利用率专题

prometheus cAdvisor 监控docker CPU利用率 教程
一、方案 1. 背景 promethus,原理是获取所有全量标签,然后按需过滤 监控Docker容器,Prometheus提供了几种方法来监控Docker,包括一些自定义exporter。 然而,这些exporter一般都不会用到,推荐的方法是使用Google的cAdvisor工具。 在Docker守护进程上,cAdvisor作为Docker容器运行,单个cAdvisor容器返回针对Do

一个利用率超高的大数据实验室是如何练成的?
在当今这个数据爆炸的时代,大数据已成为推动各行各业创新与发展的核心动力。一个高效运转、利用率超高的大数据实验室,不仅是技术创新的摇篮,更是企业竞争力的重要体现。那么,如何构建并维持这样一个实验室呢?本文将探讨如何构建并运营一个高效利用的大数据实验室。 一、科学规划与布局 1.明确目标与定位:实验室的首要任务是确立清晰的研究蓝图,这包括明确其独特的研究方向,如人工智能、金融

java应用响应时间长、吞吐量小、CPU利用率特别高问题定位笔记(一)
环境:一个java应用+tomcat 问题描述:响应时间长、吞吐量小、CPU利用率特别高 如下图所示: 定位分析思路 1)看看占用cpu高的进程中有哪些线程 使用top -Hp pid命令查看 2)使用jstack pid > xxx.txt 将java应用的堆栈信息dump下来 3)更具线程PID查看当前线程在干什么(如下图) 4)根据信息查看代码找到最终问题

通过/proc/stat文件计算CPU的利用率
在linux下,CPU利用率分为 用户态、系统态和空闲态,分别表示CPU处于用户态执行的时间,系统内核执行的时间,和空闲系统进程执行的时间。 CPU使用率:CPU的使用情况 用户时间(User time) 表示CPU执行用户进程的时间,包括nices时间.通常期望用户空间CPU越高越好 系统时间(System time) 表示CPU在内核运行时间,包括IRQ和softirq时间,系统CP

用c++查linux与windows上的显存利用率,内存使用率,cpu占有率,gpu占有率
一、显存利用率 Windows https://blog.csdn.net/paopaoc/article/details/9093125 linux https://blog.csdn.net/paopaoc/article/details/9093125 二、GPU占用率 Windows https://blog.csdn.net/paopaoc/article/details/
【思考】什么是CPU利用率?
在Windows、Linux等操作系统中都可以直观的看到CPU利用率这个系统指标,那么这个指标的本质是什么呢?又是如何计算出来的? 如果要算一台发动机的利用率,可能的算法是“当前转速/极限转速”。类比于CPU的话,那该是“当前处理二进制指令的速度/处理二进制指令的极限速度”。 上面的人算法听起来还挺靠谱的,也完全可以和我们的日常使用体验对应上。不过一细想,“当前速度”可以统计出来,但是“极限速

可抢占的优先级调度算法算例:CPU利用率
某多道程序设计系统配有一台处理器和两台外设IO1、IO2,现有3个优先级由高到低的作业J1、J2和J3都已装入了主存,它们使用资源的先后顺序和占用时间分别是: J1:IO2(30 ms),CPU(10ms),IO1(30ms),CPU(10ms). J2:IO1(20 ms),CPU(20ms),IO2(40ms) J3:CPU(30ms),IO1(20ms) 处理器调度采用可抢占的优先数

【计算机网络篇】数据链路层(8)共享式以太网的退避算法和信道利用率
文章目录 🛸共享式以太网的退避算法🥚截断二进制指数算法 🍔共享式以太网的信道利用率 🛸共享式以太网的退避算法 在使用CSMA/CD协议的共享总线以太网中,正在发送帧的站点一边发送帧一边检测碰撞,当检测到碰撞的时候就停止发送,退避一段随机时间后再重新发送 共享总线以太网中的各站点采用截断二进制指数退避算法来选择退避的随机时间 🥚截断二进制指数算法 如果连
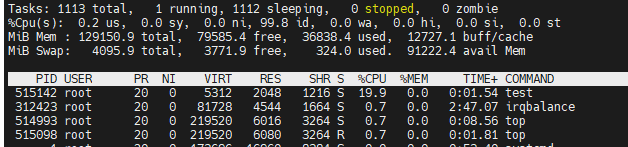
C++实现一个简单的控制cpu利用率的程序
写一个程序,让控制cpu利用率在20%左右 思路很简单:每个循环控制sleep的时间占比 #include <iostream>#include <chrono>#include <unistd.h>int main() {int ratio = 20;int base_time = 1000;int sleeptime = base_time * (100-ratio);int runti
nontamic线程活跃性/利用率更高
nontamic 与atomic 区别 atomic 修饰的对象会保证setter和getter方法的完整性,任何线程访问题都可以得到一个完整的的初始化后的对象。因为要保证完整性,所以比较耗时。相对于nonatomic较为安全。(非绝对安全,多线程资源抢夺也会得到不一样的值, 也得使用@synchronized) nontamic 修饰的对象不会保证setter和getter方法的完整性,任何线
项目中跟踪和提高资源利用率的方法
发展业务和服务是每个组织的首要任务。但是,仅仅把资源分配到项目上并不能确保会有高效率的工作产出。为了达到最高效率,这些资源必须在可以计费的或有战略意义的工作上得到有效利用。 资源利用率是衡量项目是否成功的一个关键指标。通过跟踪资源如何被利用,可以确保组织内的每项资源都被充分使用,从而有助于评估和提升工作效率。 本文将讲解如何利用一些直观的工具来有效地跟踪资源利用情况。 如何计算资源利用率?

apache+tomcat apache线程占满,单各个服务器cpu利用率均特别低
并发量较高的时候(150+),apache的进程数,会迅速的给占满,导致服务无法访问 此时查看cpu,各个服务器的利用率均特别低 查看apache访问日志,发现有几个接口返回慢!怀疑是接口的问题,就对接口做了优化。 优化完成后,稳定了一段时间(半天不到),很快有出现进程数猛的蹿升。于是就怀疑是不是apache的mod_jk里面有参数没有配置好造成的。 于是查看mo
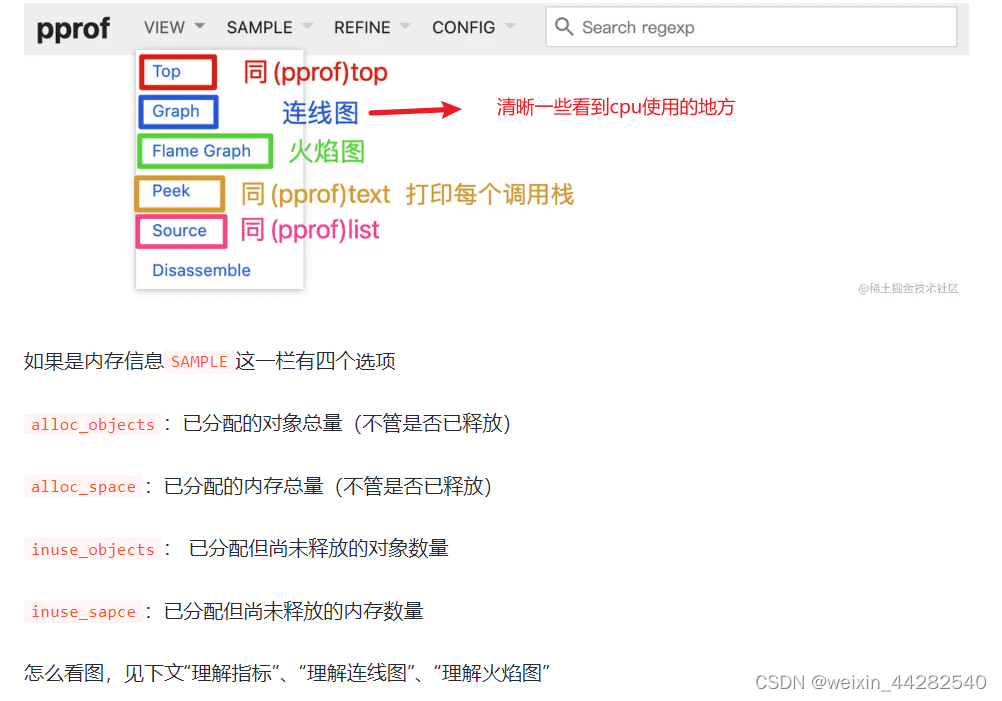
查看项目go代码cpu利用率
1.代码添加: "net/http"_ "net/http/pprof"第二步,在代码开始运行的地方加上go func() {log.Println(http.ListenAndServe(":6060", nil))}() 2.服务器上防火墙把6060打开 3.电脑安装:Download | Graphviz 4.安装后需要配置环境变量: 5.cmd执行下面命令: go too
HDU 4882 ZCC Loves Codefires 还是利用率
题意:给你两组数,a[],b[],设suma是a[i]的前i项,包括第i项的和。 问你sum=求和(suma*b[i])i=1,2,3,……n的最小值,这里的顺序可以不是原数组的顺序。(我感觉我没说明白,我都听不懂了) 学长的题意:给你n个任务,每个任务有两个权值,t[i],b[i],前面的是完成任务所需时间,后面的那个是个参数,每个任务完成的代价是完成当前任务总时间(之前的+现在的)sumt
命令行查询oracle表空间的利用率
select a.a1 表空间名称,c.c2 类型,c.c3 区管理,b.b2/1024/1024 表空间大小M,(b.b2-a.a2)/1024/1024 已使用M,substr((b.b2-a.a2)/b.b2*100,1,5) 利用率from (SELECT TABLESPACE_NAME A1,SUM(NVL(bytes,0)) a2 from dba_free_space group
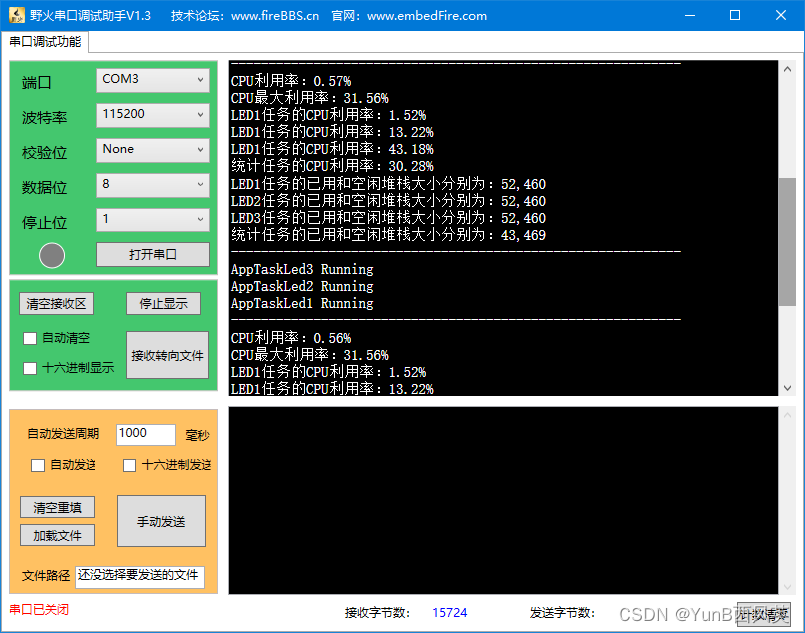
(学习日记)2024.04.18:UCOSIII第四十六节:CPU利用率及栈检测统计
写在前面: 由于时间的不足与学习的碎片化,写博客变得有些奢侈。 但是对于记录学习(忘了以后能快速复习)的渴望一天天变得强烈。 既然如此 不如以天为单位,以时间为顺序,仅仅将博客当做一个知识学习的目录,记录笔者认为最通俗、最有帮助的资料,并尽量总结几句话指明本质,以便于日后搜索起来更加容易。 标题的结构如下:“类型”:“知识点”——“简短的解释” 部分内容由于保密协议无法上传。 点击此处进入学

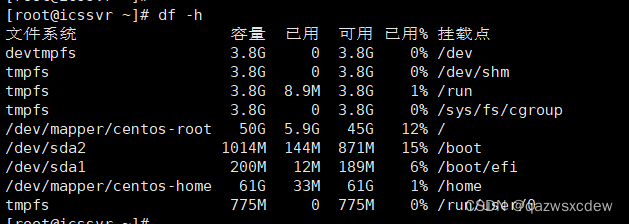
Linux CPU利用率
Linux CPU利用率 在线上服务器观察线上服务运行状态的时候,绝大多数人都是喜欢先用 top 命令看看当前系统的整体 cpu 利用率。例如,随手拿来的一台机器,top 命令显示的利用率信息如下 这个输出结果说简单也简单,说复杂也不是那么容易就能全部搞明白的。例如: 问题 1:top 输出的利用率信息是如何计算出来的,它精确吗? 问题 2:ni 这一列是 nice,它输出的是 cpu 在
使用subprocess包来在python代码实时查看GPU利用率
最近又被GPU利用率问题导致训练不高效的问题搞到了(恼),所以在py使用代码看看是哪出了问题。 import subprocessdef get_gpu_utilization():# 运行nvidia-smi命令smi_output = subprocess.check_output(['nvidia-smi', '--query-gpu=utilization.gpu', '--format
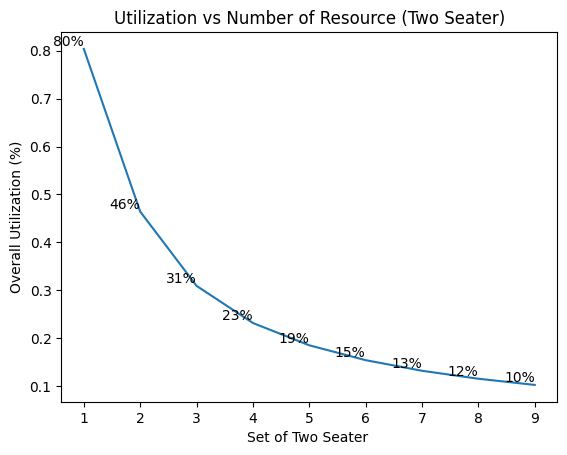
使用 Python SimPy 进行离散事件模拟【02】 — 识别性能指标(队列和利用率)并可视化结果
一、说明 对于那些第一次阅读本系列文章的人,我想让你知道,最好在这里掌握我们在上一章所做的工作的背景。 继续我们所做的模拟餐馆系统的工作,在本章中,我们想与您讨论如何识别性能指标,以便我们可以通过开发的模型有效地评估我们的系统。在此过程中,我们将深入了解队列和利用率的概念,因为这些术语与离散事
请求、缓存、图片利用率和人力成本
最近我们在优化Qzone的静态资源架构的时候,遇到了一个问题,这个问题需要我们对请求、缓存、图片利用率、人力成本这几点来权衡。前端性能的优化就是关于权衡,很多事情都没有一个完美解决方案。要针对具体需求进行优化。 请求 请求很简单,所有了解前端性能优化的人都能脱口而出:HTTP请求越少越好。 HTTP请求少于 一定数量的时候,减少请求就没有意义了。 页面上有些不重要的模块可以用ajax来延迟
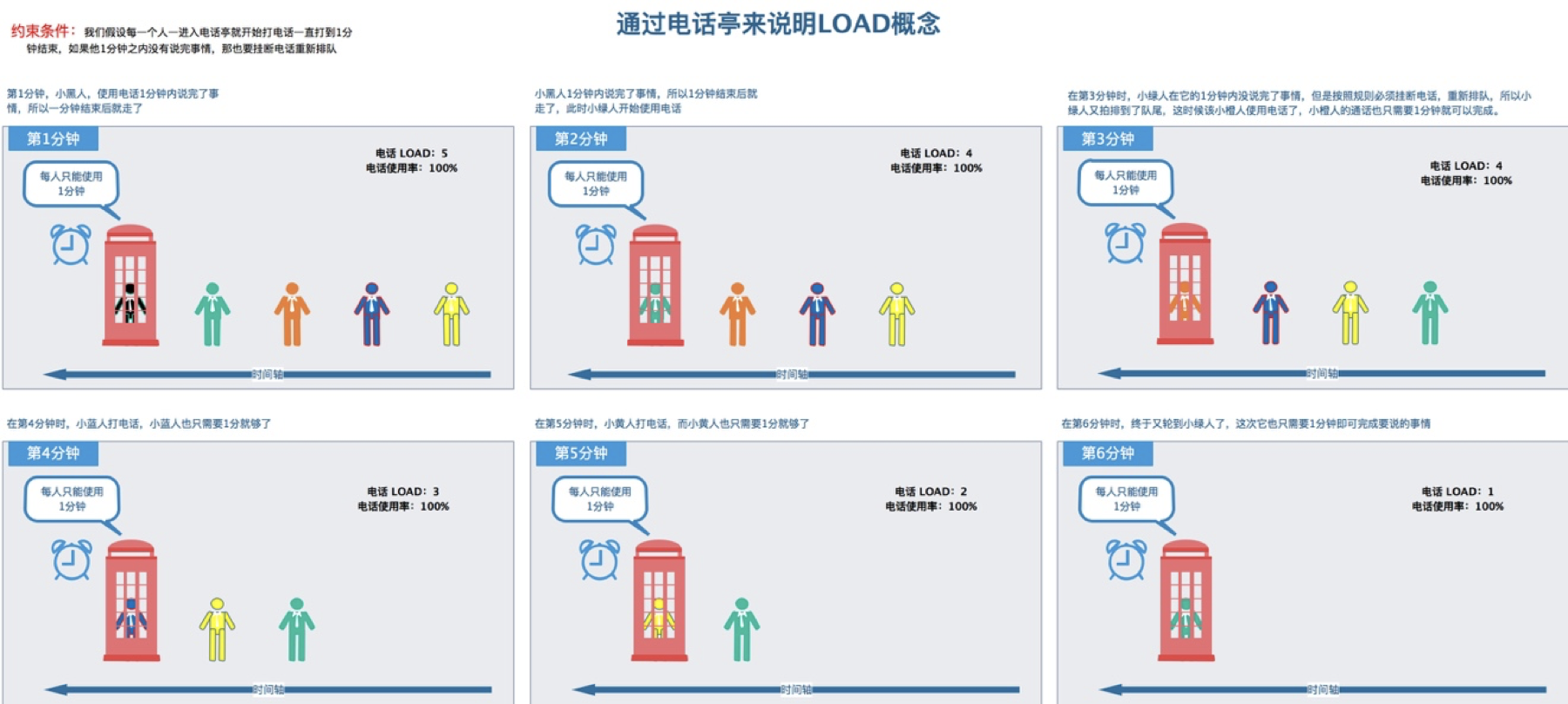
cpu太空闲 提高mysql利用率_CPU的load和使用率傻傻分不清
1. 什么是Cpu的Load 使用uptime、top或者查看/proc/loadavg都可以看到CPU的load统计,这里有三个值,分别代表1分钟、5分钟和15分钟的CPU Load情况。大部分人认为这三个数值越小说明比较好,如果越高说明系统可能存在问题或负载过高了。那这个值处于什么状态是好什么又是不好?什么时候需要关注并检查高的原因? LOAD AVERAGE:一段时间内处于可运行状
Java虚拟机(JVM)的调优是为了提高Java应用程序的性能、稳定性和资源利用率
Java虚拟机(JVM)的调优是为了提高Java应用程序的性能、稳定性和资源利用率。以下是一些建议的JVM调优技巧: 调整堆大小: 设置堆的大小以适应应用程序的需求。通过调整-Xms(初始堆大小)和-Xmx(最大堆大小)参数来控制。合理的堆大小可以减少垃圾收集的频率。 java -Xms256m -Xmx1024m -jar YourApp.jar 选择垃圾收集器: 根据应用程序的特

高效治理垃圾渗滤液是提高水资源利用率的重要途径
随着城市生活垃圾的不断增多,城市生活垃圾的处置已成为城市可持续发展不可回避的挑战。实际上,垃圾渗滤液处置不当、垃圾填埋场运行超负荷、生活垃圾焚烧设施建设滞后等问题已多次进入中央生态环保督察的视野,并屡有报道。 垃圾渗滤液俗称“垃圾汤”,是在垃圾填埋场内形成的一种含有害物质的高浓度废水。如果处理不当,将严重污染地表水和地下水,影响水生生物的生存和水资源的利用,甚至影响人类健康。根据相关规定
垃圾桶的空闲爆满情况/利用率分析
满载:select m.DEVICECODE,m.SYS_KEY,m.GARDENNAME,m.GARBAGETYPE,m.THROWTIME,m.WEIGHT from (select DEVICECODE,SYS_KEY,GARDENNAME,GARBAGETYPE,THROWTIME,to_number(WEIGHT) as WEIGHT from TFJL_COPY) m wher