大型项目专题

开发大型项目要注意的事项
1,所有的状态类型均不能使用数字直接表示,一律用常量或者枚举类来标识,进行统一管理和识别; 2,所有的传递参数都必须有数据类型model对应,不允许直接采用PHP键值对数组的方式进行传递; 3,所有的函数都要进行try...catch操作,避免报错时无法及时追踪; 4,所有的Exception中的message必须提示非常详情,具有全局区分性,不可用诸如,程序报错,参数报错,保存报错等毫无意

如何学习大型项目的源码?
最近有朋友突然问我一个问题 “你怎么把UE4引擎代码看的那么深入的?” 看到问题后我还愣了一下,因为这是第一次有人给我打了个”深入UE4”的标签。其实我接触虚幻引擎满打满算也就两年,确实谈不上深入。只是靠着平时的学习习惯积累,写了一些相关的技术文章。 但这个事却让我突然意识到最容易被我忽略的学习习惯很可能是有一定价值和意义的。我只想着分享我对引擎学习的心得总结,却从没有想过分享我的学习方法,或

spark 大型项目实战(六):用户访问session分析(六) --开发配置管理组件
文章地址:http://www.haha174.top/article/details/259340 1.简述 配置管理组件 * 1、配置管理组件可以复杂,也可以很简单,对于简单的配置管理组件来说,只要开发一个类,可以在第一次访问它的 时候,就从对应的properties文件中,读取配置项,并提供外界获取某个配置key对应的value的方法 2、如果是特别复杂的配置管理组件,那么可能需要使
spark 大型项目实战(五):用户访问session分析(五) --数据表设计
文章地址:http://www.haha174.top/article/details/252047 本篇文章,是大数据项目开发流程的数据设计环节。在进行完了数据调研、需求分析、技术实现方案,进行数据设计。数据设计,往往包含两个环节,第一个呢,就是说,我们的上游数据,就是数据调研环节看到的项目基于的基础数据,是否要针对其开发一些Hive ETL,对数据进行进一步的处理和转换,从而让我们能够更加方
spark 大型项目实战(四):用户访问session分析(四) --简要技术方法的设计
文章地址:http://www.haha174.top/article/details/257674 1、按条件筛选session 2、聚合统计:统计出符合条件的session中,访问时长在1s~3s、4s~6s、7s~9s、10s~30s、30s~60s、1m~3m、3m~10m、10m~30m、30m以上各个范围内的session占比;访问步长在1~3、4~6、7~9、10~30、30~60、
spark 大型项目实战(三):用户访问session分析(三) --简要需求分析
文章地址:http://www.haha174.top/article/details/253381 本篇文章主要简要的介绍此次项目实战的需求分析 1、按条件筛选session 2、统计出符合条件的session中,访问时长在1s~3s、4s~6s、7s~9s、10s~30s、30s~60s、1m~3m、3m~10m、10m~30m、30m以上各个范围内的session占比;访问步长在13、46、
spark 大型项目实战(二):用户访问session分析(二) --基础数据结构以及平台架构介绍
1.此次实战项目中所用到的表结构以及字段含义的介绍 表名:user_visit_action(Hive表)date:日期,代表这个用户点击行为是在哪一天发生的user_id:代表这个点击行为是哪一个用户执行的session_id :唯一标识了某个用户的一个访问sessionpage_id :点击了某些商品/品类,也可能是搜索了某个关键词,然后进入了某个页面,页面的idaction_ti
spark 大型项目实战(一):用户访问session分析(1) --模块介绍
模块的目标:对用户访问的session 进行分析 1、可以根据使用者指定的某些条件,筛选出指定的一些用户(有特定年龄、职业、城市); 2、对这些用户在指定日期范围内发起的session,进行聚合统计,比如,统计出访问时长在0~3s的session占总session数量的比例; 3、按时间比例,比如一天有24个小时,其中12:0013:00的session数量占当天总session数量的50%,当天

spark 大型项目实战(四十八):troubleshooting之解决算子函数返回NULL导致的问题
在算子函数中,返回null // return actionRDD.mapToPair(new PairFunction<Row, String, Row>() {//// private static final long serialVersionUID = 1L;// // @Override//
spark 大型项目实战(四十七):troubleshooting之解决各种序列化导致的报错
你会看到什么样的序列化导致的报错? 用client模式去提交spark作业,观察本地打印出来的log。如果出现了类似于Serializable、Serialize等等字眼,报错的log,那么恭喜大家,就碰到了序列化问题导致的报错。 虽然是报错,但是序列化报错,应该是属于比较简单的了,很好处理。 序列化报错要注意的三个点: 1、你的算子函数里面,如果使用到了外部的自定义类型的变量,那么此时,
spark 大型项目实战(四十六):troubleshooting之解决YARN队列资源不足导致的application直接失败
如果说,你是基于yarn来提交spark。比如yarn-cluster或者yarn-client。你可以指定提交到某个hadoop队列上的。每个队列都是可以有自己的资源的。 跟大家说一个生产环境中的,给spark用的yarn资源队列的情况:500G内存,200个cpu core。 比如说,某个spark application,在spark-submit里面你自己配了,executor,80个

spark 大型项目实战(四十五):troubleshooting之解决JVM GC导致的shuffle文件拉取失败
1. 比如,executor的JVM进程,可能内存不是很够用了。那么此时可能就会执行GC。minor GC or full GC。总之一旦发生了JVM之后,就会导致executor内,所有的工作线程全部停止。 2. 下一个stage的executor,可能是还没有停止掉的,task想要去上一个stage的task所在的exeuctor,去拉取属于自己的数据,结果由于对方正在gc,就导致拉取了
spark 大型项目实战(四十四):troubleshooting之控制shuffle reduce端缓冲大小以避免OOM
1. map端的task是不断的输出数据的,数据量可能是很大的。 但是,其实reduce端的task,并不是等到map端task将属于自己的那份数据全部写入磁盘文件之后,再去拉取的。map端写一点数据,reduce端task就会拉取一小部分数据,立即进行后面的聚合、算子函数的应用。 每次reduece能够拉取多少数据,就由buffer来决定。因为拉取过来的数据,都是先放在buffer中的。然

spark 大型项目实战(四十三):算子调优之reduceByKey本地聚合介绍
下面给出一个图解: map端的task是不断的输出数据的,数据量可能是很大的。 但是,其实reduce端的task,并不是等到map端task将属于自己的那份数据全部写入磁盘文件之后,再去拉取的。map端写一点数据,reduce端task就会拉取一小部分数据,立即进行后面的聚合、算子函数的应用。 每次reduece能够拉取多少数据,就由buffer来决定。因为拉取过来的数据,都是先放在b
spark 大型项目实战(四十二):算子调优之reduceByKey本地聚合介绍
下面看一段简单的world count val lines = sc.textFile("hdfs://")val words = lines.flatMap(_.split(" "))val pairs = words.map((_, 1))val counts = pairs.reduceByKey(_ + _)counts.collect() reduceByKey,相较于普通
spark 大型项目实战(四十一):算子调优之使用repartition解决Spark SQL低并行度的性能问题
并行度:之前说过,并行度是自己可以调节,或者说是设置的。 1、spark.default.parallelism 2、textFile(),传入第二个参数,指定partition数量(比较少用) 咱们的项目代码中,没有设置并行度,实际上,在生产环境中,是最好自己设置一下的。官网有推荐的设置方式,你的spark-submit脚本中,会指定你的application总共要启动多少个executo

spark 大型项目实战(四十): 算子调优之使用foreachPartition优化写数据库性能
foreach的写库原理 默认的foreach的性能缺陷在哪里? 首先,对于每条数据,都要单独去调用一次function,task为每个数据,都要去执行一次function函数。 如果100万条数据,(一个partition),调用100万次。性能比较差。 另外一个非常非常重要的一点 如果每个数据,你都去创建一个数据库连接的话,那么你就得创建100万次数据库连接。 但是要注意的是,
spark 大型项目实战(三十九): 算子调优之filter过后使用coalesce减少分区数量
下面给出一种filter 的情况 默认情况下,经过了这种filter之后,RDD中的每个partition的数据量,可能都不太一样了。(原本每个partition的数据量可能是差不多的) 问题: 1、每个partition数据量变少了,但是在后面进行处理的时候,还是要跟partition数量一样数量的task,来进行处理;有点浪费task计算资源。 2、每个partition的数据量不

【视频分享】Spark大型项目实战 138讲
在公众号(big_data_community)内回复:“Spark138讲”获取网盘下载地址(应大家请求,地址已更新) 本资源来源于网络,分享到网络。

Qt :浅谈在大型项目中使用信号管理器
一、引言 在大型的Qt项目中,我们往往涉及到很多不同类型的对象之间通信交互,这时候,仍旧采用小项目使用的哪里使用,哪里关联的方法,在复杂的场景下将是无穷无尽的折磨。 下面我们给出一种苦难的场景。 class A: public QObject {Q_OBJECTpublic:A(QObject *parent = nullptr);signals:void
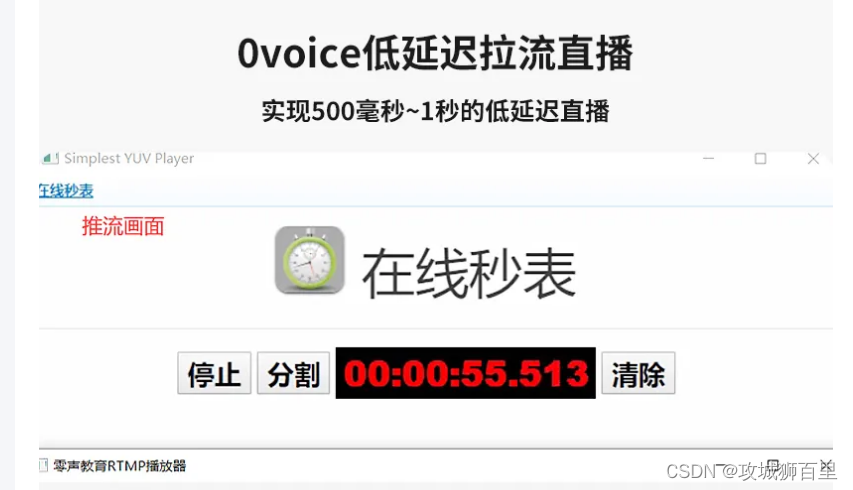
【音视频流媒体服务端开发学习指南】音视频驱动、多媒体中间件、流媒体服务器的开发,开发过即时通讯+音视频通话的大型项目
音视频流媒体开发是一个涉及多种技术和知识领域的实践领域。以下是一份指南,帮助你系统学习流媒体开发: 理解基础概念: 习关于音视频数据的基础知识,包括常见的音频与视频格式、编解码器(codec)、容器格式等。 了解流媒体的基本工作原理,包括直播和点播的区别,以及如何通过互联网传输音视频流。 掌握关键技术: 网络技术:了解TCP/IP、UDP、HTTP、RTMP、HLS、DASH等网络协议的工作

ROS2高效学习第十章 -- ros2 高级组件之大型项目中的 launch 其二
ros2 高级组件之大型项目中的 launch 1 前言和资料2 正文2.1 启动 turtlesim,生成一个 turtle ,设置背景色2.2 使用 event handler 重写上节的样例2.3 turtle_tf_mimic_rviz_launch 样例 3 总结 1 前言和资料 早在ROS2高效学习第四章 – ros2 topic 编程之收发 string 并使用 r
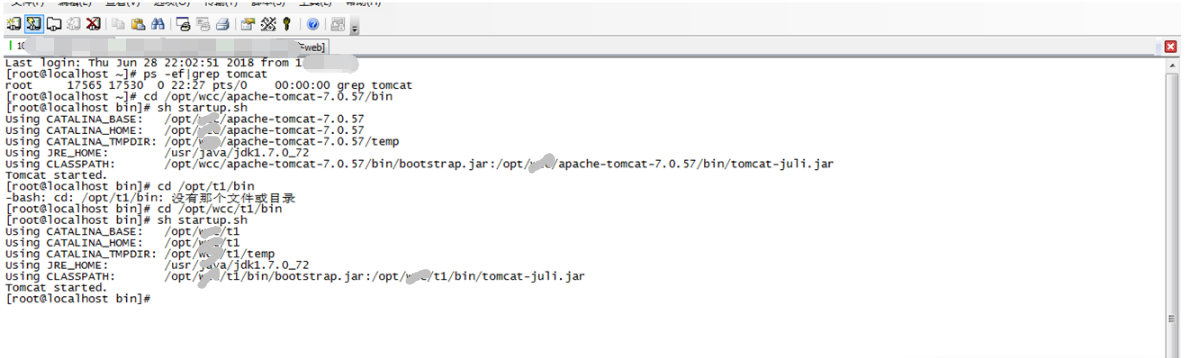
**大型项目增量发版现场(发版狂魔)
2019独角兽企业重金招聘Python工程师标准>>> 正好今天****项目xx环境发版,小编做个笔录来深度解析大型项目发布现场。上一篇博客介绍了增量打包发版代码,本篇继续介绍发版过程。 步骤: 1.发版前准备:a.代码增量打包,b.服务器代码备份 备份命令:nohup tar --exclude /opt/www/apache-tomcat-7.0.57/webap

Vue-Vben-Admin:中大型项目后台解决方案及如何实现页面反向传值
Vue-Vben-Admin:中大型项目后台解决方案及如何实现页面反向传值 摘要: Vue-Vben-Admin是一个基于Vue3.0、Vite、Ant-Design-Vue和TypeScript的开源项目,旨在为开发中大型项目提供一站式的解决方案。它涵盖了组件封装、实用工具、钩子函数、动态菜单、权限验证以及按钮级别权限控制等功能,帮助开发者快速搭建企业级中后台产品原型。本文将详细介绍V

专访许鹏:谈C程序员修养及大型项目源码阅读与学习
摘要:阅读源码是开源项目最好的学习方式,然而真正的执行起来却并不容易。这里我们为大家分享许鹏的源码阅读经验、C程序员的修养以及Spark和Storm源码走读博文。 对许鹏的第一印象来源于其Bolg的粗读,最早时候更准确说应该是博文的粗略统计——1年零6个月完成55篇以上的博文,基本每篇都附有代码,其中更有多篇源码解读博文。而在浏览完大量的Storm和Spark源码阅读后,笔者更认定了这是位Had

给开发维护大型项目开发者的建议【转】
假设你是正在开发和维护一个包含2000个类并使用了很多框架的Java开发人员。你要如何理解这些代码?在一个典型的Java企业项目小组中,大部分能够帮你的高级工程师看起来都很忙。文档也很少。你需要尽快交付成果,并向项目组证明自己的能力。你会如何处理这种状况?这篇文章为开始一个新项目的Java开发者提供了一些建议。 0. 不要试图一下子搞懂整个项目 好好考虑一下,为什么理解项目代码是第一位