vq专题

语音信号处理(2):文本相关的声纹识别系统(MFCC、VQ)
本文基于Matlab设计实现了一个文本相关的声纹识别系统,可以判定说话人身份。简单理解即为一个声纹锁(类似指纹锁)。整个系统的源代码,可以从这里下载:【基于Matlab的声纹锁】 系统原理 a.声纹识别 这两年随着人工智能的发展,不少手机App都推出了声纹锁的功能。这里面所采用的主要就是声纹识别相关的技术。声纹识别又叫说话人识别,它和语音识别存在一点差别。

【语音识别】基于matlab VQ特定人孤立词语音识别【含Matlab源码 536期】
⛄一、获取代码方式 获取代码方式1: 完整代码已上传我的资源:【语音识别】基于matlab VQ特定人孤立词语音识别【含Matlab源码 536期】 点击上面蓝色字体,直接付费下载,即可。 获取代码方式2: 付费专栏Matlab语音处理(初级版) 备注: 点击上面蓝色字体付费专栏Matlab语音处理(初级版),扫描上面二维码,付费29.9元订阅海神之光博客付费专栏Matlab语音处理(初级版
VideoGPT:Video Generation using VQ-VAE and Transformers
1.introduction 对于视频展示,选择哪种模型比较好?基于似然->transformers自回归。在没有空间和时间溶于的降维潜在空间中进行自回归建模是否优于在所有空间和时间像素级别上的建模?选择前者:自然图像和视频包括了大量的空间和时间冗余,这些冗余可以通过学习高分辨率输入的去噪降维编码来消除,例如,空间和时间维度上的4倍降采样会导致64倍的分辨率降低,在潜在空间建模,不是像素空间,可
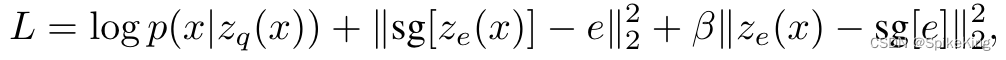
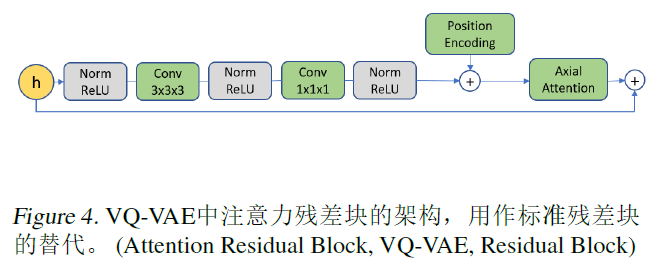
Paper - Neural Discrete Representation Learning (VQ-VAE) 论文简读
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/133992971 问题1:训练完成之后,如何判断 VQ-VAE 的效果? 输入一张训练样本之外的图像,经过编码器,与EmbeddingTable计算最近邻的向量,再把向量输入解码器中,获得重构之后的图像,判断图像

Python语音基础操作--11.1矢量量化(VQ)的说话人情感识别
《语音信号处理试验教程》(梁瑞宇等)的代码主要是Matlab实现的,现在Python比较热门,所以把这个项目大部分内容写成了Python实现,大部分是手动写的。使用CSDN博客查看帮助文件: Python语音基础操作–2.1语音录制,播放,读取 Python语音基础操作–2.2语音编辑 Python语音基础操作–2.3声强与响度 Python语音基础操作–2.4语音信号生成 Python语音基础
VQ-VAE torch 实现
文章目录 modelmain model import torchimport torch.nn as nnclass ResidualBlock(nn.Module):def __init__(self, dim):super().__init__()self.relu = nn.ReLU()self.conv1 = nn.Conv2d(dim, dim, 3, 1, 1)s
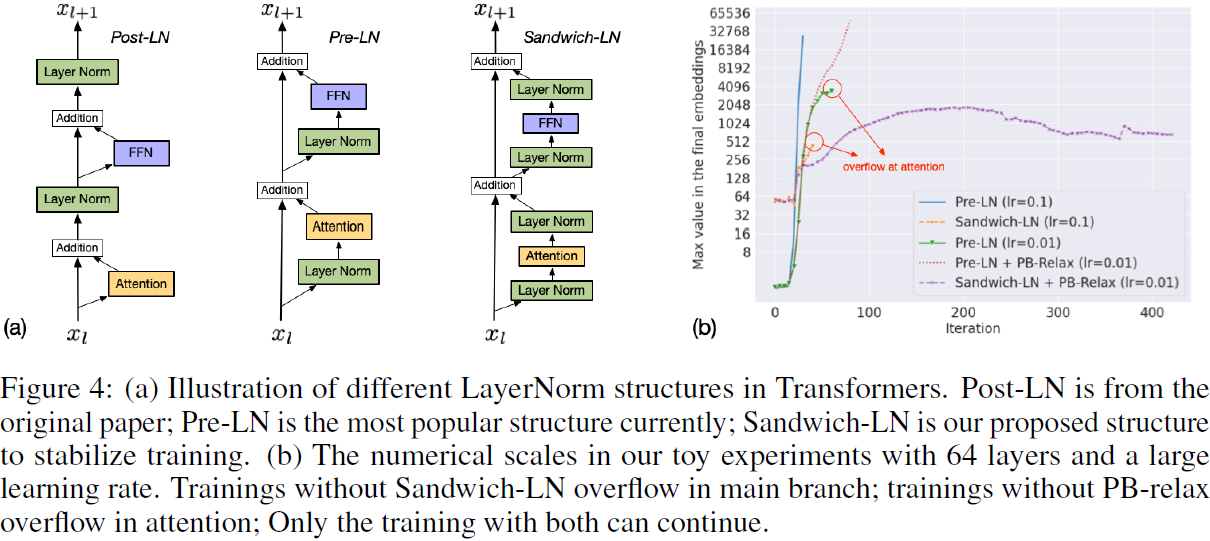
(2021|NIPS,VQ-VAE,精度瓶颈松弛,三明治层归一化,CapLoss)CogView:通过转换器掌握文本到图像的生成
CogView: Mastering Text-to-Image Generation via Transformers 公众号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料) 目录 0. 摘要 1. 简介 2. 方法 2.1 理论 2.2 标记化 2.3 自回归 Transformer 2.4 训练的稳定性 3. 微调 3.

matlab图像处理--LBG训练器应用 VQ压缩
I = double(imread('liftingbody.png'));Bk = 4;data = im2col(I, [Bk, Bk], 'distinct');N = size(data, 2);M = 100;rng(999)%随机选100个向量作为中心rnd = randi([1, N], [1,M]);centroid = data(:, rnd);%LBG训练次数为
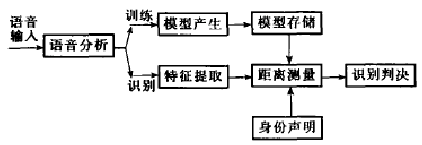
vq矢量量化lbg matlab,MATLAB环境下基于矢量量化的说话人识别系统
MATLAB环境下基于矢量量化的说话人识别系统 王靖琰 中南大学信息科学与工程学院,长沙 (410083) E-mail:wjycsu@http://www.doczj.com/doc/52df69136c175f0e7cd13750.html 摘要:说话人识别是以话音对说话人进行区分,从而进行身份鉴别与认证的技术。本文介绍了一个用MATLAB设计的说话人识别系统,包含其原理、所采用的识别方法
(2021|NIPS,VQ-VAE,精度瓶颈松弛,三明治层归一化,CapLoss)CogView:通过转换器掌握文本到图像的生成
CogView: Mastering Text-to-Image Generation via Transformers 公众号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料) 0. 摘要 通用领域中的文本到图像生成长期以来一直是一个悬而未决的问题,这需要强大的生成模型和跨模态理解。 我们提出了 CogView,一个具有 VQ-VAE 标记器的