ucs专题

Python 全栈系列255 UCS实践:按ID同步数据
说明 这是一个常见的使用场景,实测下来效果良好。 内容 1 实验场景 将库中所有的数据取出,送到队列 本质上,这是一种单向不返回的模式。除了在遍历全库有用,在进行回测时也是一样的,时间就是单向不返回的。 通过UCS,将任意离散的数据记录归并到了一个更大的单位下。按照brick、block、part、shard四个层级,使得数据的管理兼顾到人的记忆特性,以及程序批量处理的效率。一个
phthon踩雷(二):UnicodeEncodeError: ‘UCS-2‘ codec can‘t encode characters in position...
报错如下: UnicodeEncodeError: 'UCS-2' codec can't encode characters in position 3298-3298: Non-BMP character not supported in Tk 翻译一下就是: Unicode编码错误:'UCS-2’编码器不能编码在3298-3298这个位置的字符类: Non-BMP 字符类在Tk中不

一致代价搜索(UCS)的原理和代码实现
一:基本原理 一致代价搜索是在广度优先搜索上进行扩展的,也被成为代价一致搜索,他的基本原理是:一致代价搜索总是扩展路径消耗最小的节点N。N点的路径消耗等于前一节点N-1的路径消耗加上N-1到N节点的路径消耗。 图的一致性代价搜索使用了优先级队列并在边缘中的状态发现更小代价的路径时引入的额外的检查。边缘的数据结构需要支持有效的成员校测,这样它就结合了优先级队列和哈
Unicode、UCS和UTF
问题一: 使用Windows记事本的“另存为”,可以在GBK、Unicode、Unicode big endian和UTF-8这几种编码方式间相互转换。同样是txt文件,Windows是怎样识别编码方式的呢? 我很早前就发现Unicode、Unicode big endian和UTF-8编码的txt文件的开头会多出几个字节,分别是FF、FE(Unicode),FE、FF(Unicod

思科ucs-b系列服务器部署window2008安装手册,思科统一计算系统UCS B系列刀片推荐...
【IT168 导购】如今,融合基础架构可谓大行其道,其能够整合系统,缩短部署时间,提高资源利用率并降低成本,得到了企业用户的广泛认可。作为融合基础架构的核心关键的计算平台,刀片基础架构则可以在机箱层面中实现很好的整合功能,有助于简化运营、实现集中化管理并降低运营成本,让管理员在一个视图中管理服务器、交换和存储。目前,越来越多的用户已经体验到刀片系统作为IT计算平台的整合优势,同时,刀片服务器整体

UTF8转UCS——被微软折磨的日子
前言 前段时间搞协议,遇到些编码的问题,非英文的字符一直传输失败。搞得还以为开发者不支持中文,还给大佬发了个邮件,Is there any plan to support non-English?。大佬一直没回我,不知道是感觉我问的太傻X了还是没看到我的邮件。 研究了下协议传递非英文字符的问题,这个协议必须把字符串以utf8格式传进去,然后这个协议将utf8编码转换成UCS2,再通过网络发出去。
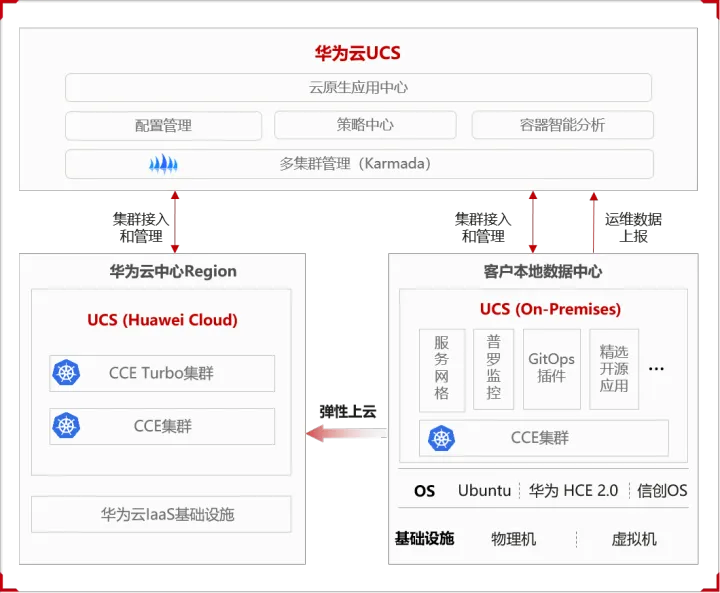
华为云 UCS (On-Premises):运行在您本地数据中心的CCE集群
摘要:华为云分布式云原生UCS服务,是面向分布式云场景下的新一代云原生产品,提供UCS (Huawei Cloud)、UCS (Partner Cloud)、UCS (Multi-Cloud)、UCS (On-Premises) 以及UCS (Attached Clusters) 等产品,覆盖公有云、多云、本地数据中心、边缘等分布式云场景。 本文分享自华为云社区《华为云 UCS (On-P
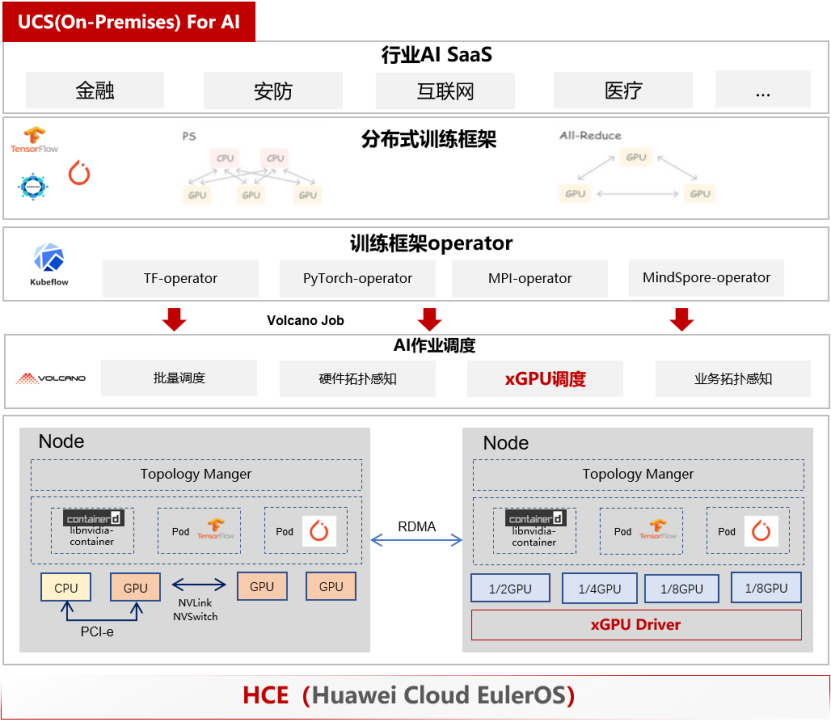
使用 UCS(On-Premises) 管理您的GPU资源池,释放AI大模型算力潜能
本文分享自华为云社区《使用 UCS(On-Premises) 管理您的GPU资源池,释放AI大模型算力潜能》,作者:云容器大未来。 AI 技术现状及发展趋势 过去十余年,依托全球数据、算法、算力持续突破,人工智能全面走向应用,已成为社会生产生活的支柱性技术。2020年后,当自动驾驶、人脸识别等热门应用发展逐渐放缓、社会对人工智能整体发展预期日益冷静时,大模型技术潜力的释放以最振聋发聩的方式宣告
![UCS(统一计算系统)[2]](https://img-blog.csdnimg.cn/bbbf053e683146f3a9ed838a33b6becd.png)
UCS(统一计算系统)[2]
5 UCS SAN配置 FC Port-Channels和Trunking 类似以太网的Port-Channels 1.把多条链路绑定到一起 2.允许更好的负载分配 3.仅仅在MDS或者Nexus FC交换机上被支持 Trunking 也非常类似于以太网的Trunks 1.允许多个VSAN在一条链路中传输 VSANs(Virtual Storage Area Networks)类似VLANs