分布式服务专题

搭建大型分布式服务(四十四)SpringBoot 无代码侵入实现多Kafka数据源:单分区提升至十万级消费速度!
系列文章目录 文章目录 系列文章目录前言一、本文要点二、开发环境三、原项目四、修改项目五、测试一下五、小结 前言 在过去的一段时间里,我们利用了AI大模型写了一个多线程并发框架,那么,我们怎样集成到Kafka组件里,让消费速度提升N倍呢? 《AI大模型编写多线程并发框架(六十一):从零开始搭建框架》《AI大模型编写多线程并发框架(六十二):限流和并发度优化》《

分布式服务限流实战,已经为你排好坑了 | 总结的很全面
点击上方“朱小厮的博客”,选择“设为星标” 当当满300-50优惠码:TMWCP4 一、限流的作用 由于API接口无法控制调用方的行为,因此当遇到瞬时请求量激增时,会导致接口占用过多服务器资源,使得其他请求响应速度降低或是超时,更有甚者可能导致服务器宕机。 限流(Rate limiting)指对应用服务的请求进行限制,例如某一接口的请求限制为100个每秒,

工商银行分布式服务 C10K 场景解决方案
点击上方“朱小厮的博客”,选择“设为星标” 后台回复"书",获取 后台回复“k8s”,可领取k8s资料 Dubbo 是一款轻量级的开源 Java 服务框架,是众多企业在建设分布式服务架构时的首选。中国工商银行自 2014 年开始探索分布式架构转型工作,基于开源 Dubbo 自主研发了分布式服务平台。 Dubbo 框架在提供方消费方数量较小的服务规模下,运行稳定、性能良好。随着银行业务线上化、多样
.NET中分布式服务
单体架构 特点: 所有的功能集成在一个项目工程中。所有的功能打在一个安装包。 优点: 项目架构简单。开发效率高。容易打包。 缺点: 全部功能集成在一个工程中,如果要更新, 所有的都要重新发布版本迭代速度逐渐变慢无法按需伸缩 分布式架构: 特点: 按业务垂直拆分成一个一个的单体系统系统与系统之间的存在数据冗余,耦合性较大系统之间的接口多为实现数据同步 优点: 通

分布式服务框架 Zookeeper -- 日志配置
原文: 1.http://www.voidcn.com/blog/xyang81/article/p-6258996.html 2.http://www.cnblogs.com/zhwbqd/p/3957018.html Zookeeper在启动的时候,默认会在当前运行zkServer.sh命令的目录生成一个zookeeper.out日志文件,从日志中可以看到客户端的连接请求、发送的

【dubbo】分布式服务划分
一、持续集成 1.持续集成? 持续集成是一种软件开发实践,即团队开发成员经常集成他们的工作,通过每个成员每天至少集成一次,也就意味着每天可能会发生多次集成。每次集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,从而尽早地发现集成错误。 我简单的理解,就是频繁的(每天多次)将代码集成到主干。好处主要是(1)能够快速的发现错误,每完成一点更新,就集成到主干,

深入理解单一应用架构、垂直应用架构和分布式服务架构
什么是单一应用架构? 单一应用架构(Monolithic Architecture)是一种传统的软件架构模式,其中所有的功能模块被构建成一个独立的可部署单元。简单来说,整个应用程序作为一个整体被打包和部署。 单一应用架构的特点 集中管理:所有的功能模块都在一个代码库中进行管理。统一部署:整个应用程序作为一个单独的单元进行打包和部署。紧耦合:模块之间的依赖关系较强,一个模块的修改可能会影响到其
搭建大型分布式服务(四十)SpringBoot 整合多个kafka数据源-支持生产者
系列文章目录 文章目录 系列文章目录前言一、本文要点二、开发环境三、原项目四、修改项目五、测试一下五、小结 前言 本插件稳定运行上百个kafka项目,每天处理上亿级的数据的精简小插件,快速上手。 <dependency><groupId>io.github.vipjoey</groupId><artifactId>multi-kafka-starter</ar
搭建大型分布式服务(三十八)SpringBoot 整合多个kafka数据源-支持protobuf
系列文章目录 文章目录 系列文章目录前言一、本文要点二、开发环境三、原项目四、修改项目五、测试一下五、小结 前言 本插件稳定运行上百个kafka项目,每天处理上亿级的数据的精简小插件,快速上手。 <dependency><groupId>io.github.vipjoey</groupId><artifactId>multi-kafka-consumer-st
搭建大型分布式服务(三十九)SpringBoot 整合多个kafka数据源-支持Aware模式
系列文章目录 文章目录 系列文章目录前言一、本文要点二、开发环境三、原项目四、修改项目五、测试一下五、小结 前言 本插件稳定运行上百个kafka项目,每天处理上亿级的数据的精简小插件,快速上手。 <dependency><groupId>io.github.vipjoey</groupId><artifactId>multi-kafka-consumer-st

分布式服务架构(原理、设计与实现)十
背景 受到同事的激励,准备开始认真静下心来看看书;于是挑选了一本书籍,名字叫做《分布式服务架构(原理、设计与实现)》。本书从问题背景入手,深入浅出低介绍了服务化架构,并结合具体的最佳时间,为我展示了服务化架构设计的宏伟蓝图 第十章
分布式服务架构(原理、设计与实现)九
背景 受到同事的激励,准备开始认真静下心来看看书;于是挑选了一本书籍,名字叫做《分布式服务架构(原理、设计与实现)》。本书从问题背景入手,深入浅出低介绍了服务化架构,并结合具体的最佳时间,为我展示了服务化架构设计的宏伟蓝图 第九章
分布式服务架构(原理、设计与实现)八
背景 受到同事的激励,准备开始认真静下心来看看书;于是挑选了一本书籍,名字叫做《分布式服务架构(原理、设计与实现)》。本书从问题背景入手,深入浅出低介绍了服务化架构,并结合具体的最佳时间,为我展示了服务化架构设计的宏伟蓝图 第八章
分布式服务架构(原理、设计与实现)七
背景 受到同事的激励,准备开始认真静下心来看看书;于是挑选了一本书籍,名字叫做《分布式服务架构(原理、设计与实现)》。本书从问题背景入手,深入浅出低介绍了服务化架构,并结合具体的最佳时间,为我展示了服务化架构设计的宏伟蓝图 第七章
分布式服务架构(原理、设计与实现)六
背景 受到同事的激励,准备开始认真静下心来看看书;于是挑选了一本书籍,名字叫做《分布式服务架构(原理、设计与实现)》。本书从问题背景入手,深入浅出低介绍了服务化架构,并结合具体的最佳时间,为我展示了服务化架构设计的宏伟蓝图 第六章
分布式服务架构(原理、设计与实现)五
背景 受到同事的激励,准备开始认真静下心来看看书;于是挑选了一本书籍,名字叫做《分布式服务架构(原理、设计与实现)》。本书从问题背景入手,深入浅出低介绍了服务化架构,并结合具体的最佳时间,为我展示了服务化架构设计的宏伟蓝图 第五章
分布式服务架构(原理、设计与实现)三
背景 受到同事的激励,准备开始认真静下心来看看书;于是挑选了一本书籍,名字叫做《分布式服务架构(原理、设计与实现)》。本书从问题背景入手,深入浅出低介绍了服务化架构,并结合具体的最佳时间,为我展示了服务化架构设计的宏伟蓝图 第三章
搭建大型分布式服务(三十七)SpringBoot 整合多个kafka数据源-取消限定符
系列文章目录 文章目录 系列文章目录前言一、本文要点二、开发环境三、原项目四、修改项目五、测试一下五、小结 前言 本插件稳定运行上百个kafka项目,每天处理上亿级的数据的精简小插件,快速上手。 <dependency><groupId>io.github.vipjoey</groupId><artifactId>multi-kafka-consumer-st

Dubbo:来自于阿里巴巴的分布式服务框架
Dubbo是阿里巴巴SOA服务化治理方案的核心框架,每天为2,000+个服务提供3,000,000,000+次访问量支持,并被广泛应用于阿里巴巴集团的各成员站点 Dubbo是一个阿里巴巴开源出来的一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。其核心部分包含: 远程通讯: 提供对多种基于长连接的NIO框架抽象封装,包括多种线程模型,序列化,以及
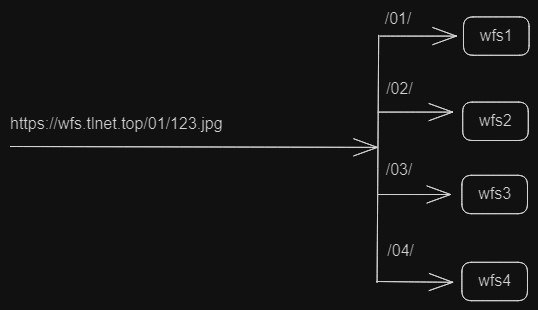
如何部署 wfs 分布式服务
说明: wfs是海量小文件存储系统。wfs1.x不直接支持分布式存储,但为了应对大规模部署和高可用需求,推荐采用如Nginx这样的负载均衡服务,通过合理的资源配置和定位策略,可以在逻辑上模拟出类似分布式的效果。也就是说,虽然每个wfs实例都是单机存储,但可以通过外部服务实现多个wfs实例之间的请求分发,例如通过对文件路径前缀(如 /01/)进行解析,可将请求分发至不同的wfs实例,从而达到业务层面

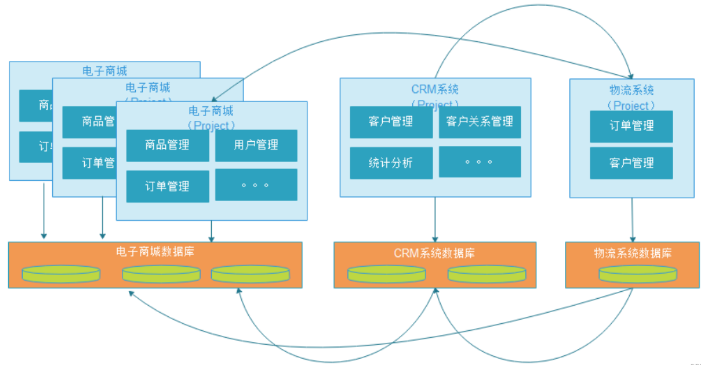
大型网站系统架构演化实例_9.分布式服务
1. 第十阶段:分布式服务 随着业务拆分越来越小,存储系统越来越庞大,应用系统的整体复杂度呈指数级增加,部署维护越来越困难。由于所有应用要和所有数据库系统连接,在数万台服务器规模的网站中,这些连接的数目是服务器规模的平方,导致数据库连接资源不足,拒绝服务。 既然每一个应用系统都需要执行许多相同的业务操作,比如用户管理、商品管理等,那么可以将这些共用的业务提取出来,
ZooKeeper分布式服务与Kafka消息队列+ELKF整合方案
前言 ZooKeeper 是一个分布式的、开放源码的分布式应用程序协调服务,提供配置维护、命名服务、分布式同步、组服务等功能; Kafka 是一个开源的分布式流处理平台,它被设计用来处理实时数据流,包括发布和订阅消息系统、日志收集以及作为事件流数据平台; 在 Kafka 集群中,ZooKeeper 用于协调和管理 Kafka broker 的状态、集群的配置信息以及其他关键元数据。结合使用
基于consul构建golang系统分布式服务发现机制
原文链接:石匠1号的Blog 在分布式架构中,服务治理是一个重要的问题。在没有服务治理的分布式集群中,各个服务之间通过手工或者配置的方式进行服务关系管理,遇到服务关系变化或者增加服务的时候,人肉配置极其麻烦且容易出错。 之前在一个C++项目中,采用ZooKeeper进行服务治理,可以很好的维护服务之间的关系,但是使用起来较为麻烦。现在越来越多新的项目采用consul进行服务治理,各方面的评价都
SpringBoot 系列教程(十五):SpringBoot整合Dubbo搭建分布式服务
一、前言 Dubbo是阿里巴巴开源的基于 Java 的高性能 RPC(一种远程调用) 分布式服务框架(SOA),致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。本节将基于SpringBoot2.x整合Dubbo分布式框架,按照以下七步进行: 第一步:了解Dubbo 什么是分布式? 什么是 Duboo? Dubbo 架构
中间件ZooKeeper(分布式服务框架)
中间件ZooKeeper(分布式服务框架) 1、简介 Zookeeper是为分布式应用提供一致性服务的软件,是一个开源的分布式协调服务,是开源的hadoop项目的一个子项目,可以提供配置信息管理、命名、分布式同步、集群管理、数据库切换等服务。它不适合用来存储大量信息,可以用来存储一些配置、发布与订阅等少量信息。Hadoop、Storm、消息中间件、RPC服务框架

涨薪必备,先看完这本Java书籍「分布式服务框架原理与实践」
1.传统垂直应用架构:LAMP、MVC及早期的EJB随着业务不断发展和规模的扩大,存在的几个挑战 1)复杂应用的开发维护成本变高,部署效率逐渐降低 2)团队协作效率差,部分公共功能重复开发,代码重复率居高不下 3)系统可靠性变差 4)维护和定制困难 5)新功能上线周期变长 解决上面挑战的办法是核心业务独立,抽取公共API,实现服务共享,接口调用演变成跨进程远程调用,RPC框架应运而生。