新数据吗?
使用 ON DUPLICATE KEY UPDATE 与直接使用 UPDATE 语句的主要区别在于处理数据插入和更新的策略和目的。
下面是选择 ON DUPLICATE KEY UPDATE 而不直接使用 UPDATE 的几个主要原因:
-
同时处理插入与更新:
ON DUPLICATE KEY UPDATE允许在一个操作中同时尝试插入新记录和更新现有记录。如果记录不存在,就插入新记录;如果存在(根据唯一索引或主键判断),则更新记录。这样可以在不确定记录是否存在的情况下,通过一次操作完成“插入或更新”,简化逻辑和代码。 -
减少查询开销:相比于先执行查询判断记录是否存在,再根据结果决定执行
INSERT或UPDATE,ON DUPLICATE KEY UPDATE直接在数据库层面处理,减少了额外的查询请求,降低了网络和计算开销。 -
原子性操作:在事务中使用时,
ON DUPLICATE KEY UPDATE作为一个整体操作,要么全部成功,要么全部失败,保证了数据操作的原子性,这对于维护数据一致性非常重要。 -
避免并发冲突:在高并发环境下,先查询后更新可能会遇到“丢失更新”的问题。而
ON DUPLICATE KEY UPDATE通过数据库的内置机制处理冲突,有助于减少这类并发问题。 -
简化逻辑:对于批量数据处理,特别是导入大量数据时,使用
ON DUPLICATE KEY UPDATE可以显著简化代码逻辑,避免编写复杂的循环判断逻辑。
总结:ON DUPLICATE KEY UPDATE提供了一种高效、简洁的方式来处理那些在插入数据时可能遇到的重复记录问题,特别适用于那些需要“如果存在则更新,否则插入”的场景,而直接使用UPDATE则更适合于确定记录已经存在并且需要修改的情况。
当然还有ON DUPLICATE KEY UPDATE 子句和 REPLACE INTO 语句的区别会在下一篇文章中介绍
使用 ON DUPLICATE KEY UPDATE 子句的场景及优缺点
| 使用场景 | 优点 | 缺点 |
|---|---|---|
| 数据去重与更新 | 自动处理冲突,减少编程逻辑 | 对于大量并发可能产生锁竞争,影响性能 |
| 数据同步 | 简化数据同步流程,避免手动检查 | 更新逻辑需精确设计,以免误更新非冲突字段 |
| 统计计数 | 有效累加计数,避免重复记录 | 需要确保更新逻辑正确,避免数据不一致 |
| 确保数据一致 | 支持事务处理,增强数据完整性 | 对于复杂更新逻辑处理能力有限 |
| 简化逻辑 | 一行命令完成“插入或更新”,代码简洁 | 对唯一性约束依赖性强,表设计需预先规划 |
这篇关于ON DUPLICATE KEY UPDATE 子句的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




