wasserstein专题
YOLOv9/YOLOv8算法改进【NO.117】 使用Wasserstein Distance Loss改进小目标的检测效果
前 言 YOLO算法改进系列出到这,很多朋友问改进如何选择是最佳的,下面我就根据个人多年的写作发文章以及指导发文章的经验来看,按照优先顺序进行排序讲解YOLO算法改进方法的顺序选择。具体有需求的同学可以私信我沟通: 首推,是将两种最新推出算法的模块进行融合形成最为一种新型自己提出的模块然后引入到YOLO算法中,可以起个新的名字,这种改进是最好发高水平期刊论文。后续改进将主要教
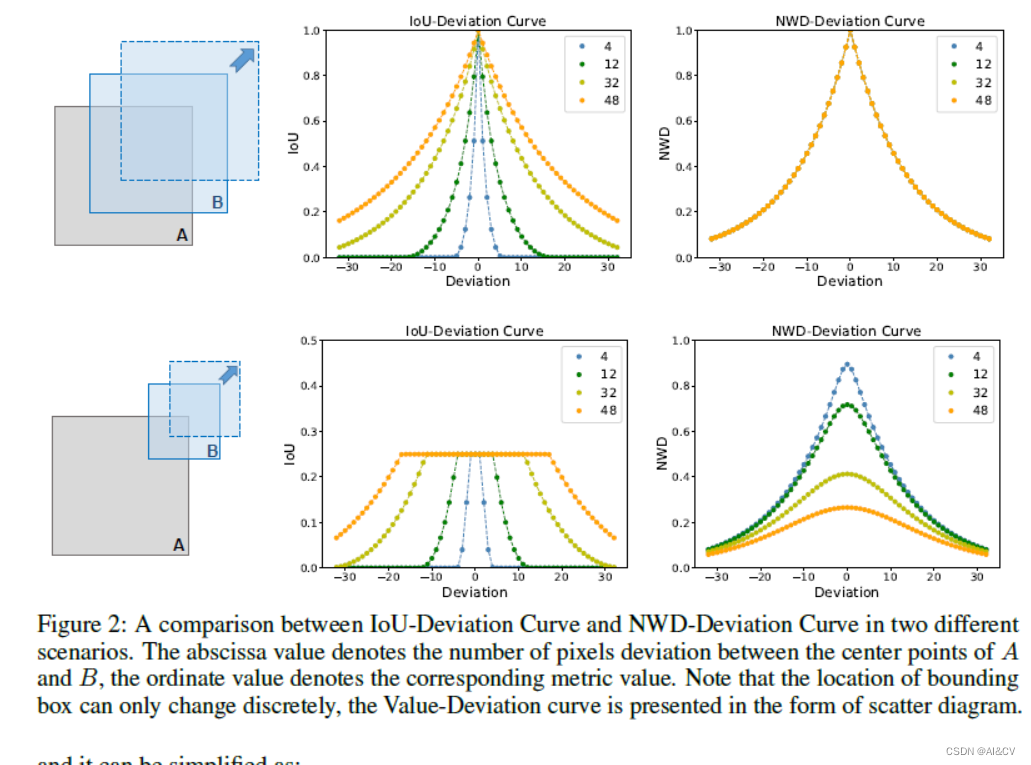
YOLOv9改进策略:IoU优化 | Wasserstein Distance Loss,助力小目标涨点
💡💡💡本文独家改进:基于Wasserstein距离的小目标检测评估方法 Wasserstein Distance Loss | 亲测在多个数据集能够实现涨点,对小目标、遮挡物性能提升明显 💡💡💡MS COCO和PASCAL VOC数据集实现涨点 YOLOv9魔术师专栏 ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁
Wasserstein GAN 最通俗易懂的解释
这篇文章是我在知乎阅读到的一篇对WGAN的起源、原理、改进的解释,个人认为是目前我看过的最好的解释。 链接:https://zhuanlan.zhihu.com/p/25071913 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 在GAN的相关研究如火如荼甚至可以说是泛滥的今天,一篇新鲜出炉的arXiv论文《Wassertein GAN》却在Reddit

埃森哲杯第十六届上海大学程序设计联赛春季赛暨上海高校金马五校赛 A - Wasserstein Distance
题目描述 最近对抗生成网络(GAN)很火,其中有一种变体WGAN,引入了一种新的距离来提高生成图片的质量。这个距离就是Wasserstein距离,又名铲土距离。 这个问题可以描述如下: 有两堆泥土,每一堆有n个位置,标号从1~n。第一堆泥土的第i个位置有a i克泥土,第二堆泥土的第i个位置有b i克泥土。小埃可以在第一堆泥土中任意移挪动泥土,具体地从第i个位置移动k克泥土到第j个
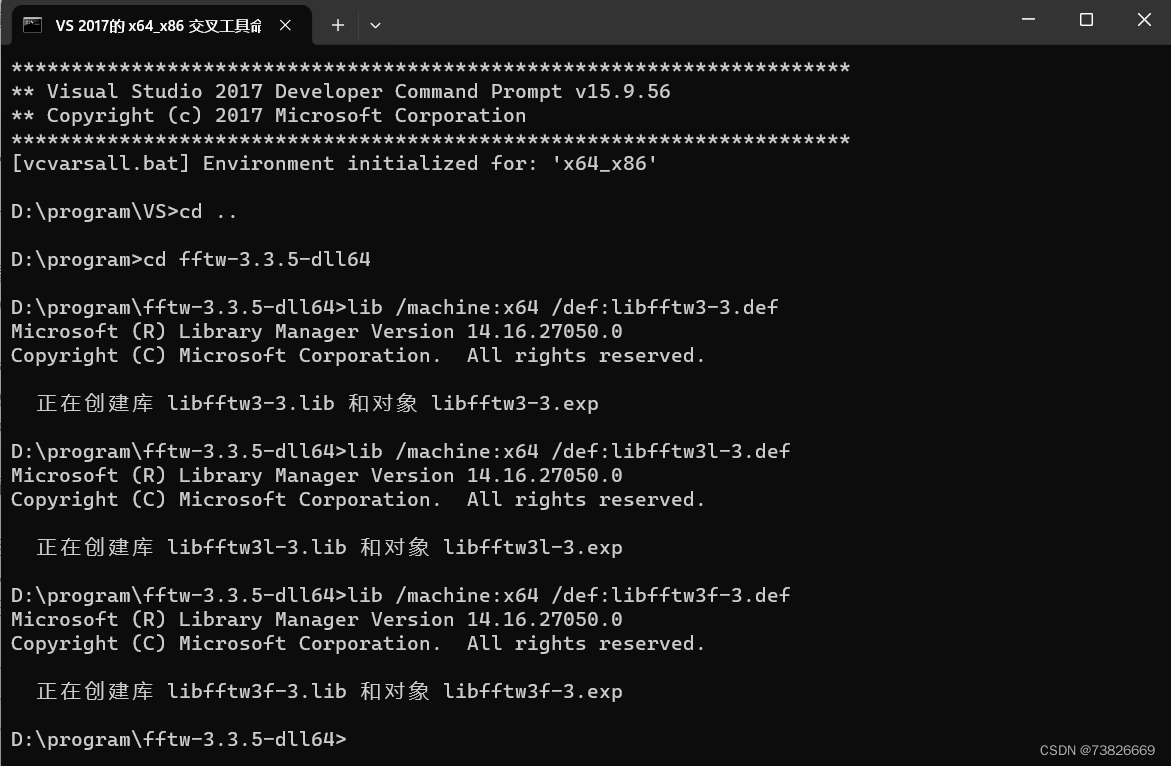
The Back-And-Forth Method (BFM) for Wasserstein Gradient Flows windows安装
本文记录了BFM算法代码在windows上的安装过程。 算法原网站:https://wasserstein-gradient-flows.netlify.app/ github:https://github.com/wonjunee/wgfBFMcodes 文章目录 FFTWwgfBFMcodesMATLABpython注 FFTW 官网/下载路径:https://www.f

GAN的Loss的比较研究(3)——Wasserstein Loss理解(1)
前两篇文章讨论了传统GAN的Loss,该Loss有些不足的地方,导致了GAN的训练十分困难,表现为:1、模式坍塌,即生成样本的多样性不足;2、不稳定,收敛不了。Martin Arjovsky在《Towards principled methods for training generative adversarial networks》、《Wasserstein GAN》文章中,对传统Loss造成

【RL】Wasserstein距离-GAN背后的直觉
一、说明 在本文中,我们将阅读有关Wasserstein GANs的信息。具体来说,我们将关注以下内容:i)什么是瓦瑟斯坦距离?,ii)为什么要使用它?iii) 我们如何使用它来训练 GAN? 二、Wasserstein距离概念 Wasserstein距离,又称为Earth Mover's Distance (EMD),是衡量两个

有关熵、相对熵(KL散度)、交叉熵、JS散度、Wasserstein距离的内容
写在前面 最近学了一些关于熵的内容,为增强自己对这些内容的理解,方便自己以后能够温习,随手记录了相关的介绍,可能有不对的地方,敬请谅解。 信息量 任何事件都会承载一定的信息,事件发生的概率越大,其含有的信息量越少,事件发生的概率越小,其含有的信息量越多。比如昨天下雨了,是一个既定的事实,所以其信息量为0,天气预报说明天会下雨,是一个概率事件,其信息量相对较大。 假设 X X X是一个离散
YOLOv7损失函数改进:Wasserstein Distance Loss,助力小目标涨点
💡💡💡本文属于独家改进:Wasserstein distance,无论小目标之间有没有重叠都可以度量分布相似性; NWD对不同尺度的目标不敏感,更适合测量小目标之间的相似性。 Wasserstein Distance Loss | 亲测在多个数据集实现涨点,尤其在小目标领域效果佳; 收录: YOLOv7高阶自研专栏介绍: http://t.csdnimg.cn/tYI0c
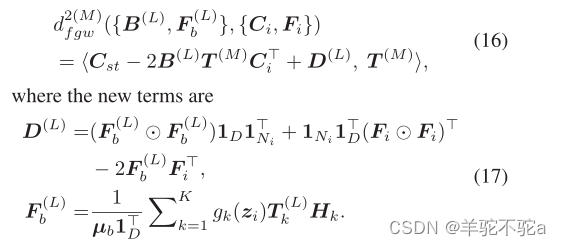
【最优传输论文十九】2020 AAAI - Gromov-wasserstein factorization models for graph clustering
1. motivation 作为机器学习的一种重要方法,因式分解模型明确地探索了高维观测的内在结构,已被广泛应用于数据聚类、降维、推荐系统等学习任务。特别是,因式分解模型将高维观测分解成特定标准下的一组原子,并相应地获得它们的潜在表示。对于每个观测值,其潜在表示对应于与原子相关的系数。 然而,大多数现有的分解模型,如主成分分析(PCA)、非负矩阵分解(NMF) 和字典学习,都是为具有相同维度的

【最优传输论文十四】2019 CVPR-Sliced Wasserstein Discrepancy for Unsupervised Domain Adaptation
1.motivation 无监督域适应大部分工作都集中在建立源域和目标域的特征分布之间的直接对齐。这种对齐涉及最小化模型学习到的特征分布的一些距离度量。更复杂的方法使用对抗性训练,通过在特征级、像素级或输出级跨域调整表示,从而提高分布之间对齐的质量。 在MCD中提出了一种基于网络内对抗学习的方法,该方法包含一个特征生成器和两个(特定任务)分类器,该方法使用特定任务的决策边界来对齐源样本和目标样