t2i专题

AIGC-AnimateDiff-基于T2I模型的动态生成论文详细解读
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning github:https://github.com/guoyww/animatediff/ 论文:https://arxiv.org/abs/2307.04725 AnimateDiff 通过预训练

Diffusers代码学习: T2I Adapter
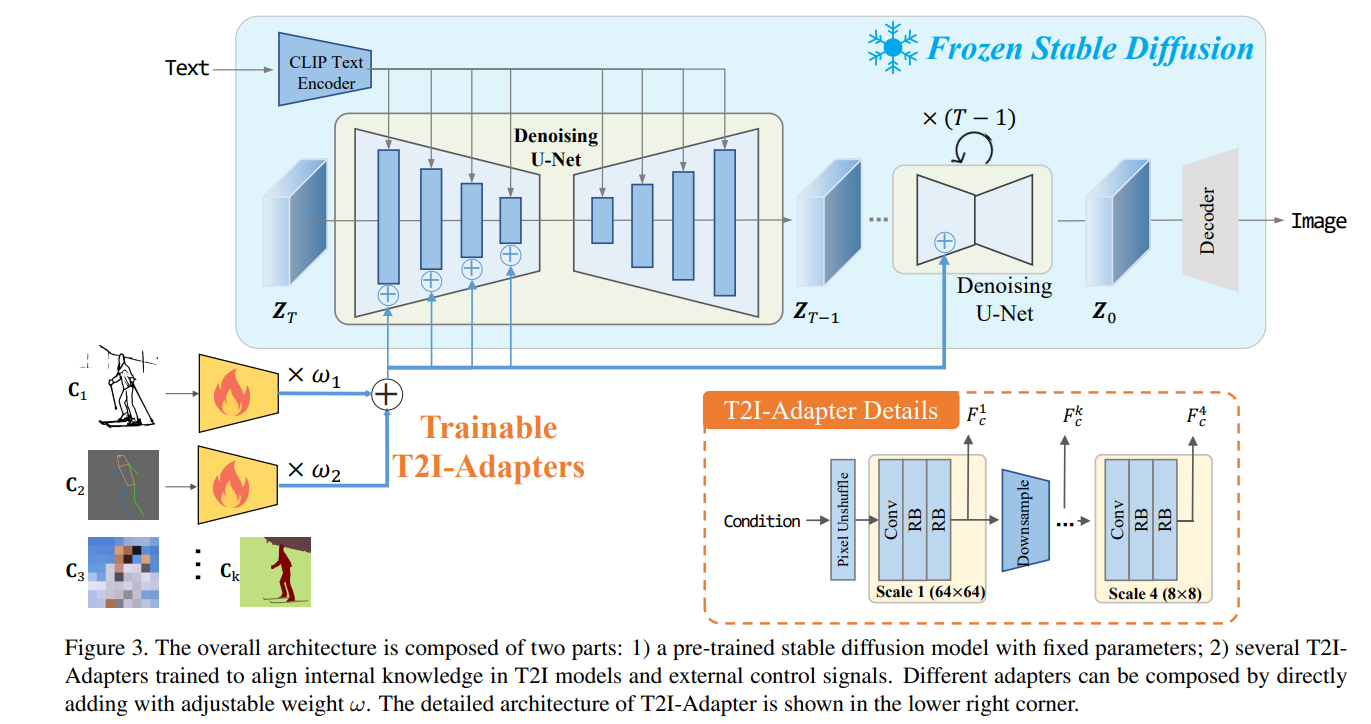
T2I Adapter是一款轻量级适配器,用于控制文本到图像模型并为其提供更准确的结构指导。它通过学习文本到图像模型的内部知识与外部控制信号(如边缘检测或深度估计)之间的对齐来工作。 T2I Adapter的设计很简单,条件被传递到四个特征提取块和三个下采样块。这使得针对不同的条件快速而容易地训练不同的适配器,这些适配器可以插入到文本到图像模型中。T2I Adapter与ControlNet

T2I-Adapter:学习适配器为文本到图像扩散模型挖掘更多可控能力
文章目录 一、研究动机二、T2I-Adapter的特点三、模型方法(一)关于stable diffusion(二)适配器设计1、结构控制2、空间调色板3、多适配器控制 (三)模型优化训练期间的非均匀时间步采样 一、研究动机 T2I模型,也就是文本到图像模型(text-to-image model)具备强大的生成能力,能够学习到复杂的内部结构和语义信息。但是仅仅依靠文本提示

AI之T2I:Stable Diffusion 3的简介、安装和使用方法、案例应用之详细攻略
AI之T2I:Stable Diffusion 3的简介、安装和使用方法、案例应用之详细攻略 目录 Stable Diffusion 3的简介 1、效果测试 官方demo 网友提供 Stable Diffusion 3的安装和使用方法 1、安装 2、使用方法 Stable Diffusion 3的案例应用 1、基础案例 Stable Diffusion

T2I:zero shot笔记
1 Title Zero-Shot Text-to-Image Generation(Aditya Ramesh 、 Mikhail Pavlov 、Gabriel Goh Scott Gray、 Chelsea Voss 、 Alec Radford 、 Mark Chen 、Ilya Sutskever) 2 Conclusion This
AI之T2I:Stable Diffusion 3的简介、安装和使用方法、案例应用之详细攻略
AI之T2I:Stable Diffusion 3的简介、安装和使用方法、案例应用之详细攻略 目录 Stable Diffusion 3的简介 1、效果测试 官方demo 网友提供 Stable Diffusion 3的安装和使用方法 1、安装 2、使用方法 Stable Diffusion 3的案例应用 1、基础案例 Stable Diffusion

文生图可控生成之T2I-adapter原理
论文:T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models代码:TencentARC/T2I-Adapter系列文章: 可控生成之ControlNet原理可控生成之GLIGEN原理 文章目录 1. 动机及贡献2. Method2.1
T2I-Adapter: 让马良之神笔(扩散模型)从文本生成图像更加可控
文章信息 单位:北大深张健团队,腾讯ARC lab 源码: https://github.com/TencentARC/T2I-Adapter 图1. 插个DXL的渲染图,这么真实的光感,感觉PS都可以被取代了 目录 文章信息前言一、介绍二、相关工作1.图像合成与转换2 扩散模型3 适配器 三、T2I适配器总结 前言 大规模的text2image模型具有
文本生成图像工作简述5--对条件变量进行增强的 T2I 方法(基于辅助信息的文本生成图像)
目录 一、基于场景图的文本生成图像二、基于对话的文本生成图像三、基于属性驱动的文本生成图像四、基于边界框标注的文本生成图像五、基于关键点的文本生成图像六、其他基于辅助信息的文本生成图像 在传统的T2I方法中,常常使用一个固定的随机噪声向量作为输入,然后通过生成器网络来生成图片。而条件变量增强的T2I方法则通过引入额外的条件信息来生成更具特定要求的图片, 这个条件信息可以是任何与图片