本文主要是介绍每日一shell之字符处理grep sort uniq cut tr paste split,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
grep搜索文本
grep -[icvn]‘匹配字符’ 文件名
-i不区分大小写
-c统计匹配行数
-n输出行号
-v反向匹配(就是不包含匹配字符的行)
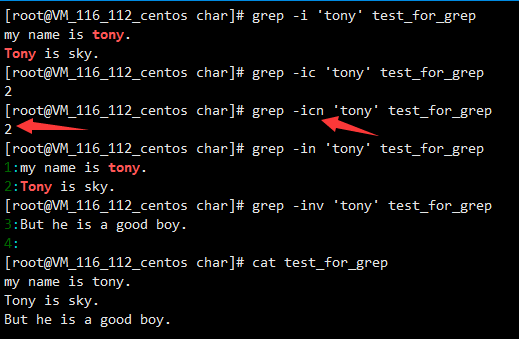
需要注意的一点是有了-c这个选项输出只有行数,是不会输出内容的
sort排序
sort默认是按字符排序的
sort -[ntkr] 文件名
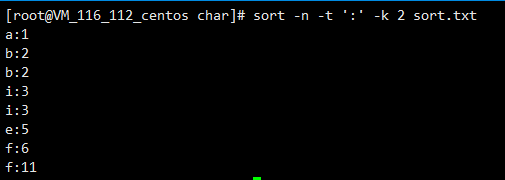
-n用数字排序
-t指定分割符
-k第几列
-r反向排序
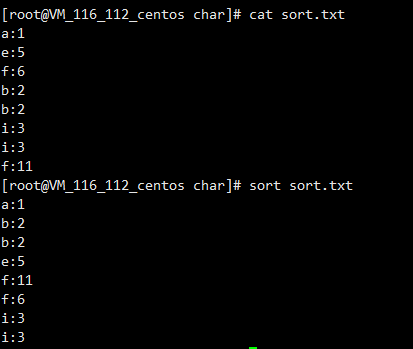
这里就是按字母顺序
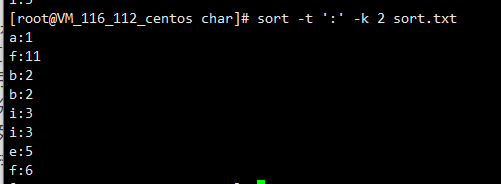
这里的11就是字母排序
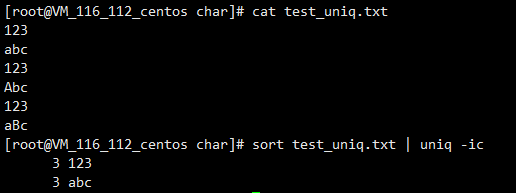
uniq删除重复内容
一般这个命令需要和sort一起用
uniq -[ic]
-i忽略大小写
-c统计重复的行数
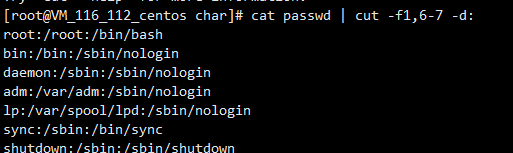
cut截取文本
cut -f指定列 -d分隔符
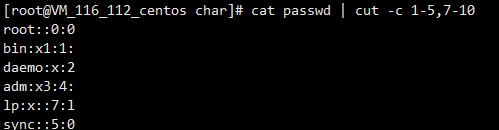
cut -c指定列的字符
注意空格
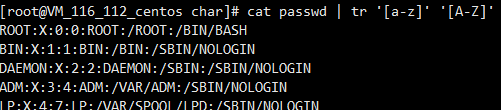
tr做文本转换
大小写转换
tr '[a-z]' '[A-Z]'
删除
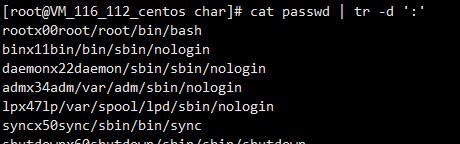
tr -d '删除内容'
顺便说一下这里的命令不会改变源文件的内容
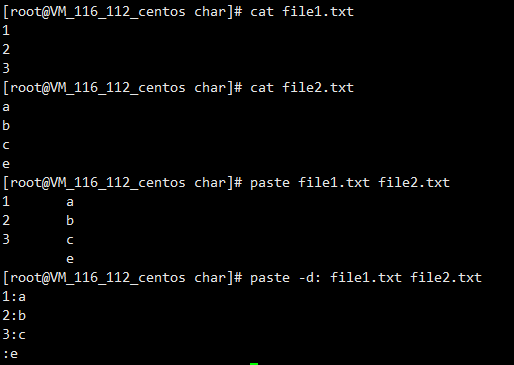
paste做文本合并
按行进行合并
paste file1 file2
paste -d:指定分隔符为冒号
split分割大文件
split -l按行分
split -b按大小分(二进制文件只能用按大小分)
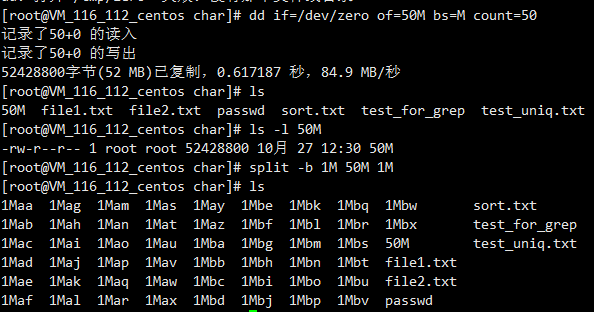
这里用了dd命令创建了一个指定大小的文件
dd if=/dev/zero of=50M bs=M count=50
if是数据的写入源
of是数据的输入地
bs是后面count值的单位
dd命令是 用指定大小的块 来拷贝一个文件。
这篇关于每日一shell之字符处理grep sort uniq cut tr paste split的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






