videopoet专题
![[WIP]Sora相关工作汇总VQGAN、MAGVIT、VideoPoet](https://img-blog.csdnimg.cn/direct/22aa1d0fcceb4c4081e72bd8d52d6907.png)
[WIP]Sora相关工作汇总VQGAN、MAGVIT、VideoPoet
视觉任务相对语言任务种类较多(detection, grounding, etc.)、粒度不同 (object-level, patch-level, pixel-level, etc.),且部分任务差异较大,利用Tokenizer核心则为如何把其他模态映射到language space,并能让语言模型更好理解不同的视觉任务,更好适配LM建模方式,目前SOTA工作MAGVIT-v2,VideoPo
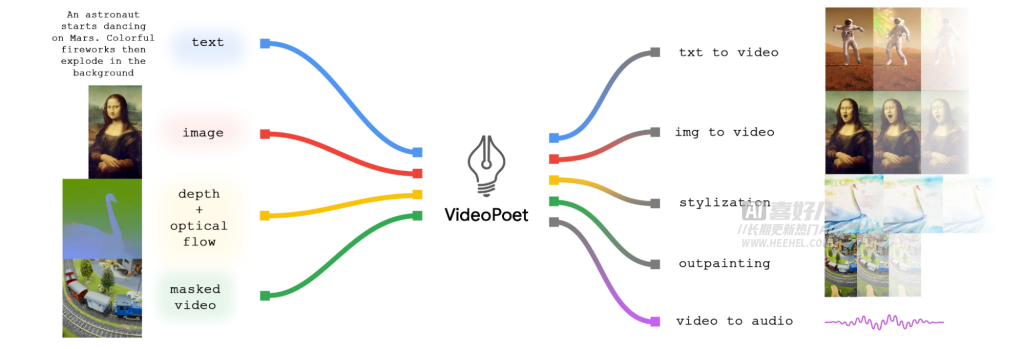
Google谷歌通过文本、图像从而生成音频和视频的多模态学习模型:VideoPoet
VideoPoet是一种多模态学习模型,本身是一个大型语言模型(LLM),能够理解和处理文本、图像、音频等多种信息,并将其融合到视频生成过程中。它不仅能够根据文字描述生成视频,还能给视频添加风格化效果、修复和扩展视频,甚至从视频中生成音频。此外,VideoPoet还能理解和生成音频,并编写用于视频处理的代码。 这种多模态学习能力使得VideoPoet在视频生成方面更加灵活和强大,能够处理
OpenAI视频生成模型Sora的全面解析:从ViViT、Diffusion Transformer到NaViT、VideoPoet
前言 真没想到,距离视频生成上一轮的集中爆发(详见《Sora之前的视频生成发展史:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0》)才过去三个月,没想OpenAI一出手,该领域又直接变天了 自打2.16日OpenAI发布sora以来(其开发团队包括DALLE 3的4作Tim Brooks、DiT一作Bill Peebles、三代DALLE的核心作者之一Adity
OpenAI视频生成模型Sora的全面解析:从ViViT、扩散Transformer到NaViT、VideoPoet
前言 真没想到,距离视频生成上一轮的集中爆发(详见《Sora之前的视频生成发展史:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0》)才过去三个月,没想OpenAI一出手,该领域又直接变天了 自打2.16日OpenAI发布sora以来(其开发团队包括DALLE 3的4作Tim Brooks、DiT一作Bill Peebles、三代DALLE的核心作者之一Adity

OpenAI视频生成模型Sora的全面解析:从扩散Transformer到ViViT、DiT、NaViT、VideoPoet
前言 真没想到,距离视频生成上一轮的集中爆发(详见《视频生成发展史:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0、W.A.L.T》)才过去三个月,没想OpenAI一出手,该领域又直接变天了 自打2.16日OpenAI发布sora以来,不但把同时段Google发布的Gemmi Pro 1.5干没了声音,而且网上各个渠道,大量新闻媒体、自媒体(含公号、微博、博客、

VideoPoet: Google的一种用于零样本视频生成的大型语言模型
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/ 介绍VideoPoet:一种能够从多种条件信号合成高质量视频及匹配音频的语言模型

谷歌推大语言模型VideoPoet:文本图片皆可生成视频和音频
Google Research最近发布了一款名为VideoPoet的大型语言模型(LLM),旨在解决当前视频生成领域的挑战。该领域近年来涌现出许多视频生成模型,但在生成连贯的大运动时仍存在瓶颈。现有领先模型要么生成较小的运动,要么在生成较大运动时出现明显的伪影。 VideoPoet的创新之处在于将语言模型应用于视频生成,支持多种任务,包括文本到视频、图像到视频、视频风格化、修复和修复以及视频到音