取小红书专题

nodejs爬取小红书图片
昨天的文章已经描述了可以抓取评论区内容, 抓取图片内容和抓取评论区的内容基本一致 我们可以看到接口信息中含有图片链接,我们要做的就是爬取图片链接然后下载 这边要用到的模块为const download=require('download') 将爬到的图片链接存放到images数组并新建images文件夹(当前为空) 使用
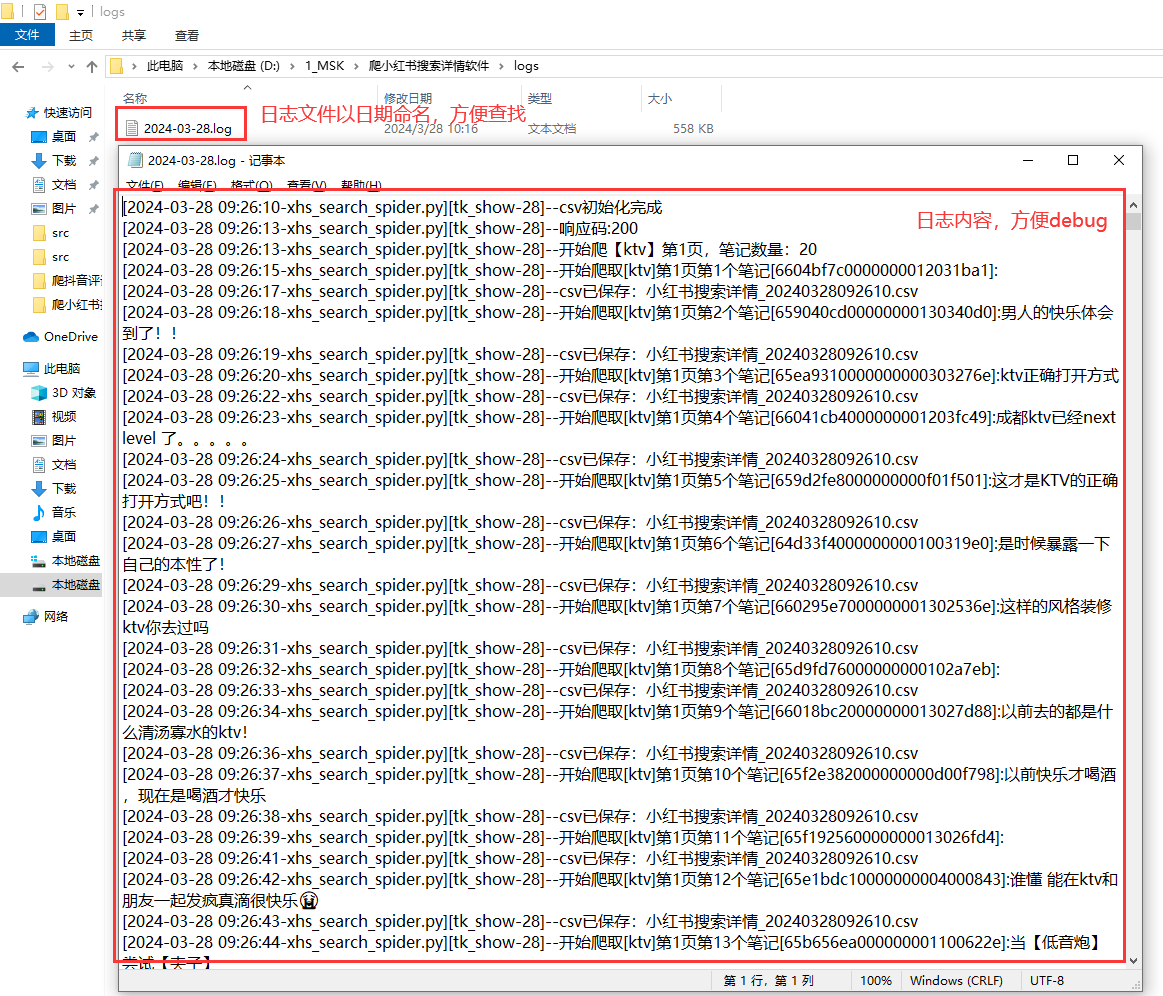
【小红书采集软件】根据关键词批量爬取小红书笔记正文、笔记链接、发布时间、转评赞藏等
一、背景介绍 1.1 爬取目标 熟悉我的小伙伴可能了解,我之前开发过2款软件: 【GUI软件】小红书搜索结果批量采集,支持多个关键词同时抓取! 【GUI软件】小红书详情数据批量采集,含笔记内容、转评赞藏等,支持多笔记同时采集! 现在介绍的这个软件,相当于以上2个软件的结合版,即根据关键词爬取笔记的详情数据。 开发界面软件的目的:方便不懂编程代码的小白用户使用,无需安装python

Golang Colly批量爬取小红书图片
语言:Golang 库:Iris/Colly 先看输入日志: Saved file: images\20240428190531_2_0.jpg It is image 20240428190532_2_1.jpg Saved file: images\20240428190532_2_1.jpg It is image 20240428190533_2_2.jpg Saved fil

Python实战:爬取小红书-采集笔记详情
上一篇文章发出后,有读者问能不能爬到小红书笔记详情数据,今天他来了。 一、先看效果 程序输入:在一个txt文件内粘贴要爬取的笔记链接,每行放1个链接。 程序输出:输出是一个所有笔记详情数据的excel表格,包含”采集日期、作者、笔记标题、发布日期、IP属地、点赞数、收藏数、评论数、笔记链接、作者链接、标签、笔记内容“这些字段,和网页端看到的数据一样。 保存的 excel
Python实战:爬取小红书
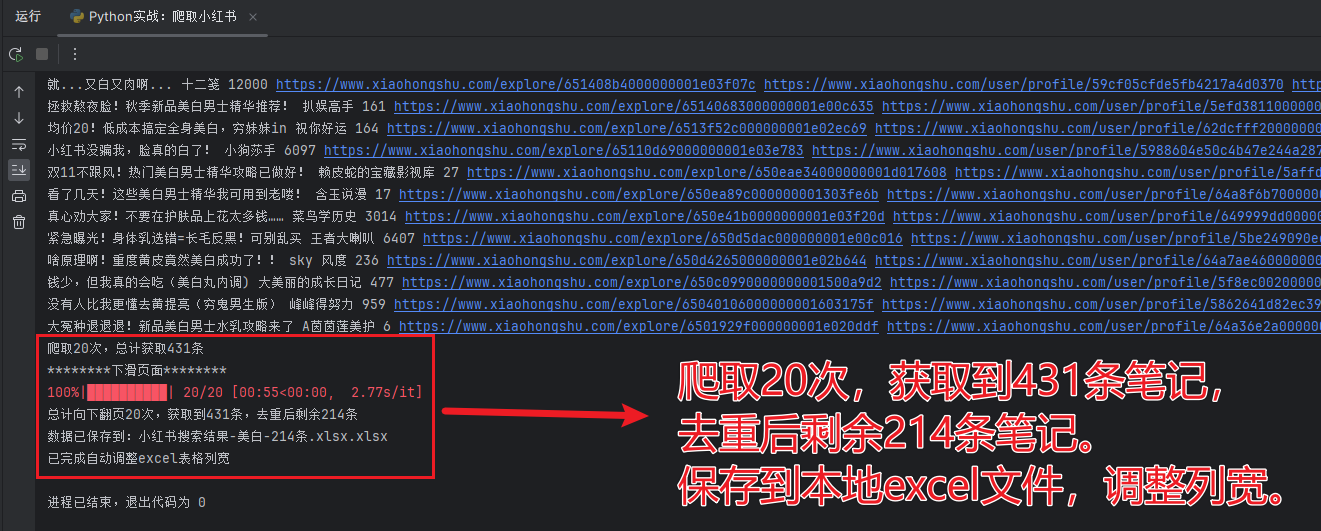
有读者在公众号后台询问爬取小红书,今天他来了。 本文可以根据关键词,在小红书搜索相关笔记,并保存为excel表格。 爬取的字段包括笔记标题、作者、笔记链接、作者主页地址、作者头像、点赞量。 一、先看效果 1、爬取搜索页 2、爬取结果保存到本地excel表格 运行我写的爬虫,实验了几十次,都可以顺利爬到数据,每次大概可以爬取到 200 条笔记保存到 excel 表格。 遇到
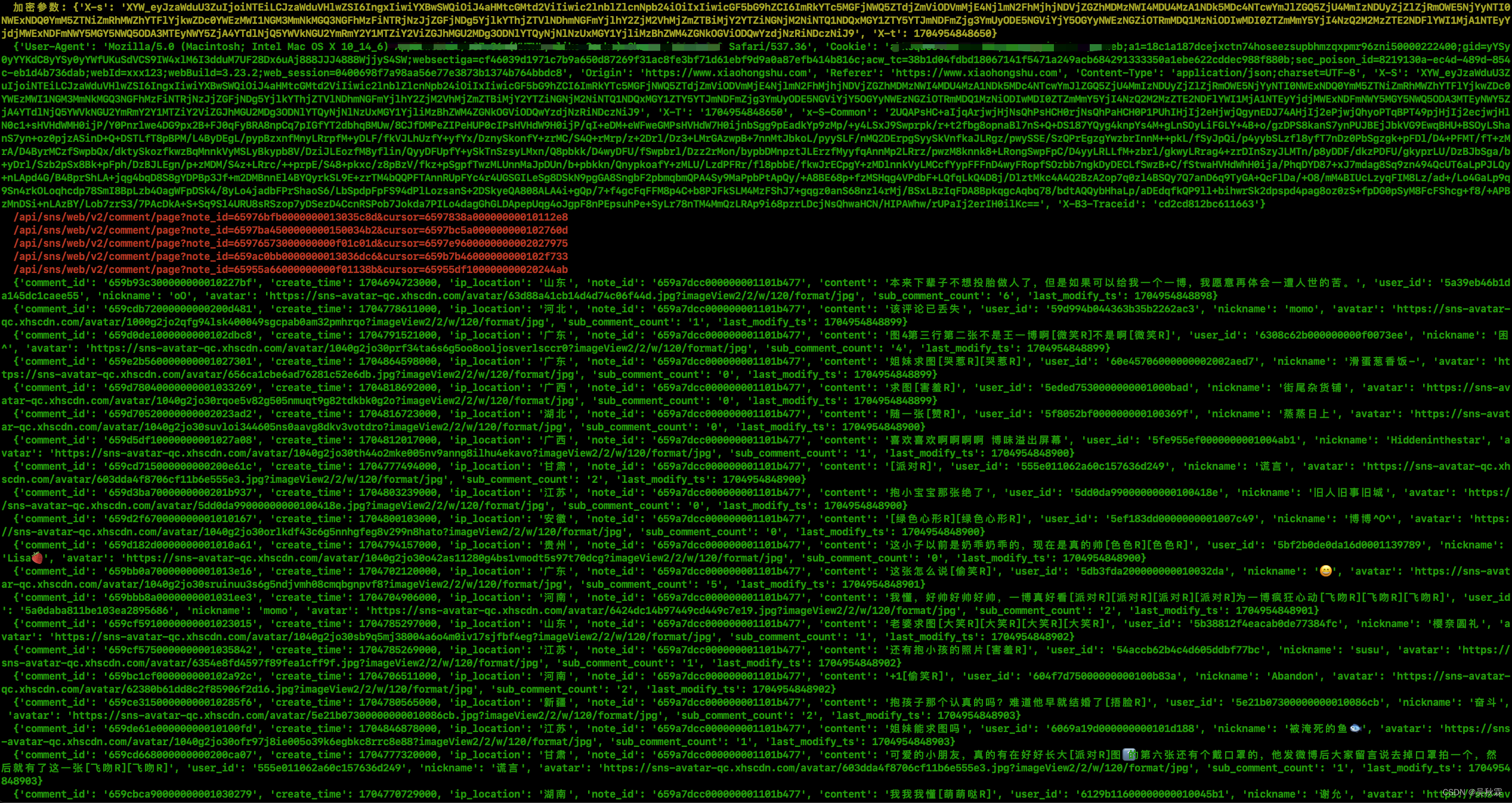
使用Python爬取小红书笔记与评论(js注入方式获取x-s)
文章目录 1. 写在前面2. 分析加密入口3. 使用JS注入4. 爬虫工程化 【作者主页】:吴秋霖 【作者介绍】:Python领域优质创作者、阿里云博客专家、华为云享专家。长期致力于Python与爬虫领域研究与开发工作! 【作者推荐】:对JS逆向感兴趣的朋友可以关注《爬虫JS逆向实战》,对分布式爬虫平台感兴趣的朋友可以关注《分布式爬虫平台搭建与开发实战》 还有未来会持续更新的验证