vits专题

从0开始训练基于自己声音的AI大模型(基于开源项目so-vits-svc)
写在前面: 本文所使用的技术栈仅为:Python 其他操作基于阿里云全套的可视化平台,只需要熟悉常规的计算机技术即可。 目录 Step 1:注册及登录阿里云主机 Step 2:找到大模型项目 Step 3:创建大模型环境实例 Step 4:进入Ai_singer教程 Step 5:环境及预训练模型下载 Step 6:训练数据准备 Step 7:数据预处理和切分配置 Ste
![[AI]从零开始的so-vits-svc webui部署教程(小白向)](https://i-blog.csdnimg.cn/direct/a50225e1883342acada23cbb1a401d9b.png)
[AI]从零开始的so-vits-svc webui部署教程(小白向)
一、本次教程是给谁的? 如果你点进了这篇教程,相信你已经知道so-vits-svc是什么了,那么我们这里就不过多讲述了。如果你还不知道so-vits-svc能做什么,可以去b站搜索一下,你大概率会搜索到一些AI合成的音乐,是的简单来讲,so-vits-svc是一个训练并且推理声音的开源项目。它能够模仿某些角色的声音来唱歌或者单纯的文字朗读。那么,我们回到正题,本次教程是给谁的?如
Bert-VITS-2 效果挺好的声音克隆工具
持中日英三语训练和推理。内置干声分离,切割和标注工具,开箱即用。请点下载量右边的符号查看镜像所对应的具体版本号。 教程地址: sjjCodeWithGPU | 能复现才是好算法CodeWithGPU | GitHub AI算法复现社区,能复现才是好算法https://www.codewithgpu.com/i/fishaudio/Bert-VITS2/Bert-VITS-2 用

CVPR 2023 Hybrid Tutorial: All Things ViTs之mean attention distance (MAD)
All Things ViTs系列讲座从ViT视觉模型注意力机制出发,本文给出mean attention distance可视化部分阅读学习体会. 课程视频与课件: https://all-things-vits.github.io/atv/ 代码: https://colab.research.google.com/github/all-things-vits/code-samples/b
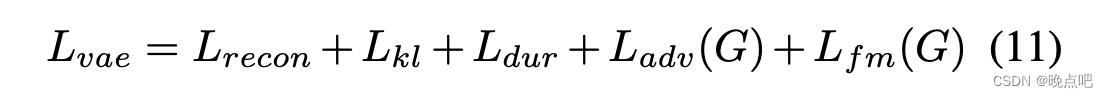
VITS(Conditional Variational Autoencoder with Adversarial Learning)论文解读及实现(一)
此篇为VITS论文解读第一部份 论文地址Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech模型使用了VAE,GAN,FLOW以及transorflomer(文本处理有用到),即除了未diffusion模型,将生成式模型都融入进来了,是一篇集大成的文章。涉及的知识点和公
TTS | emotional-vits情绪语音合成的实现
本文主要介绍了情绪语音合成项目训练自己的数据集的实现过程~ innnky/emotional-vits: 无需情感标注的情感可控语音合成模型,基于VITS (github.com) 目录 0.环境设置 1.数据预处理 2..提取情绪 3.训练 4.推理 过程中遇到的问题与解决【PS】 0.环境设置 因为我用的是之前设置vits的虚拟环境,这里可能也有写不全的的地
TTS | emotional-vits情绪语音合成的实现
本文主要介绍了情绪语音合成项目训练自己的数据集的实现过程~ innnky/emotional-vits: 无需情感标注的情感可控语音合成模型,基于VITS (github.com) 目录 0.环境设置 1.数据预处理 2..提取情绪 3.训练 4.推理 过程中遇到的问题与解决【PS】 0.环境设置 因为我用的是之前设置vits的虚拟环境,这里可能也有写不全的的地

关于VITS和微软语音合成的效果展示(仙王的日常生活第1-2209章)
目录 说明微软VITS 合成效果展示 说明 自己尝试了VITS和微软这两个语音合成功能。甚至使用了微软的效果来训练VITS,出乎意料,效果居然不错,没有大佐的口音。 微软 微软中最好听的,感情最顺滑的,应该是“云希”莫属。 不得不说,微软的速度非常之快,而且每次能合成约二万五千字,将其它软件甩在身后。 VITS 不得不说,其大佐口音很严重,哪怕是网传的原神模型,也是满满的
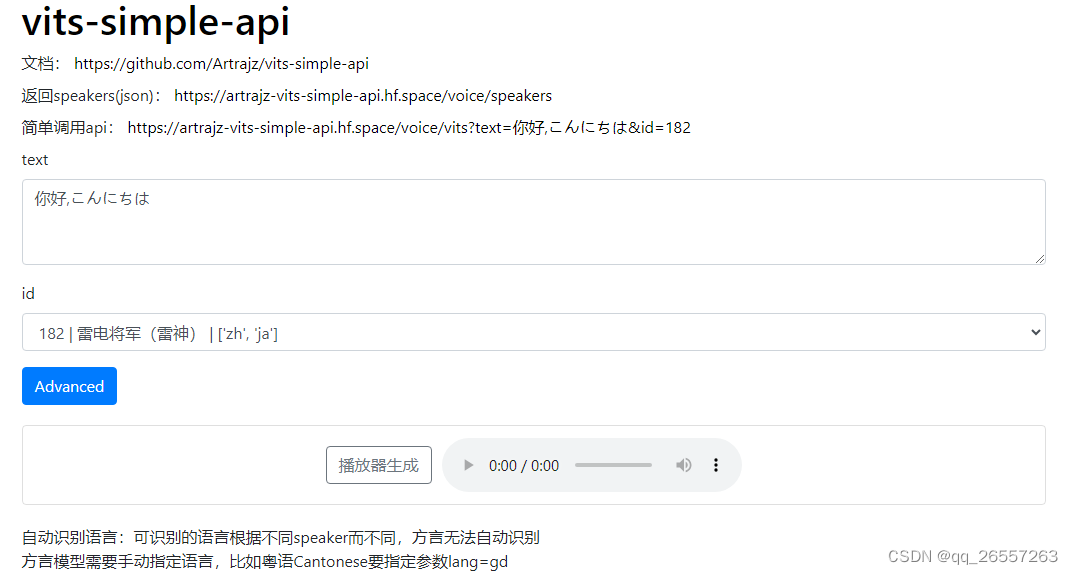
vits语音合成本地部署 vits api
github仓库:https://github.com/Artrajz/vits-simple-api 在线demo:https://huggingface.co/spaces/Artrajz/vits-simple-api 本地部署方式二选一:快速部署和源码部署 快速部署 2023.6.23更新 Windows直接下载快速部署包然后放入模型即可,省去安装依赖的时间 https://git
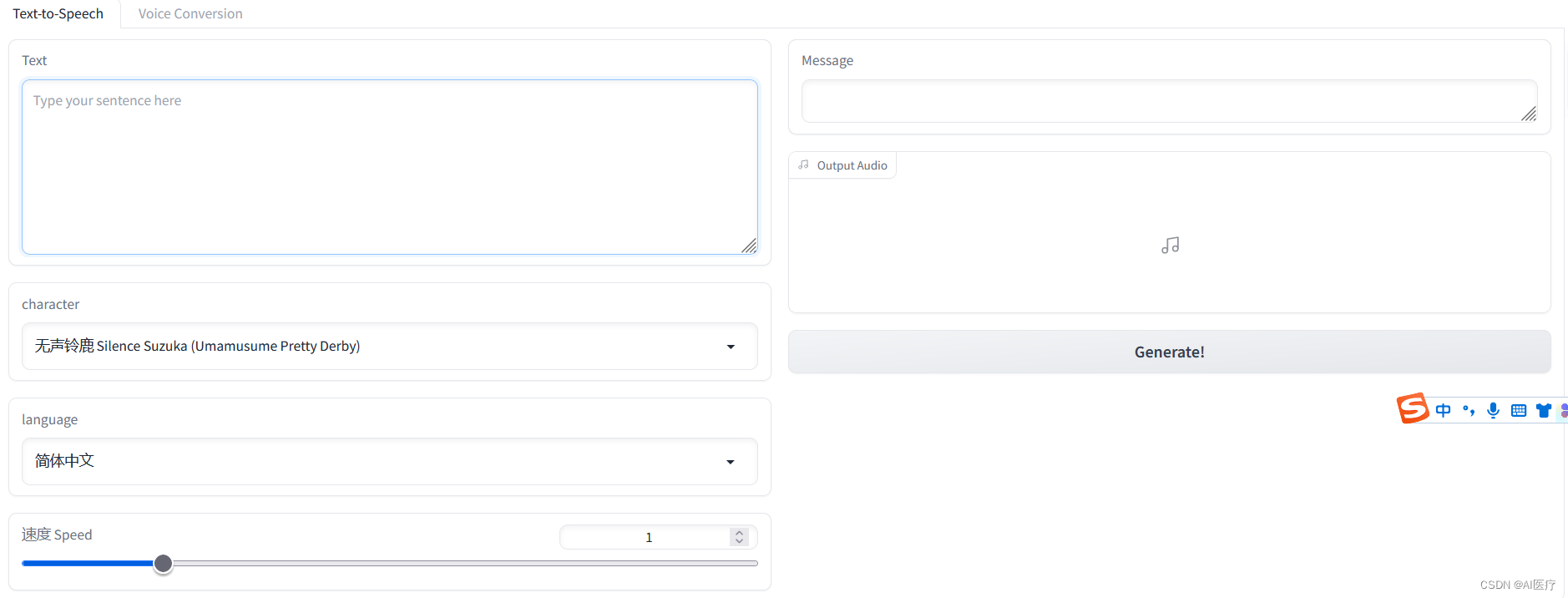
AI数字人:基于VITS-fast-fine-tuning构建多speaker语音训练
1 VITS模型介绍 VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)是一种语音合成方法,它使用预先训练好的语音编码器 (vocoder声码器) 将文本转化为语音。 VITS 的工作流程如下: (1)将文本输入 VITS 系
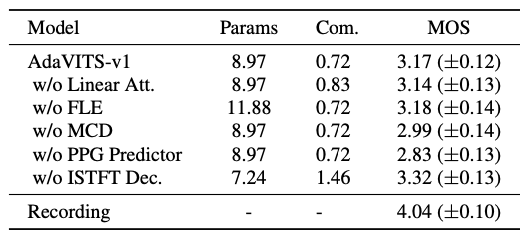
AdaVITS—基于VITS的小型化说话人自适应模型
当前主流的实现小样本音色克隆的可靠方式是说话人自适应(speaker adaption)技术,该技术通常通过在预训练的多说话人文语转换 (TTS) 模型上使用少量的目标说话人数据进行微调而获得目标说话人的TTS模型。在这一任务上已经有很多相关工作,然而很多时候说话人自适应模型需要运行在手机等资源有限的设备上,需要轻量化的方案。 近期,由西工大音频语音与语言处理研究组 (ASLP@NPU) 和腾讯
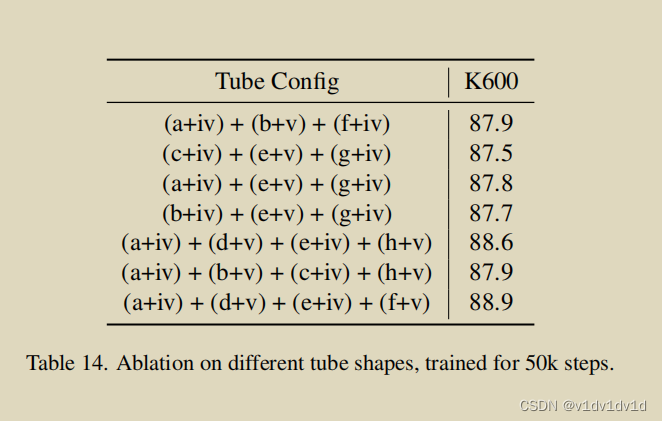
Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning(TubeViT论文翻译)
Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning AJ Piergiovanni Weicheng Kuo Anelia Angelova 论文链接 Abstract 我们提出了一个将ViT编码器变成一个有效的视频模型的方法,它可以无缝地处理图像和视频输入。通过对输入进行稀疏采样,该模型能