smoothing专题

GNN中的Over-smoothing与Over-squashing问题
Over-squashing (过度压缩,顾名思义就是数据被“压缩”的过分小了,导致学不到什么东西。) 1、 why 会被压缩的过分小? 可能因为网络过深,那么在多层传播后,信息可能会被过度压缩(本质是特征减少了,当层数过多时会大大杂糅信息,导致特征减少,输出维度过小也会),导致细节丢失。 2、why 学不到什么东西? 会加剧梯度消失的现象,导致早期层几乎不学习,从而使得输入信息的重要细
标签平滑(Label Smoothing)
标签平滑(Label Smoothing)是一种正则化技术,用于深度学习模型的训练过程中,特别是在分类任务中。这种技术的目的是防止模型对于训练数据中的某些标签过于自信,从而可能导致过拟合。在过拟合的情况下,模型在训练数据上表现很好,但在未见过的测试数据上泛化能力较差。 在没有标签平滑的传统训练过程中,我们通常使用硬目标(hard targets),即每个训练样本的目标标签用一个one-hot编码

NLP学习06_评估语言模型smoothing
估计语言模型的概率 Unigram 首先统计语料库中所有的单词个数,然后统计每个单词出现的概率, 计算整句的概率 但是这种LM中,如果一个句子中的单词在语料库中没有出现,那么这个词的概率为0,这就导致整个句子概率为0 这显然是不合适的,用到一个平滑操作,使得虽然概率很小,但是不让它为0 Bigram 除了第一个单词的概率要通过Unigram计算,其他后边都是条件概率,要先在语料库找到条件

了解CSS属性font-kerning,font-smoothing,font-variant
本文很简单,了解几个可能平时用得不太多,长得不太熟的font相关的几个CSS属性,分别是:font-kerning, font-smoothing和font-variant。 字距调整属性font-kerning font-kerning应该算是一个CSS3属性,主要作用是调整字形间距,且基本上是英文字符形状的间距,因为英文字符形状都是不规则的,有宽有窄,有的圆乎乎,有的棱角分明,就会导致排列

css3新特性-webkit-font-smoothing
一 (1)-webkit-font-smoothing:可以使页面上的字体抗锯齿,使用后字体看起来会更清晰舒服。 属性含义none对低像素的文本比较好subpixel-antialiased默认值antialiased抗锯齿很好 (2)-moz-osx-font-smoothing: inherit | grayscale Gecko内核的浏览器火狐吧,认识到字体图标逐渐发展的一个热潮,也针
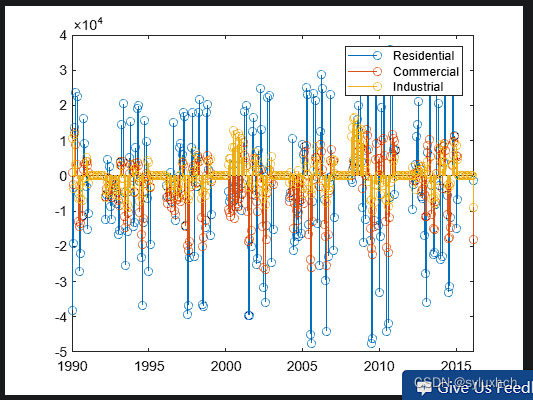
MATLAB Fundamentals>>>Smoothing Electricity Data
MATLAB Fundamentals>Common Data Analysis Techniques>Smoothing Data> (3/5) Smoothing Electricity Data 数据准备:This code sets up the activity. load electricityDatawhostotal = usage(:,end);sectorUsage

PCL-表面(Surface)Smoothing and normal estimation based on polynomial reconstruction
Moving Least Squares(MLS) 移动最小二乘法,可以用来平滑和重采样,接下来将介绍使用方法。https://en.wikipedia.org/wiki/Moving_least_squares(MLS介绍) 使用统计分析很难去除一些数据不规则(由小距离测量误差引起)。 要创建完整的模型,必须考虑光泽表面以及数据中的遮挡。 在无法获得额外扫描的情况下,解决方案是使用重采样算法,
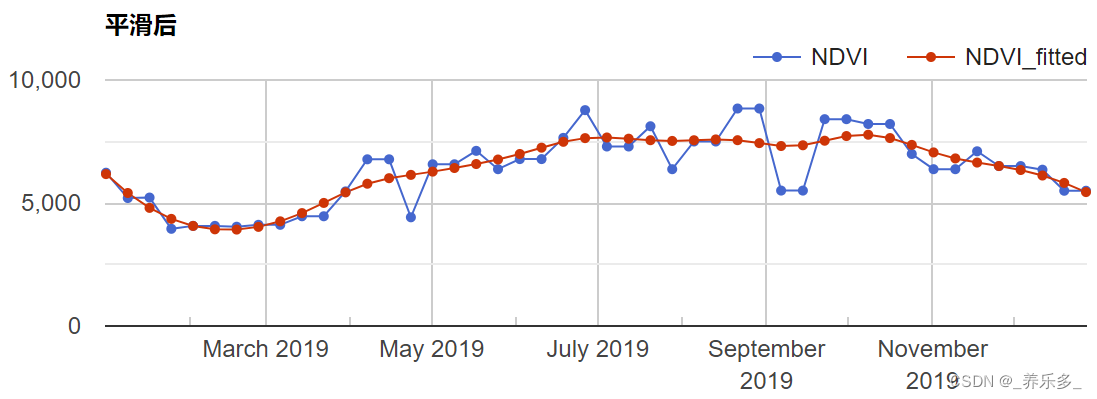
GEE:Whittaker Smoothing 时间序列平滑算法
本文将介绍 Whittaker Smoothing 时间序列数据平滑算法。Whittaker Smoothing 对于一个给定的时空图像集合,它可以生成平滑的时间序列图像。 具体而言,这些函数实现了以下过程: extractBits函数将从一个 QA 图像中提取一些特定的比特位,返回一个新的单波段图像,其中每个像素的值代表了提取出的比特位。getDifferenceMatrix函数生成一个
