xgb专题

分布式xgb原理(一)--
A Fast Algorithm for Approximate Quantiles in High Speed Data Streams Space-Efficient Online Computation of Quantile Summaries

XGB-24:使用Scikit-Learn估计器接口
概览 除了原生接口之外,XGBoost还提供了一个符合sklearn估计器指南的sklearn估计器接口。它支持回归、分类和学习排名。sklearn估计器接口的生存训练仍在进行中。 你可以在使用sklearn接口的示例集合中找到一些快速入门示例。使用sklearn接口的主要优势在于,它可以与sklearn提供的大多数实用程序一起工作,例如sklearn.model_selection.cross

XGB-18:使用Concrete ML进行隐私保护推理
隐私保护推理是指以一种保护输入数据隐私的方式执行机器学习推理。这在处理敏感或个人信息时尤为重要,例如医疗记录或财务信息。实现隐私保护推理的一种方法是使用称为安全多方计算(SMC)的技术,该技术允许多个方在他们的输入上联合计算一个函数,而无需将这些输入透露给彼此。 Concrete ML是由Zama开发的一个专业库,它允许通过完全同态加密(FHE)在加密数据上执行机器学习模型,从而保护数据隐私。 要
XGB-17:模型截距
在 XGBoost 中,模型截距(也称为基本分数)是一个值,表示在考虑任何特征之前模型的起始预测。它本质上是处理回归任务时训练数据的平均目标值,或者是分类任务的赔率对数。 在 XGBoost 中,每个叶子节点都会输出一个分数,而模型的最终预测是将所有叶子节点的分数相加得到的。这些分数在树的训练过程中被学习得到,但当没有任何输入特征时,模型需要一个基准值,这就是截距的作用。 从2.0.0版本开始
XGB-16:自定义目标和评估指标
概述 XGBoost被设计为一个可扩展的库。通过提供自定义的训练目标函数和相应的性能监控指标,可以扩展它。本文介绍了如何为XGBoost实现自定义的逐元评估指标和目标。 注意: 排序不能自定义 在接下来的两个部分中,将逐步介绍如何实现平方对数误差(Squared Log Error,SLE)目标函数: 1 2 [ log ( p r e d + 1 ) − log ( l
XGB-14:DMatrix的文本输入格式
简要描述XGBoost的文本输入格式。然而,对于具有支持的语言环境(如Python或R)的用户,建议使用该生态系统中的数据解析器。例如,可以使用sklearn.datasets.load_svmlight_file()。 基本输入格式 XGBoost目前支持两种文本格式的数据导入:LIBSVM和CSV。本文档的其余部分将描述LIBSVM格式(有关CSV格式的描述,请参见此Wikipedia文章
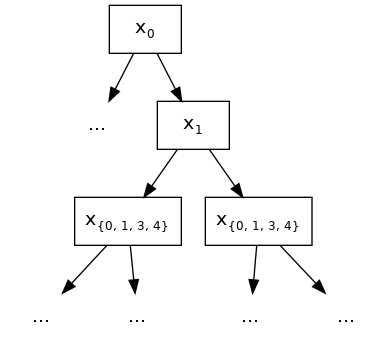
XGB-7: 特征交互约束
决策树是发现自变量(特征)之间交互关系的强大工具。在遍历路径中一起出现的变量是相互交互的,因为子节点的条件取决于父节点的条件。例如,在下图中,红色突出显示的路径包含三个变量: x 1 x_1 x1、 x 7 x_7 x7 和 x 10 x_{10} x10,因此突出显示的预测值(在突出显示的叶节点处)是 x 1 x_1 x1、 x 7 x_7 x7 和 x 10 x_{10} x1
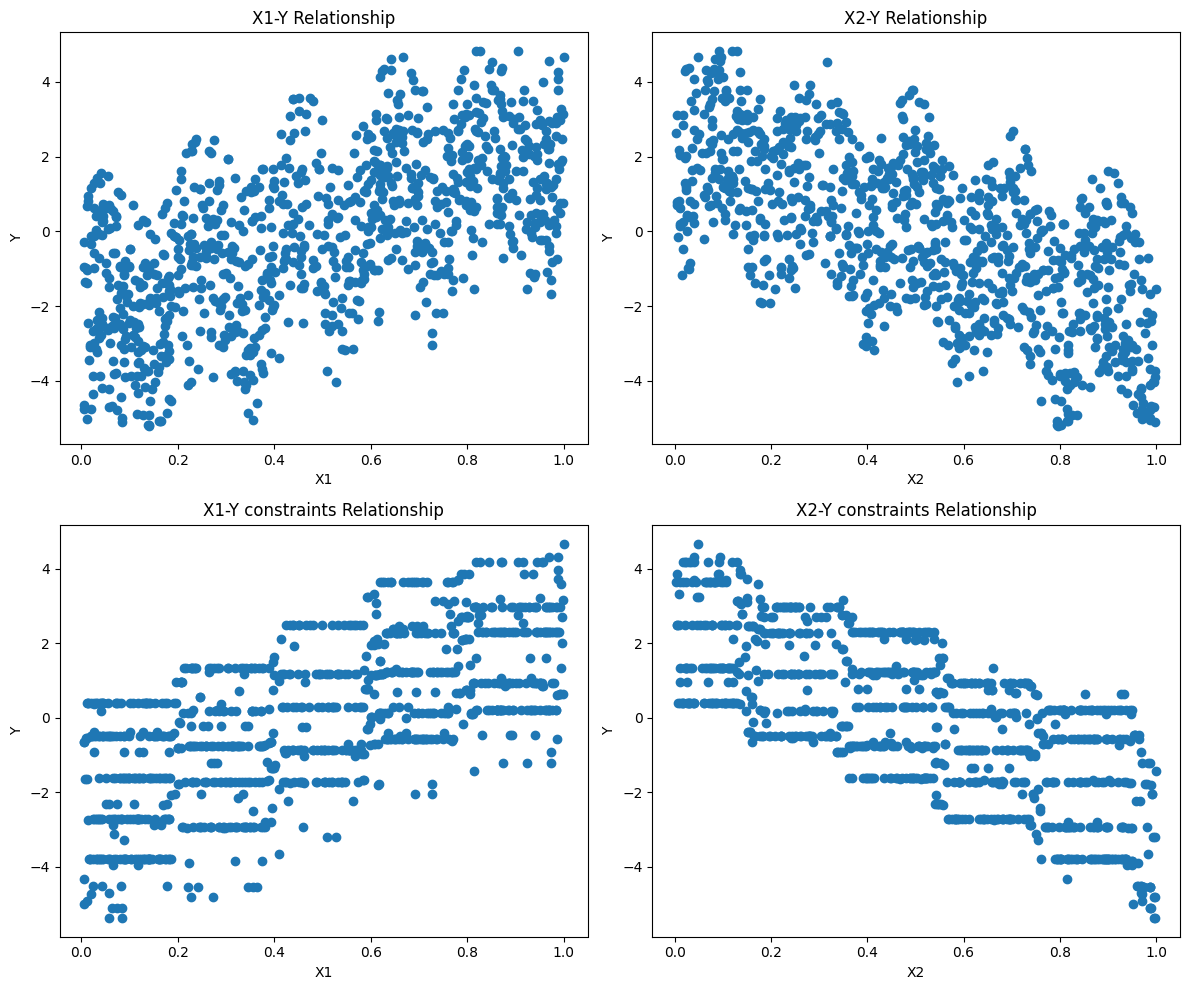
XGB-6: 单调性约束Monotonic Constraints
在建模问题或项目中,通常情况下,可接受模型的函数形式会以某种方式受到约束。这可能是由于业务考虑,或者由于正在研究的科学问题的类型。在某些情况下,如果对真实关系有非常强烈的先验信念,可以使用约束来提高模型的预测性能。 在这种情况下的一种常见约束类型是,某些特征与预测响应呈单调关系: f ( x 1 , x 2 , … , x , … , x n − 1 , x n ) ≤ f ( x 1 ,
XGB-5: DART Booster
XGBoost 主要结合了大量的回归树和一个小的学习率。在这种情况下,早期添加的树是重要的,而晚期添加的树是不重要的。 Vinayak 和 Gilad-Bachrach 提出了一种将深度神经网络社区的 dropout 技术应用于梯度提升树的新方法,并在某些情况下报告了更好的结果。 以下是新的树增强器 dart 的说明。 原始论文 Rashmi Korlakai Vinayak, Ran G
XGB-3: 模型IO
在XGBoost 1.0.0中,引入了对使用JSON保存/加载XGBoost模型和相关超参数的支持,旨在用一个可以轻松重用的开放格式取代旧的二进制内部格式。后来在XGBoost 1.6.0中,还添加了对通用二进制JSON的额外支持,作为更高效的模型IO的优化。它们具有相同的文档结构,但具有不同的表示形式,但都统称为JSON格式。本教程旨在分享一些关于XGBoost中使用的JSON序列化方法的基本见
XGB-1:XGBoost安装及快速上手
XGBoost是“Extreme Gradient Boosting”的缩写,是一种高效的机器学习算法,用于分类、回归和排序问题。它由陈天奇(Tianqi Chen)在2014年首次提出,并迅速在数据科学竞赛和工业界获得广泛应用。XGBoost基于梯度提升框架,但通过引入一系列优化来提升性能和效率。 XGBoost的主要特点: 性能高效:XGBoost通过并行处理和核外计算来优化计算速度,同时

【机器学习】模型参数优化工具:Optuna使用分步指南(附XGB/LGBM调优代码)
常用的调参方式和工具包 常用的调参方式包括网格搜索(Grid Search)、**随机搜索(Random Search)和贝叶斯优化(Bayesian Optimization)**等。 工具包方面,Scikit-learn提供了GridSearchCV和RandomizedSearchCV等用于网格搜索和随机搜索的工具。另外,有一些专门用于超参数优化的工具包,如Optuna、Hypero
基于机器学习SVM xgboost xgb 线性回归 逻辑回归 的二手车价格预测 完整数据+代码
项目运行视频:https://www.bilibili.com/video/BV1ZP411f7uq/?spm_id_from=333.999.0.0 附完整的代码+数据
【机器学习】XGB/LGBM
XGBoost的decision tree用的是pre-sorted based的算法,也就是在tree building之前对各维特征先排序,代表性的算法是SLIQ和SPRINT。SLIQ和SPRINT算法的特点决定了树生长的方式是level-wise(breadth-first)的。 而LightGBM的decision tree是histogram based的算法,也就是先将特征离散化,
【机器学习】XGB/LGBM
XGBoost的decision tree用的是pre-sorted based的算法,也就是在tree building之前对各维特征先排序,代表性的算法是SLIQ和SPRINT。SLIQ和SPRINT算法的特点决定了树生长的方式是level-wise(breadth-first)的。 而LightGBM的decision tree是histogram based的算法,也就是先将特征离散化,
MNIST2_LGB_XGB训练预测
针对MNIST数据集进行XGB\LGB模型训练和预测 部分脚本如下: 完整脚本见笔者github lgb_param = {'boosting': 'gbdt','num_iterations': 145,'num_threads' : 8, 'verbosity': 0,'learning_rate': 0.2,'max_depth' : 10,'num_leaves' : 8,'subsam