基尼专题

编程实现基于信息熵/基尼指数划分选择的决策树算法
编程实现基于信息熵/基尼指数划分选择的决策树算法 手动建立一个csv文件 #csv的内容为Idx,color,root,knocks,texture,navel,touch,density,sugar_ratio,label1,dark_green,curl_up,little_heavily,distinct,sinking,hard_smooth,0.697,0.46,12,b

CART决策树-基尼指数(全网最详解)
文章目录 一、基尼指数的定义二、基尼指数在CART决策树中的应用三、基尼指数与CART决策树的构建1.计算每个子集的基尼系数:2.计算基尼指数3.选择最优特征4.其余基尼指数5.构建决策树 四、总结 CART决策树基尼指数是CART(Classification And Regression Tree)算法中用于分类任务的一种评估指标,主要用于衡量数据集的不纯度或不确定性。以下是关于
![[机器学习] 第四章 决策树 1.ID3(信息增益) C4.5(信息增益率) Cart(基尼指数)](/front/images/it_default.gif)
[机器学习] 第四章 决策树 1.ID3(信息增益) C4.5(信息增益率) Cart(基尼指数)
参考:https://www.cnblogs.com/liuq/p/9927580.html 参考:https 文章目录 一、ID3 算法信息熵🌟信息增益互信息与信息增益的关系例子优缺点 停止分裂的条件Python代码 二、 C4.5 算法🌟信息增益率 三、Cart🌟基尼指数例子🍇 数据集的选取🍇

Numpy 实现基尼指数算法的决策树
基尼系数实现决策树 基尼指数 Gini ( D ) = 1 − ∑ k = 1 K ( ∣ C k ∣ ∣ D ∣ ) 2 \operatorname{Gini}(D)=1-\sum_{k=1}^{K}\left(\frac{\left|C_{k}\right|}{|D|}\right)^{2} Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2 特征 A A A条件下集合 D

《统计学习方法》第5章Python3实现(二)基尼指数
2019独角兽企业重金招聘Python工程师标准>>> 代码依赖于上次的代码中的例子,连接为《统计学习方法》第5章Python3实现(一) 熵、条件熵、信息增益、信息增益比 计算基尼指数的代码如下: """CART: Classification And Regression TreeCreated on Dec 28th,2018@author:Aomo Jan"""def c

pyhton_基尼指数计算
1.定义:基尼指数(基尼不纯度):表示在样本集合中一个随机选中的样本被分错的概率。 注意: Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。 def gini_index_single(a,b):single_gini = 1 - ((a/(a+b))**2) - ((b/(a+b))**2)return round(single

小孩都看得懂的基尼不纯度
全文共 1343 字,16 幅图, 预计阅读时间 8 分钟。 本文是「小孩都看得懂」系列的第十一篇,本系列的特点是极少公式,没有代码,只有图画,只有故事。内容不长,碎片时间完全可以看完,但我背后付出的心血却不少。喜欢就好! 小孩都看得懂的神经网络小孩都看得懂的推荐系统小孩都看得懂的逐步提升小孩都看得懂的聚类小孩都看得懂的主成分分析小孩都看得懂的循环神经网络小孩都看得懂的 Embedding小孩
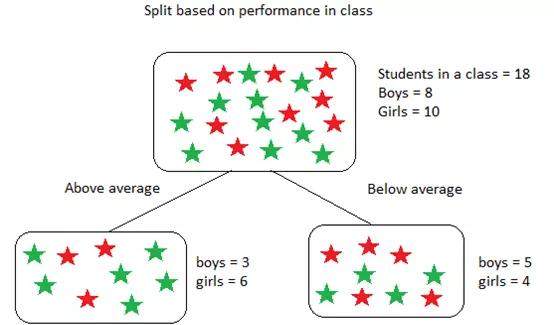
基尼不纯度:如何用它建立决策树?
全文共1031字,预计学习时长3分钟 图源:unsplash 决策树是机器学习中使用的最流行和功能最强大的分类算法之一。顾名思义,决策树用于根据给定的数据集做出决策。也就是说,它有助于选择适当的特征以将树分成类似于人类思维脉络的子部分。 为了有效地构建决策树,我们使用了熵/信息增益和基尼不纯度的概念。让我们看看什么是基尼不纯度,以及如何将其用于构建决策树吧。 什么是基尼不纯度?