本文主要是介绍Python实战:爬取小红书-采集笔记详情,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上一篇文章发出后,有读者问能不能爬到小红书笔记详情数据,今天他来了。
一、先看效果
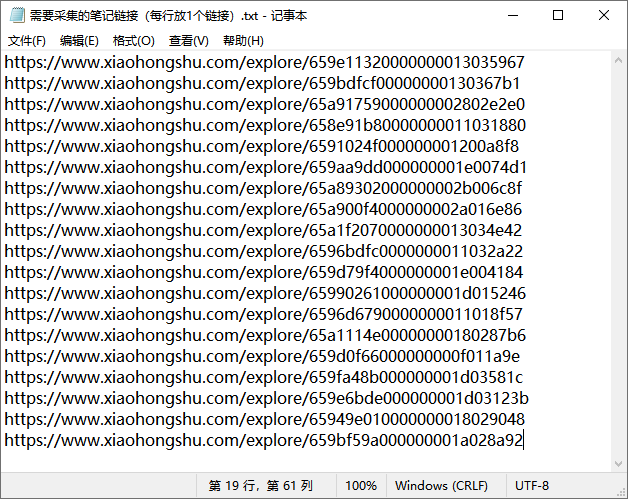
程序输入:在一个txt文件内粘贴要爬取的笔记链接,每行放1个链接。
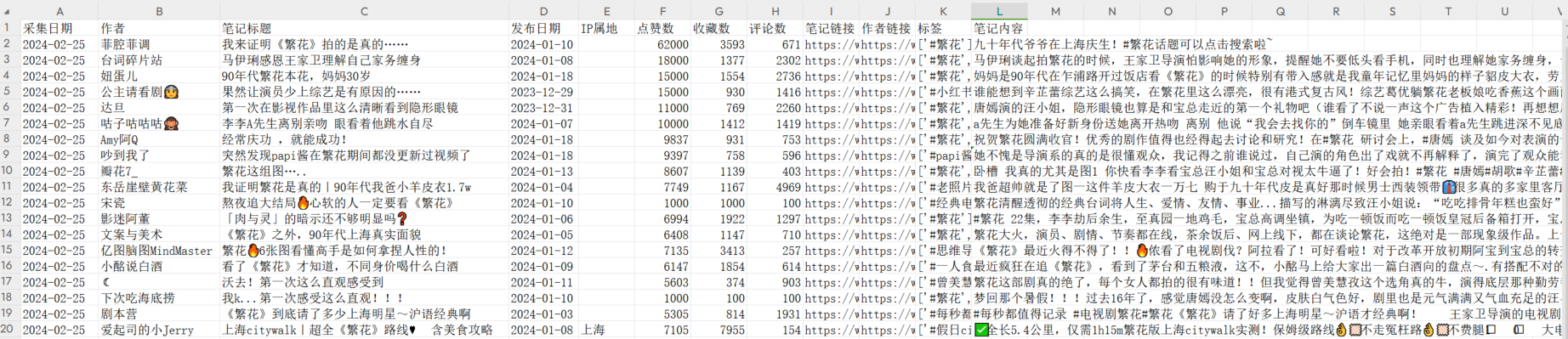
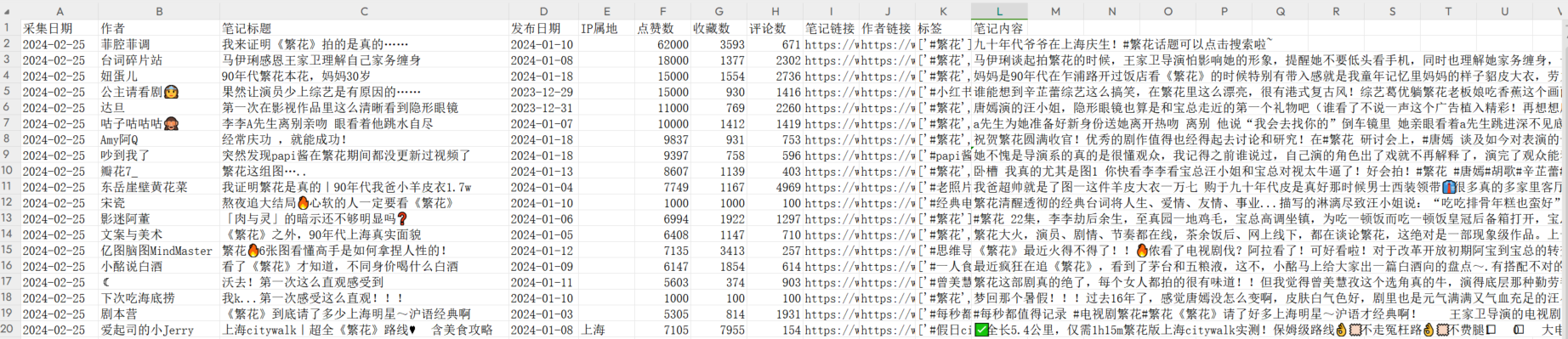
程序输出:输出是一个所有笔记详情数据的excel表格,包含”采集日期、作者、笔记标题、发布日期、IP属地、点赞数、收藏数、评论数、笔记链接、作者链接、标签、笔记内容“这些字段,和网页端看到的数据一样。
保存的 excel 表如下:
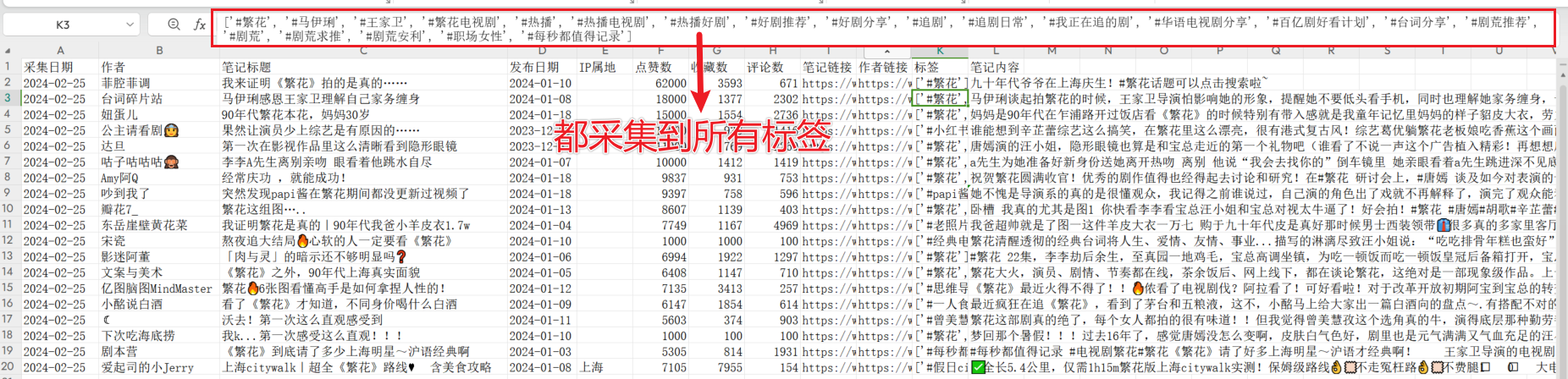
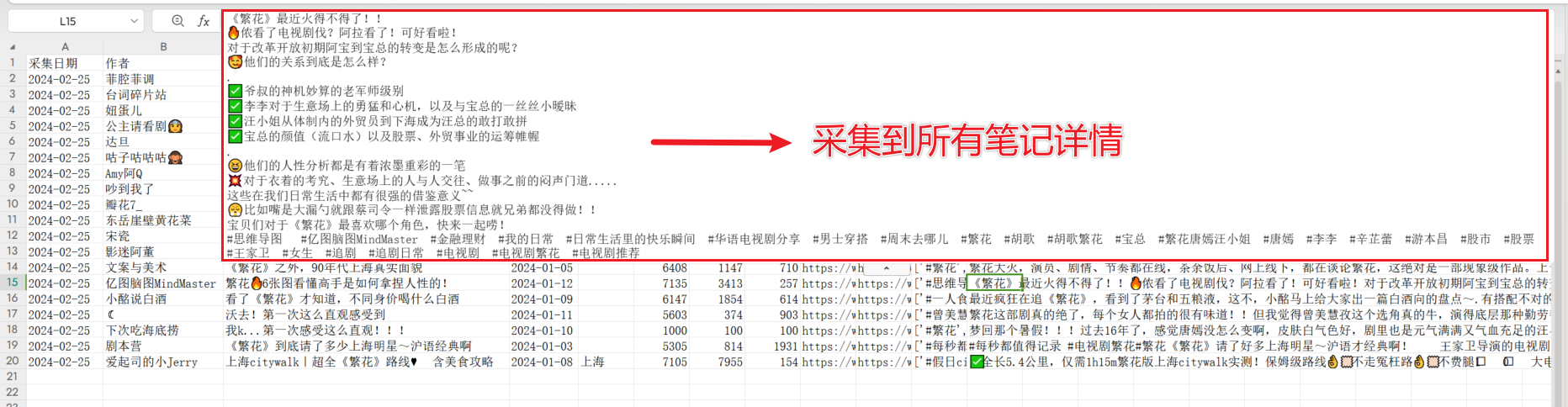
采集到的全部标签如下:
采集到的全部笔记内容如下:
二、分析思路
由于小红书反爬机制很严格,很难批量获取小红书的大量数据。用爬虫去爬小红书数据,还有被小红书封号的风险。
但是我这个方法是纯模拟人的操作,以人的操作习惯去查看笔记和提取数据,不会触发小红书的反爬机制。
分析爬虫思路,概括如下:
1、登录小红书
2、从 txt 文件中读取所有笔记链接
3、逐条根据笔记链接打开小红书笔记详情页
4、提取笔记页面数据
5、处理获取到的数据,写入缓存
6、循环爬取所有笔记链接
7、保存缓存内的数据到本地 excel 文件
三、开始写代码
1、登录
使用 DrissionPage 库,打开小红书主页https://www.xiaohongshu.com,设置 20 秒延时,这时可以使用手机扫码登录账号。
from DrissionPage import ChromiumPage
def sign_in():sign_in_page = ChromiumPage()sign_in_page.get('https://www.xiaohongshu.com')print("请扫码登录")# 第一次运行需要扫码登录time.sleep(20)
只有第 1 次运行代码需要登录,浏览器会保存登录状态信息。第 2 次之后再运行代码,就免登录了,可以把 sign_in()步骤注释掉。
运行过我上一篇文章的代码,浏览器已经保存登录状态了,也可以直接注释掉登录步骤。
2、从txt文件中读取所有笔记链接
定义一个read_urls_from_txt(path)函数,函数的参数是 txt 文件路径,执行函数返回一个列表,包含所有 urls。
def read_urls_from_txt(path):with open(path, 'r') as file:urls = [line.strip() for line in file.readlines()]return urls
3、打开小红书笔记详情页
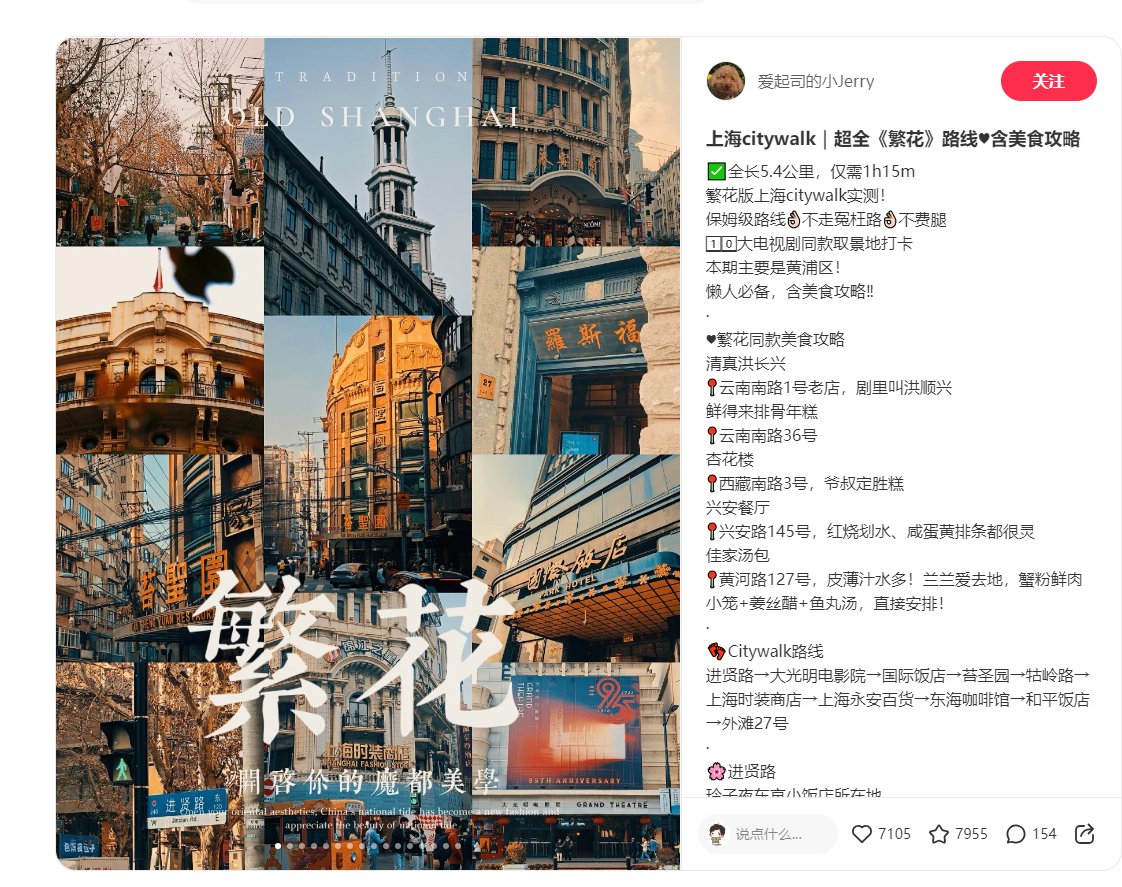
打开每个 url 的网页,可以看到浏览器已经加载出来笔记的信息了。
def open_url(url):global pagepage = ChromiumPage()# page.set.load_mode.eager()page.get(f'{url}')
4、提取页面数据
使用 DrissionPage 库定位元素方法,定位到包含笔记详情的 作者、标题、点赞 等信息。
例如,定义一个get_author_info(page)函数,提取作者信息,函数返回author_info字典,包含作者名字和作者主页链接。
def get_author_info(page):# 定位作者信息div_author = page.ele('.author-container', timeout=0)div_info = div_author.ele('.info', timeout=0)# 作者名字author_name = div_info.ele('.username', timeout=0).text# 作者主页链接author_link = div_info.eles('tag:a', timeout=0)[0].linkauthor_info = {'author_name': author_name, 'author_link': author_link}return author_info
类似的,定义get_note_content(page)函数提取笔记内容、标签、链接、发布日期、IP 属地数据,get_count(page)函数提取点赞、收藏、转发数据。
5、处理获取到的数据,写入缓存
今天使用一个新的库来保存数据——DataRecorder库,这个库也是由DrissionPage库同作者开源的。
在上一篇文章中,DrissionPage开源作者给我留言,我才发现这个库,用起来真方便。我还有缘加到了大佬的微信,太幸运了。
DataRecorder库是一个基于 python 的工具集,用于记录数据到文件。使用方便,代码简洁,是一个可靠、省心且实用的工具。
DataRecorder库目前在码云上 Star 数还不高,在这里推荐一下,非常适合配合爬虫使用。

from DataRecorder import Recorder
# 新建一个excel表格,用来保存数据
r = Recorder(path='采集输出-小红书笔记详情.xlsx', cache_size=20)
#数据写入缓存
new_note_contents_dict = {'采集日期': current_date, '作者': author_name, '笔记标题': note_title,'发布日期': date, 'IP属地': location, '点赞数': like_count,'收藏数': collect_count, '评论数': chat_count, '笔记链接': note_link,'作者链接': author_link, '标签': tags, '笔记内容': note_desc}
r.add_data(new_note_contents_dict)
6、循环爬取所有笔记链接
使用 tqdm库 显示爬取进度条,在循环体内,循环调用 get_note_page_info(note_url) 函数采集笔记页面信息。
for note_url in tqdm(note_urls):get_note_page_info(note_url)
其中 get_note_page_info(url) 函数如下,实现采集作者信息、笔记内容、点赞、收藏、评论数的功能。
def get_note_page_info(url):# 访问urlopen_url(url)# 提取作者信息author_info = get_author_info(page)# 提取笔记内容content = get_note_content(page)# 提取点赞、收藏、评论数count = get_count(page)note_contents = {'note_link': url, 'author_info': author_info, 'content': content, 'count': count}
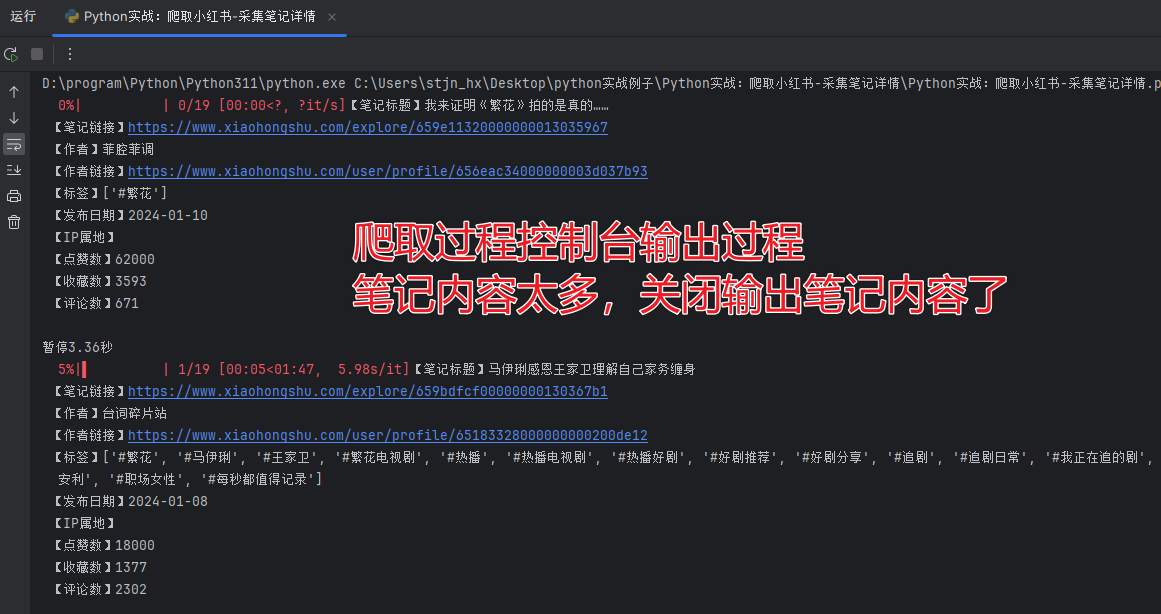
Pycharm 控制台输出如下:
7、保存缓存内的数据到本地 excel 文件
使用 DataRecorder库 将数据保存到 excel 文件,用了这个库真的很省心。
from DataRecorder import Recorder
# 新建一个excel表格,用来保存数据
r = Recorder(path='采集输出-小红书笔记详情.xlsx', cache_size=20)
#数据写入缓存
r.add_data(new_note_contents_dict)
# 获取当前日期
current_date = date.today()
# 保存excel文件
r.record(f'采集输出-小红书笔记详情-{current_date}.xlsx')
保存的 excel 文件如下:
四、录屏
以一个爬取过程为例,录屏如下:
插入视频
视频地址 https://www.bilibili.com/video/BV1hu4m1w7Qt
五、全部代码
由于代码太长,在这里只给出主函数代码,有兴趣的读者可以根据上述信息自己补全代码。
主函数代码如下:
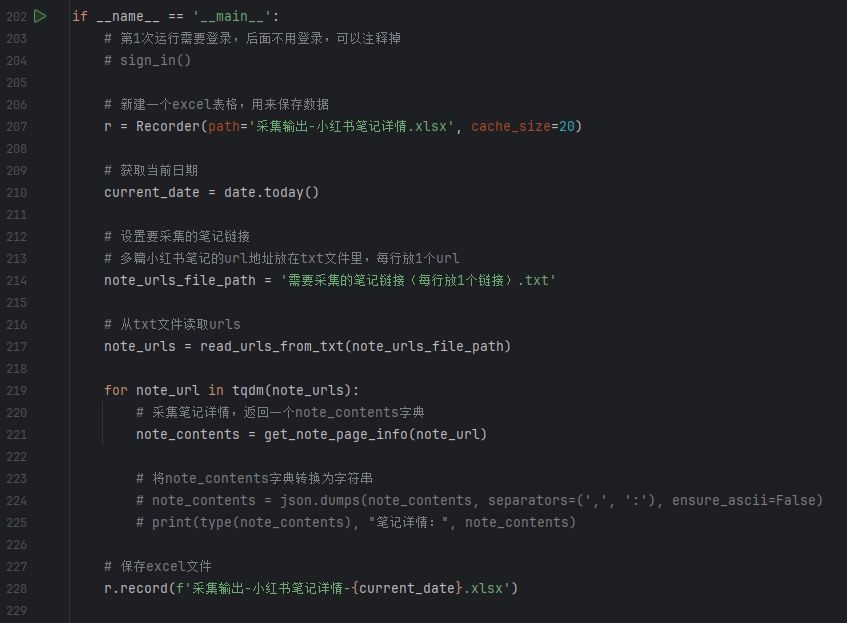
if __name__ == '__main__':# 第1次运行需要登录,后面不用登录,可以注释掉# sign_in()# 新建一个excel表格,用来保存数据r = Recorder(path='采集输出-小红书笔记详情.xlsx', cache_size=20)# 获取当前日期current_date = date.today()# 设置要采集的笔记链接# 多篇小红书笔记的url地址放在txt文件里,每行放1个urlnote_urls_file_path = '需要采集的笔记链接(每行放1个链接).txt'# 从txt文件读取urlsnote_urls = read_urls_from_txt(note_urls_file_path)for note_url in tqdm(note_urls):# 采集笔记详情,返回一个note_contents字典note_contents = get_note_page_info(note_url)# 将note_contents字典转换为字符串# note_contents = json.dumps(note_contents, separators=(',', ':'), ensure_ascii=False)# print(type(note_contents), "笔记详情:", note_contents)# 保存excel文件r.record(f'采集输出-小红书笔记详情-{current_date}.xlsx')
主函数截图如下:
六、总结
小红书是商业化很成功的平台,很多创业者在研究小红书流量。
上一篇文章发出后,效果很好,我结交了一些朋友,也赚到了一些睡后收入。
有很多读者在公众号后台加我微信,既有学生,也有创业者、小红书运营,还有开源作者、腾讯的小伙伴以及出版社老师,很开心能结交一些朋友。
七、获取完整源码
小红书的数据应该很有价值,特别有兴趣的小伙伴可以在公众号后台私聊我,以一杯咖啡的小红包获取全部代码(毕竟我写代码、调试代码几个晚上~~~)。
我的这个代码,调试的很好,运行几十次还没出过问题。可以帮助你获取对标博主的创作风格,有重点的分析和学习。
福利:上一篇文章承诺前 5 名读者付费可以获取后续更新的代码,说到做到,本篇完整源码免费送给这 5 位读者。
本篇继续放出 5 个名额,前 5 名购买读者可以免费获得后续更新代码。
每一份能满足他人需求的努力都值得被付费。
部分读者交流如下:

本文首发在“程序员coding”公众号,欢迎关注与我一起交流学习。还可以通过公众号添加我的私人微信。
这篇关于Python实战:爬取小红书-采集笔记详情的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





