本文主要是介绍sort,tr,uniq,cut和正则表达式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
sort
概念
以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序
sort 选项 参数
cat file | sort 选项
常用选项
-f:忽略大小写,默认会大写字母排在前面
-b:忽略每行前面的空格
-n:按照数字进行排序
-r:反向排序
-u:等同uniq,表示相同的数据仅显示一行,去重
-t:指定字段分隔符,默认使用tab键分隔
-k:指定排序字段
-o <输出文件>:将排序后的结果转存至指定文件

uniq
概述
用于报告或者忽略文件中连续的重复行,常与sort命令结合使用
常用选项
-c:进行计数,并删除文件中重复出现的行
-d:仅显示连续的重复行
-u:仅显示出现一次的行


tr
用于对来自标准输入的字符进行替换、压缩和删除
-c:保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换
-d:删除所有属于字符集1的字符
-s:将重复出现的字符串压缩为一个字符串,用字符集2 替换 字符集1
-t:字符集2 替换 字符集1,不加选项同结果




cut命令
显示行中的指定部分,删除文件中指定字段语法格式
常用选项
-f :通过指定哪一个字段进行提取。cut命令使用"T海B"作为默认的字段分隔符。
-d : "TAB”是默认的分隔符,使用此选项可以更改为其他的分隔符。
–complement :此选项用于排除所指定的字段。
–output-delimiter :更改输出内容的分隔符。
删除windows文件"’^M’字符


正则表达式
正则表达式是通过一些特殊字符的排序,用以删除、查找、替换一行或者多行文字字符串的程序。
字符类

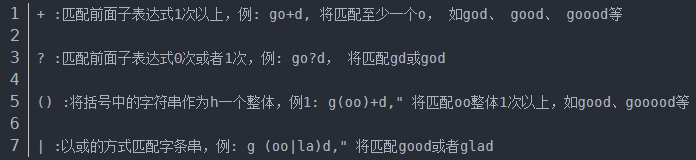
数量限定符
这篇关于sort,tr,uniq,cut和正则表达式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







