基数专题
对Powerdesigner中的Cardinality基数理解
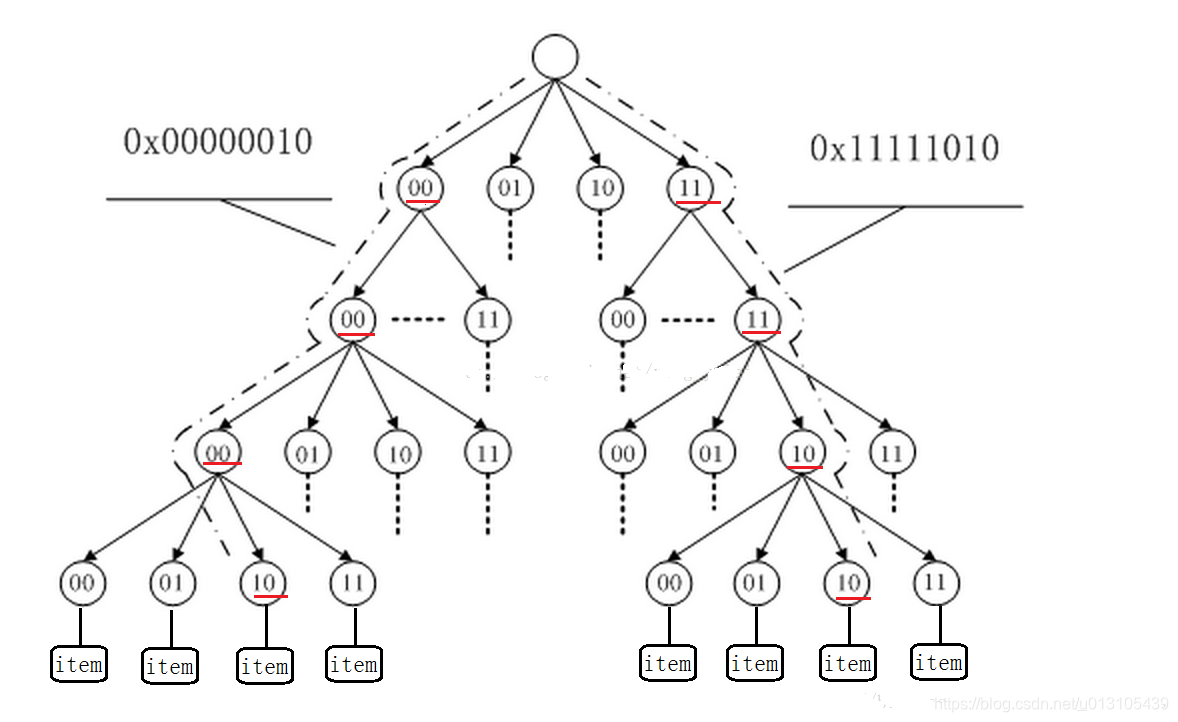
原文链接:http://blog.sina.com.cn/s/blog_9bbafb790101bxwj.html 基数(Cardinality)用实体间实例的数值对应关系表示,它反映了两个实体间的数值联系,它从父实体的角度描述了一对实体间的数量维度,换句话说,基数中的数字是描述父实体在子表中可能出现的次数范围,基数实际是1个闭区间。基数可能是: (1)0,1 一个父实体,在子表中可能出现1

【数据结构】排序算法大全(快速、堆、归并、插入、折半、希尔、冒泡、计数、基数)各算法比较、解析+完整代码
文章目录 八、排序1.插入排序1.1 直接插入排序1.2 折半插入排序1.3 希尔排序 2.交换排序2.1 冒泡排序2.2 快速排序 3.选择排序3.1 简单选择排序3.2 堆3.2.1 堆排序3.2.2 堆插入删除*完善代码 堆 4.归并、基数、计数排序4.1 归并排序4.2 基数排序4.3 计数排序 5.内部排序算法的比较*完整代码 排序 八、排序 1.插入排序 1.1

redis特殊数据类型-Hyperloglog(基数统计)用法
一,Hyperloglog介绍 Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLo
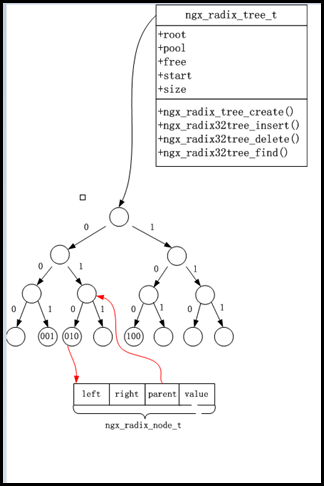
菜鸟nginx源码剖析数据结构篇(五) 基数树 ngx_radix_tree_t
分类: Server - 菜鸟nginx源码剖析 2014-10-28 17:20 8388人阅读 评论(3) 收藏 举报 基数树 nginx 剖析 源码 radix_tree 目录(?)[+] 菜鸟nginx源码剖析数据结构篇(五) 基数树 ngx_radix_tree_t Author:Echo Chen(陈斌) Email:ch

SQL优化必懂概念(一):基数
某个列唯一键(Distinct_ Keys)的数量叫作基数。 比如性别列, 该列只有男女之分, 所以 这一列基数是2。主键列的基数等于表的总行数。基数的高低影响列的数据分布。一般选择性大于20%的就是均匀分布的。 求一个表总行数: Select count(*) from table; 求一个列基数: Select count(distinct colname) from table;S

StarRocks加速查询——低基数全局字典
前言 StarRocks-2.0引入了低基数全局字典,可以通过全局字典将字符串的相关操作转换成整型相关操作,极大提升了查询性能。StarRocks 2.0+后的版本默认会开启低基数字典优化。 一、低基数字典 对于利用整型替代字符串进行处理,通常使用字典编码进行优化。一个 SQL 从输入到输出结果,往往会经过这几个步骤,几乎每一个阶段都可以使用字典优化:Scan,Filter,A
高基数类别特征预处理:平均数编码(目标编码)
高基数类别特征预处理:平均数编码 参考:高基数类别特征预处理:平均数编码 1、引言 对于一个类别特征,如果这个特征的取值非常多,则称它为高基数(high-cardinality)类别特征。在深度学习场景中,对于类别特征我们一般采用Embedding的方式,通过预训练或直接训练的方式将类别特征值编码成向量。在经典机器学习场景中,对于有序类别特征,我们可以使用LabelEncoder进行编码处理

探秘HyperLogLog:Redis中的基数统计黑科技
欢迎来到我的博客,代码的世界里,每一行都是一个故事 探秘HyperLogLog:Redis中的基数统计黑科技 前言HyperLogLog简介基数和基数统计的重要性HyperLogLog的历史和革命性 HyperLogLog的工作原理哈希函数线性计数与对数计数HyperLogLog的核心算法概率和统计原理 在redis中的实现创建和添加元素:PFADD计算基数:PF
108. Python语言 的 项目前导(上) 之 Redis 第九章 :Redis 的 基数统计算法 —— HyperLogLog
Redis 的 基数统计算法 —— HyperLogLog 本章主题关键词为什么要使用 HyperLogLog?HyperLogLog 介绍基础使用添加元素总结小便条 本章主题 关键词 为什么要使用 HyperLogLog? 在我们实际开发的过程中,可能会遇到这样一个问题,当我们需要统计一个大型网站的独立访问次数时,该用什么的类型来统计? 如

特征工程中对高基数类别特征的一种处理方法:特征哈希(FeatureHasher)
在数据挖掘的项目中经常会遇到一类尴尬的特征:高基数类别特征。那么什么是高基数类别特征呢?举个例子,比如像邮编、街道、产品货号等表示类别的特征,它们的基数很大,可能会有数十甚至数百个属性值。对于这种高基数类别特征确实有种“弃之可惜,食之无味”的尴尬。 如果用独热编码的话,对于这种高基数类别特征会产生出数十甚至数百个新特征,造成一个新的问题:特征冗余或维度爆炸。当然根据具体的业务场景可能会存在比
排序 | 冒泡 插入 希尔 选择 堆 快排 归并 非递归 计数 基数 排序
排序 | 冒泡 插入 希尔 选择 堆 快排 归并 非递归 计数 基数 排序 文章目录 排序 | 冒泡 插入 希尔 选择 堆 快排 归并 非递归 计数 基数 排序前言:冒泡排序插入排序希尔排序选择排序堆排序快速排序--交换排序三数取中快速排序hoare版本快速排序挖坑法快速排序前后指针法 快速排序--非递归实现归并排序归并排序非递归实现非比较排序【计数排序】基数排序排序算法复杂度及稳定性分析
排序 | 冒泡 插入 希尔 选择 堆 快排 归并 非递归 计数 基数 排序
排序 | 冒泡 插入 希尔 选择 堆 快排 归并 非递归 计数 基数 排序 文章目录 排序 | 冒泡 插入 希尔 选择 堆 快排 归并 非递归 计数 基数 排序前言:冒泡排序插入排序希尔排序选择排序堆排序快速排序--交换排序三数取中快速排序hoare版本快速排序挖坑法快速排序前后指针法 快速排序--非递归实现归并排序归并排序非递归实现非比较排序【计数排序】基数排序排序算法复杂度及稳定性分析

【算法导论】排序 (四):决策树、线性时间排序(计数、基数、桶排序)
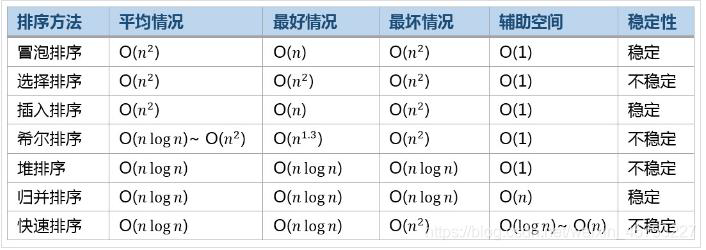
到目前为止,一共整理总结了五大排序算法: 1、插入排序 2、冒泡排序、选择排序、交换排序(把这三种方法归为一种,因为他们的思想本质上都是一样的) 3、归并排序 4、堆排序 5、快速排序 以上五种排序都可以称为“比较排序”,顾名思义,因为他们都是基于比较元素来决定其相对位置的。 其中前两种的时间为O(n^2),归并排序和堆排序最坏O( n lg n ),快排平均O( n lg
3.3.17内核基数树radix_tree源码解析与示例分析
文章目录 基数树定义结构体slotstags 接口初始化静态动态系统 插入删除查找 示例示例1示例2 参考 基数树 Linux基数树(radix tree)是将long整数键值与指针相关联的机制,它存储有效率,并且可快速查询,用于整数值与指针的映射,在内核代码中,使用基数树最多的场景是:IDR机制和内存管理等。 定义 结构体
3.3.17内核基数树radix_tree源码解析与示例分析
文章目录 基数树定义结构体slotstags 接口初始化静态动态系统 插入删除查找 示例示例1示例2 参考 基数树 Linux基数树(radix tree)是将long整数键值与指针相关联的机制,它存储有效率,并且可快速查询,用于整数值与指针的映射,在内核代码中,使用基数树最多的场景是:IDR机制和内存管理等。 定义 结构体

快速排序在排标兵时,为什么需要从基数的对面开始?
今天周末,复习了一下快速排序的实现。我在手写实现的过程中,基数取的是低指针的值,但是我在开始排标签时,先从左边的开始排,导致结果错了。 我就很纳闷,为什么不可以从相同的方向开始排,一定要从基数的对面开始? 于是乎我看了一下排序的过程,发现确实会发生数据错乱。 我上网查了一下,绝大多数的回答都是同一篇,那篇回答也只是帮忙捋了一下排序的过程,然后证明不行。但是我感觉没有说到点上。 我自己思索了