trpo专题
11.3、信赖域策略优化算法TRPO强化学习-运用实践
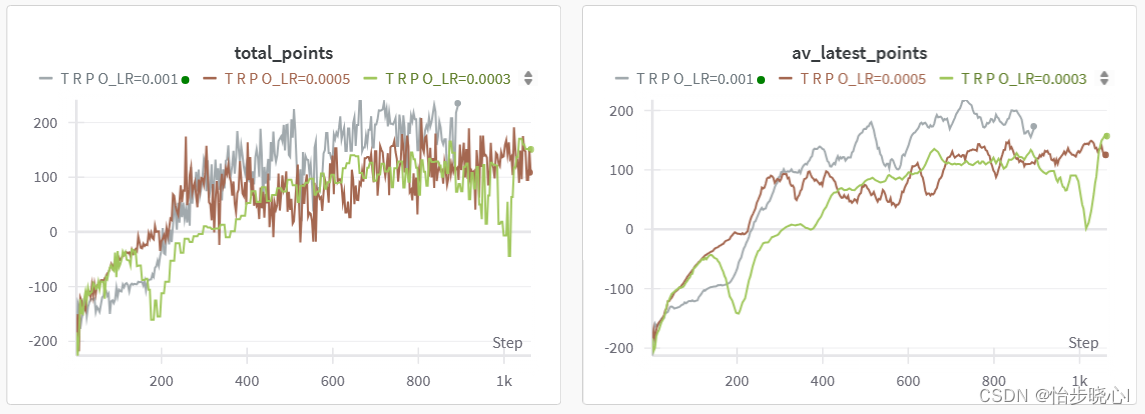
基于LunarLander登陆器的TRPO强化学习(含PYTHON工程) TRPO强化学习算法主要分为3个部分,分别介绍其理论、细节、实现 本文主要介绍TRPO的理论和代码的对应、实践 TRPO系列(TRPO是真的复杂,全部理解花费了我半个月的时间嘞,希望也能帮助大家理解一下): 11.1、信赖域策略优化算法TRPO强化学习-从理论到实践 11.2、信赖域策略优化算法TRPO强化学习-约束优
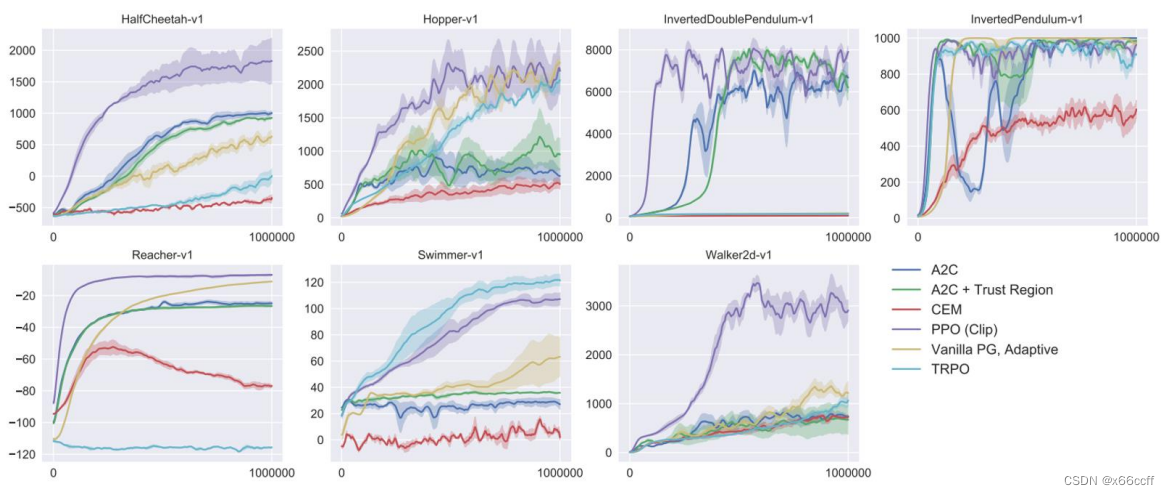
【深度强化学习】TRPO、PPO
策略梯度的缺点 步长难以确定,一旦步长选的不好,就导致恶性循环 步长不合适 → 策略变差 → 采集的数据变差 → (回报 / 梯度导致的)步长不合适 步长不合适 \to 策略变差 \to 采集的数据变差 \to (回报/梯度导致的)步长不合适 步长不合适→策略变差→采集的数据变差→(回报/梯度导致的)步长不合适 一阶信息不限制步长容易越过局部最优,而且很难回来 TRPO 置信域策略优

【强化学习】15 —— TRPO(Trust Region Policy Optimization)
文章目录 前言TRPO特点策略梯度的优化目标使用重要性采样忽略状态分布的差异约束策略的变化近似求解线性搜索算法伪代码广义优势估计代码实践离散动作空间连续动作空间 参考 前言 之前介绍的基于策略的方法包括策略梯度算法和 Actor-Critic 算法。这些方法虽然简单、直观,但在实际应用过程中会遇到训练不稳定的情况。回顾一下基于策略的方法:参数化智能体的策略,并设计衡量策略好坏的目