本文主要是介绍如何爬取小红书文章,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
纯技术研究分享
先说思路,正常小红书的文章,如果想通过网页爬取,需要知道文章的id,
例如:‘https://www.xiaohongshu.com/explore/64bbad45000000001700d709’
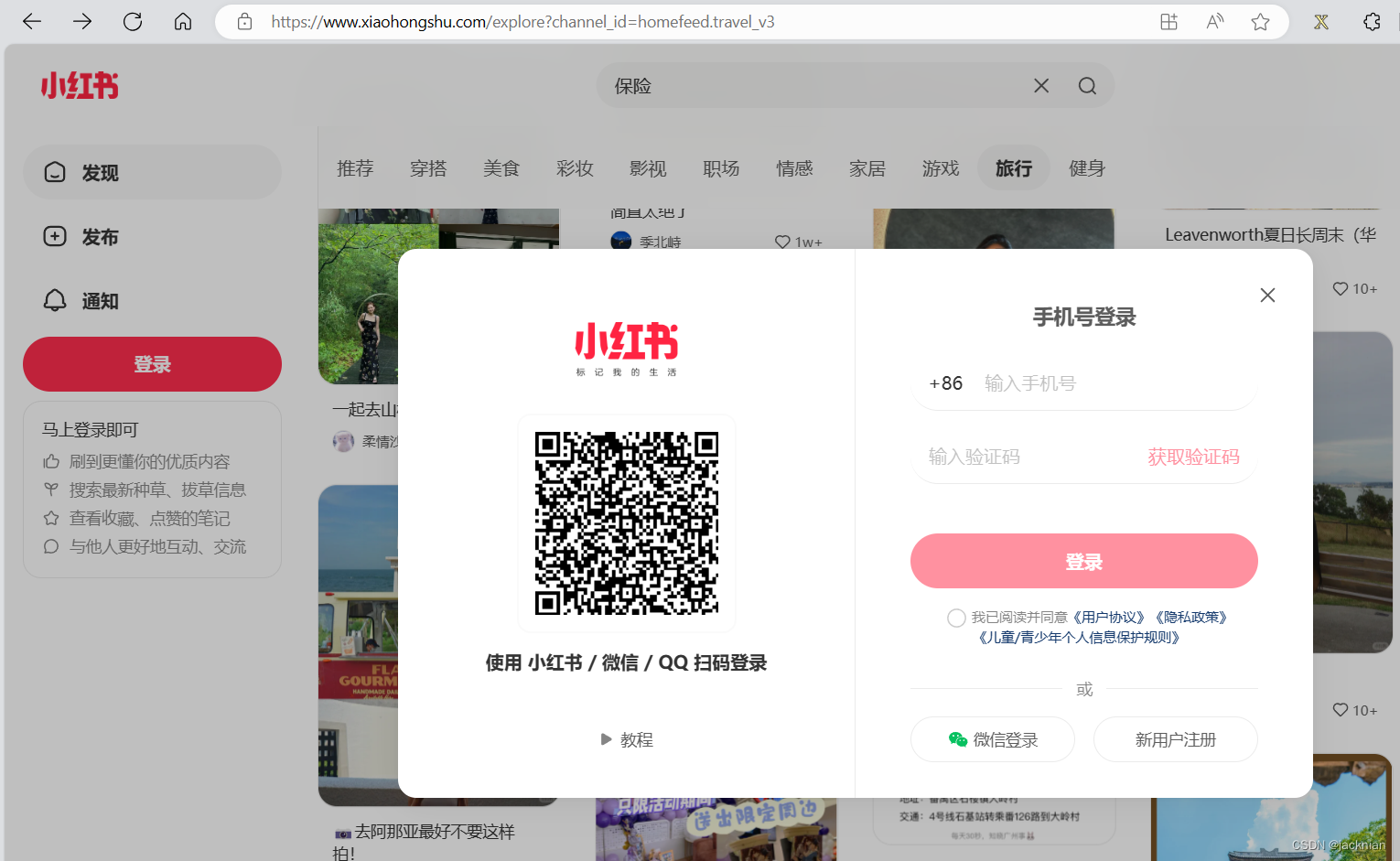
网页端爬取:
1.思路是通过无头浏览器,利用python就可以模拟账号验证码登录,这个有点麻烦,也可以把二维码截图,拍了发到企业微信(助手)群里,收到的时候扫码(容易封号)登录
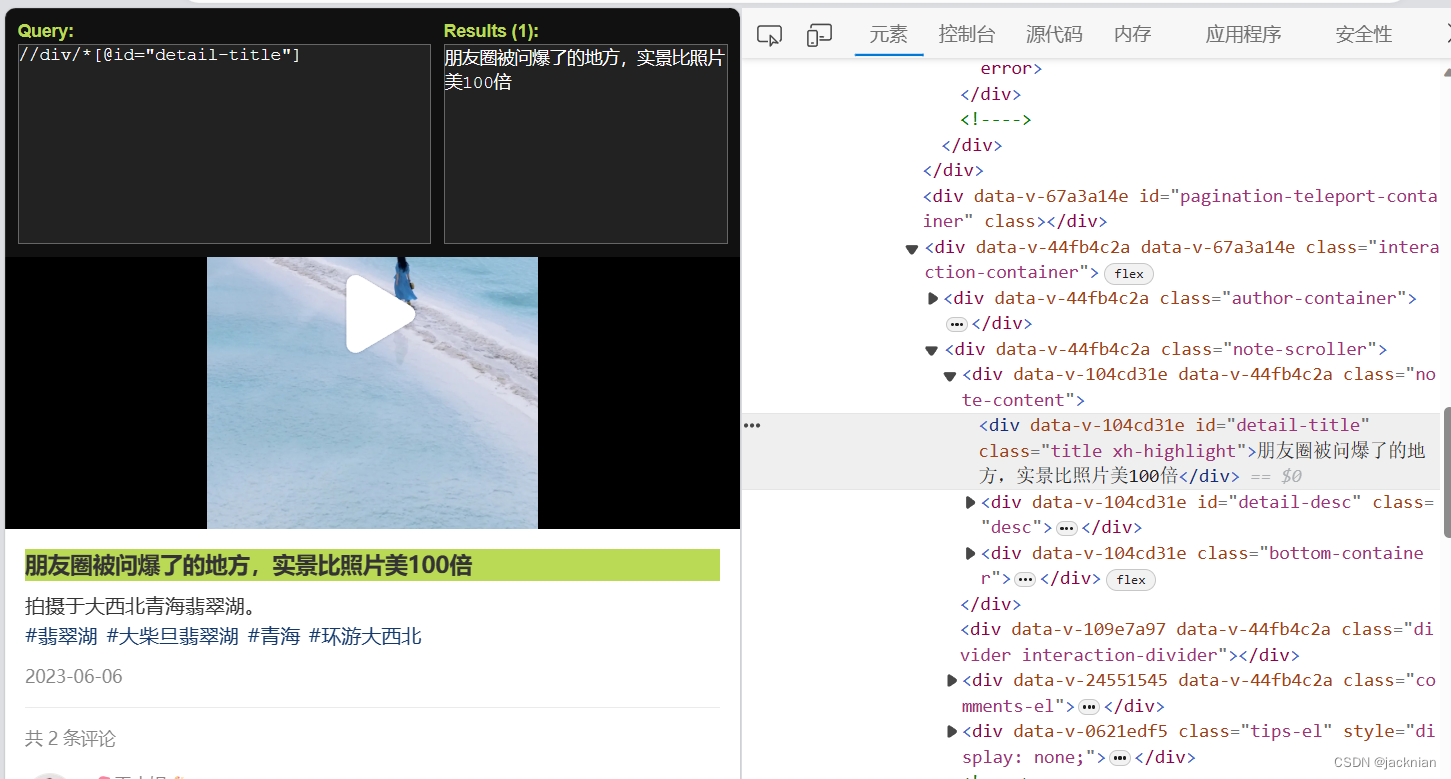
可以用搜索的方式找到你要的文章或者视频资源。
这个是找标题,图片和视频也是类似的方法//div/*[@id="detail-title"]
爬到后就可以自己存入mysql或者mongodb,这里不得不提一下,小红书的图片尽然没加水印,这就造成了很多的原文章被数据公司窃取的风险,最近看到小红书的图片改成webp格式了,估计也快了。
方法2:
用安卓app写一个模拟操作的程序,可以模拟用户登录,然后搜索你要的信息,爬取文章的接口
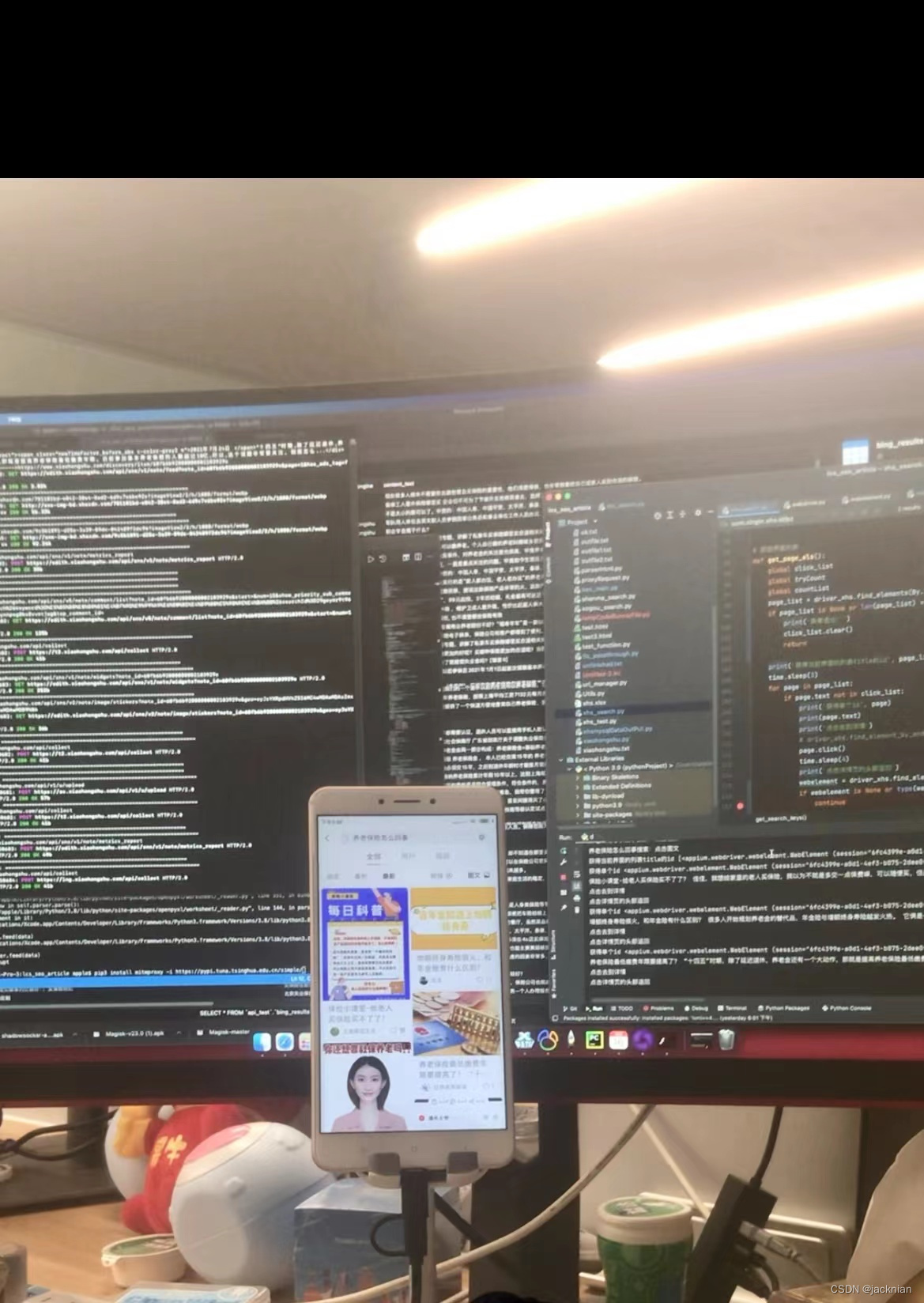
抓安卓的网络包,方法还是python的selenium,webdriver安卓辅助模式,存mysql。都有封号的风险,最好使用代理,切换一下账号。
3.思路三,是用微信小程序的文章列表爬取,这个比较容易点。
以上是目前能用的方式,都有封号的风险,作为技术研究可以交流,商业应用涉及小红书公司信息安全,以上均为学习经验,不要用于商业,不要用于商业,不要用于商业。
这篇关于如何爬取小红书文章的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!