uniq专题
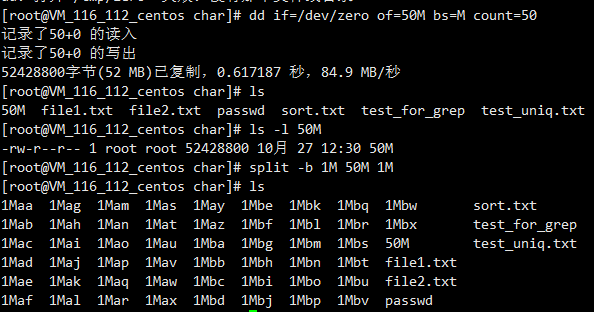
每日一shell之字符处理grep sort uniq cut tr paste split
grep搜索文本 grep -[icvn]‘匹配字符’ 文件名 -i不区分大小写 -c统计匹配行数 -n输出行号 -v反向匹配(就是不包含匹配字符的行) 需要注意的一点是有了-c这个选项输出只有行数,是不会输出内容的 sort排序 sort默认是按字符排序的 sort -[ntkr] 文件名 -n用数字排序 -t指定分割符 -k第几列 -r反向排序 这里就是按字

文本如何去重?uniq awk
对于awk '!a[$3]++',需要了解3个知识点 1、awk数组知识,不说了 2、awk的基本命令格式 awk 'pattern{action}' 省略action时,默认action是{print},如awk '1'就是awk '1{print}' 3、var++的形式:先读取var变量值,再对var值+1 以数据 1 2 3 1 2 3

uniq 求两个文件的交集,并集,差集
参照:http://blog.csdn.net/yinxusen/article/details/7450213 集合A = {a, b, c} 集合B = {d, e, c, b} $ man uniqWith no options, matching lines are merged to the first occurrence.-d, --repeatedonly print d

Linux系统sort排序与uniq去重
Linux系统sort排序与uniq去重 工作中数据太多太杂,不便于查看分析。这时是可以采用sort将数据排序,同时可以配合uniq命令进行去重。 场景:云平台中,日常工作包含巡检工作,是通过事先编写好的巡检脚本去检测云平台的和Node节点(Linux系统)的健康情况。有问题的信息会打印保存在日志中,这里面包含了很多IP(Node),而且具有大量重复IP(成百上千个IP等)。 为了定位到哪些

【shell】sort uniq
sort可以对文件内容进行排序,可以指定多个文件,默认按照字典序排序。 如果要按照数字排序,可以使用-n参数。 如果文件有多列,列是以空格区分的,那么可以指定按照特定的列排序,使用-k参数,1表示第一列。 使用-r参数可以逆序排序。 uniq只能接受一个排序文件为输入,所以sort管道uniq是一个常见用法。 uniq只会显示不重复的行,意味着如果本来就不重复,会显示,
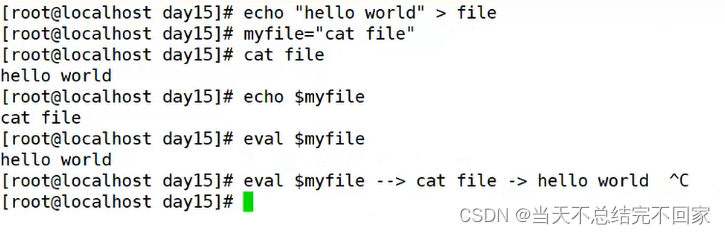
shell脚本之sort,uniq,tr,cut,sphit,paste,ecal与正则表达式
sort命令 uniq命令 tr命令 cut命令 sphit命令 paste命令 ecal命令 正则表达式 sort命令 sort命令---以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序 比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。 语法格式: sort [选项] 参数 先是对首字母进行排序,如果首字母相同则对第二
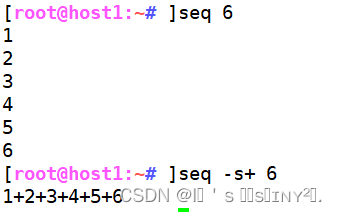
Linux文本处理工具【tr、cut、sort、uniq】
1. tr 命令——替换、压缩、删除 tr (Text Replacer) 命令常用来对来自标准输入的字符进行替换、压缩和删除。 命令格式 :tr [选项]... SET1 [SET2] (SET 是一组字符串,一般都可按照字面含义理解) 选项: -d 删除 -s 压缩 tr 1 a //遇到1换成 tr -d 1 //把1删除 tr -s 1 //压缩连续的1 tr -
linux 去除重复行 uniq
uniq干什么用的 文本中的重复行,基本上不是我们所要的,所以就要去除掉。linux下有其他命令可以去除重复行,但是我觉得uniq还是比较方便的一个。使用uniq的时候要注意以下二点 1,对文本操作时,它一般会和sort命令进行组合使用,因为uniq 不会检查重复的行,除非它们是相邻的行。如果您想先对输入排序,使用sort -u。 2,对文本操作时,若域中为先空字符(通常包括空格以及

Linux 文件类信息统计指令(grep、awk、sort、uniq)
文章目录 grep过滤关键字cat 查看文件cat 配合awk筛选文件中某一列cat配合awk、sort、uniq做数据统计cat配合grep、awk、sort、uniq做数据统计 grep过滤关键字 cat file |grep -o word |wc -l 统计file文件中word这个关键字出现的个数cat file |grep word |wc -l 统计file文
Linux下uniq命令的详解
uniq uniq 命令 文字 uniq是LINUX命令 用途 报告或删除文件中重复的行。 语法 uniq [ -c | -d | -u ] [ -f Fields ] [ -s Characters ] [ -Fields ] [ +Characters ] [ InFile [ OutFile ] ] 描述 uniq 命令删除
每天学习一个Linux命令之uniq
每天学习一个Linux命令之uniq 介绍 在Linux操作系统中,有许多强大的命令可以帮助我们提高工作效率。本篇博客将详细介绍一个非常有用的命令:uniq。uniq命令用于从已排序的文件或标准输入中删除重复的行,并将结果输出到标准输出中。 命令格式 uniq [选项] [输入文件] 选项 uniq命令有许多可用的选项,让我们逐个来了解一下每个选项的用法。 -c:在输出行前加上该行
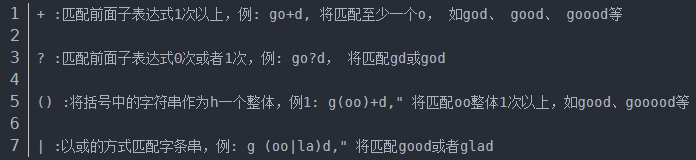
sort,tr,uniq,cut和正则表达式
sort 概念 以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序 sort 选项 参数 cat file | sort 选项 常用选项 -f:忽略大小写,默认会大写字母排在前面 -b:忽略每行前面的空格 -n:按照数字进行排序 -r:反向排序 -u:等同uniq,表示相同的数据仅显示一行,去重 -t:指定字段分隔符,默认使用tab键分隔 -k:指定排序字段 -o <输出文件>:
Linux Bash Shell (四)--sort 和uniq命令
Linux Bash Shell (四)–sort 和uniq命令 前言 这篇文章主要介绍Linux Bash Shell 中的sort和uniq命令。 sort命令可以对文本文件进行排序,经常和其他命令通过管道的方式结合使用。 而uniq 命令要求输入必须是排好序的数据,否则结果就不会准确,有序是uniq命令得到正确结果的基础。 接下来让我们一起来学习sort和uniq命令吧~ sort
linux命令详解——uniq,wc,tr
uniq uniq可以对查看内容去重 但在我们使用时会发现,uniq的去重逻辑是,当遇到连续多行内容相同时,去除重复行,而对间隔重复内容,无法实现去重功能 这里想到可以将sort与uniq结合使用,先对文件内容进行排序,将相同内容行紧邻,然后再使用uniq去重(使用管道符将一个命令的结果作为另一个命令的输入) 对于uniq命令来说,可以使用参数-c来统计重复行出现次数
linux sort uniq -c
文档编辑--sort 功能说明: 将文本文件内容加以排序。 语 法: sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][--help][--verison][文件] 补充说明: sort可针对文本文件的内容,以行为单位来排序。 参 数: -b 忽略每行前面开始出的空格字符。 -c 检查文件是否

shell中常用的基础命令(diff、patch、cut、sort、uniq、tr、test、 ||)
shell中常用的基础命令 一、diff二、patch三、cut四、sort五、uniq六、tr七、&& ||八、test 一、diff 1、用法: diff [options] files|directorys 2、输出信息: [num1,num2][a|c|d][num3,num4] num1,num2 第一个文件中的行a
Linux命令:uniq命令和wc命令
目录 1 uniq命令1.1 uniq简介1.2说明1.3案例1、默认输出2、输出重复行3、比较一行中的部分字符4、忽略大小写5、只显示唯一的行 2.4 uniq和sort命令配合使用1、文本统计2、统计IP连接数并排序 2 wc命令2.1 wc简介2.2 说明2.3 案例1、默认输出2、输出字节、字符数、单词数 总结 1 uniq命令 1.1 uniq简介 uniq 命令
常用的几个linux下的文本编辑命令cut、paste、sort、uniq
虽然我更喜欢awk和sed,但是如果能把这几个命令能活用的话一般的文本编辑就不在话下了,而且这几个命令更简单方便一点,但是功能相比awk和sed稍差一点。 一、cut命令 二、paste命令 三、sort命令 四、uniq命令
uniq命令使用方法介绍
来自:http://www.enet.com.cn/article/2008/0805/A20080805341365.shtml uniq命令的作用:显示唯一的行,对于那些连续重复的行只显示一次! 接下来通过实践实例说明: [root@stu100 ~]# cat test boy took bat home boy took bat home girl took b

文本操作(1)——cut,tr,sort,uniq命令
》》》CUT命令 1,选项: 2,示范: 》》》TR命令 1, 替换字符/字符串,将a转换为A、将b转换为B、将c转换为C: tr abc ABC < 2,压缩字符,将连续相同的字符x······压缩成为一个字符x: tr -s x
用 uniq 除去重复行(Shell技巧1)
用uniq除去重复行(转载IBM developerWorks 中国) 重复行通常不会造成问题,但是有时候它们的确会引起问题。此时,不必花上一个下午的时间来为它们编制过滤器,uniq 命令便是唾手可得的好工具。 了解一下它是如何节省您的时间和精力的。进行排序之后,您会发现有些行是重复的。有时候该重复信息是不需要的,可以将它除去以节省磁盘空间。不必对文本行进行排序,但是您应当记住 uniq
你是唯一的 uniq
文章目录 你是唯一的 uniq语法默认无参数统计出现频次仅仅显示重复的行仅仅显示不重复的行更多信息 你是唯一的 uniq Linux uniq 命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用。 官方定义为: uniq - report or omit repeated lines uniq 可检查文本文件中重复出现的行列。 语法 语法
uniq常用选项-c-d-u的来源和3种显示方式或3种基本用法
-c, --count prefix lines by the number of occurrences\n\ -d, --repeated only print duplicate lines, one for each group\n\ "), stdout); -u, --unique only print unique line
uniq -d选项源代码分析
csdn上还真有人分析这个命令的源代码。 其实不容易啦。 最后一个 d d d d 其实是用得check_file函数里面的//457行的 writeline函数。 [root@localhost src]# gdb ./uniq GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-94.el7 Copyright (C) 2013 F
Shell中uniq命令的用法
一、uniq命令的作用 报告或忽略文件中的重复行,一般与sort命令结合使用 二、使用格式 语法:uniq (选项) (参数) 选项列表: -c或–count:在每列旁边显示该行重复出现的次数-d或–repeated:仅显示重复出现的行列-f<栏位>或–skip-fields=<栏位>:忽略比较指定的栏位-s<字符位置>或–skip-chars=<字符位置>:忽略比较指定的字符-u或–