估计量专题
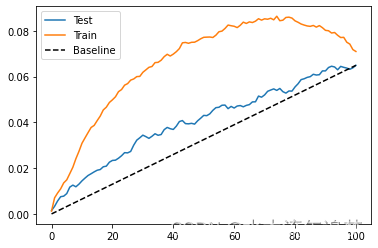
【因果推断python】45_估计量1
目录 问题设置 目标转换 到目前为止,我们已经了解了如何在干预不是随机分配的情况下对我们的数据进行纠偏,这会导致混淆偏差。这有助于我们解决因果推理中的识别问题。换句话说,一旦单位是可交换的,或者 ,就可以学习干预效果。但我们还远远没有完成。 识别意味着我们可以找到平均的干预效果。换句话说,我们知道一种干预的平均效果。当然,这很有用,因为它可以帮助我们决定是否应该真正实施干预。但

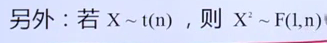
概率论考点之估计量(高等数学求最值)
如题:2019年10月 分析:新东西…………。大体看了下,应该是属于统计量及其分布的内容。 答案:根据《概率论复习之关于点估计》问题3中无偏性,样本k阶原点矩是总体k阶原点矩的无偏估计,原点矩的表达式为C 1、什么是统计量呢???? 用样本来表达的一个量,并且没有未知参数。如下定义:至于什么是样本?,详见扩展1: 2、什么又是无偏差????首先搞明白什么是偏差??详见扩展2
概率统计20——估计量的评选标准
对总体参数进行估计的方式多种多样,为了评判估计量的优劣,我们需要借助一些评选标准。 这些乱七八糟的符号 我觉得参数估计总是人为地设计各种门坎,里面参杂着各种符号,一会儿是X,一会儿是x;一会儿是θ,一会儿是θ(X);还有诸如“总体参数”、“待估计参数”这类名词,究竟是几个意思? 有必要先理清这些符号。 我们用全国18~50岁的男性身高为例,所有18~50岁的男性是总体。在


参数估计 评价估计量的标准
目录 https://blog.csdn.net/weixin_45792450/article/details/109314584 无偏性 我们希望估计量 θ ^ \hat \theta θ^的取值不要偏高也不要偏低,即 θ ^ \hat \theta θ^的平均取值与 θ \theta θ的真值一致,于是导出了无偏性标准: 定义 设 θ ^ = θ ^ ( X 1 , X 2 ,

【知识串联】概率论中的值和量(随机变量/数字特征/参数估计)【考研向】【按概率论学习章节总结】(最大似然估计量和最大似然估计值的区别)
就我的概率论学习经验来看,这两个概念极易混淆,并且极为重点,然而,在概率论的前几章学习中,如果只是计算,对这方面的辨析不清并没有问题。然而,到了后面的参数估计部分,却可能出现问题,而这些问题是比较隐晦而且难以发现的,并且鲜有老师强调。因此,就这方面希望能够帮助同样对概率论的这部分内容有疑惑的同学。 随机变量 首先,在学习概率最开始的时候,我们接触了随机变量X,它是一种量,就是说它是变化的

【知识串联】概率论中的值和量(随机变量/数字特征/参数估计)【考研向】【按概率论学习章节总结】(最大似然估计量和最大似然估计值的区别)
就我的概率论学习经验来看,这两个概念极易混淆,并且极为重点,然而,在概率论的前几章学习中,如果只是计算,对这方面的辨析不清并没有问题。然而,到了后面的参数估计部分,却可能出现问题,而这些问题是比较隐晦而且难以发现的,并且鲜有老师强调。因此,就这方面希望能够帮助同样对概率论的这部分内容有疑惑的同学。 随机变量 首先,在学习概率最开始的时候,我们接触了随机变量X,它是一种量,就是说它是变化的