rosalind专题

Bio-Info每日一题:Rosalind-05-Computing GC Content
🎉 进入生物信息学的世界,与Rosalind一起探索吧!🧬 Rosalind是一个在线平台,专为学习和实践生物信息学而设计。该平台提供了一系列循序渐进的编程挑战,帮助用户从基础到高级掌握生物信息学知识。无论你是初学者还是专业人士,Rosalind都能为你提供适合的学习资源和实践机会。 网址:https://rosalind.info 你是否想像专业人士一样分析DNA序列?这里有一个简单的任务来

Bio-Info 每日一题:Rosalind-04-Rabbits and Recurrence Relations
🎉 进入生物信息学的世界,与Rosalind一起探索吧!🧬 Rosalind是一个在线平台,专为学习和实践生物信息学而设计。该平台提供了一系列循序渐进的编程挑战,帮助用户从基础到高级掌握生物信息学知识。无论你是初学者还是专业人士,Rosalind都能为你提供适合的学习资源和实践机会。网址:https://rosalind.info 你是否想像专业人士一样分析DNA序列?这里有一个简单的任务来帮

Rosalind Java|Speeding Up Motif Finding
Rosalind编程问题之计算错误矩阵(failure array)输出前后缀检索匹配。 Speeding Up Motif Finding Problem: A prefix of a length n string s is a substring s[1:j]; a suffix of s is a substring s[k:n]. The failure array of s is

Rosalind 043 Comparing Spectra with the Spectral Convolution
这个问题是关于如何比较两个蛋白质的质谱图的相似性。在生物信息学和质谱分析中,这个问题非常重要,尤其是在蛋白质组学领域。 背景 质谱图与蛋白质:在蛋白质组学中,质谱仪用于分析蛋白质。将蛋白质分解成多个肽段后,会产生一个质谱图,这是质荷比(m/z)和强度的图表。质谱图中的每一个峰代表蛋白质的一个片段,其位置对应该片段的质量。 简化的谱图:这个问题将质谱图简化为实数的多重集,每个数代表一个肽段的
Rosalind 042 Inferring Protein from Spectrum
这个问题涉及生物信息学中的一项特定任务:根据给定的前缀质谱(prefix spectrum)来推断蛋白质序列。 背景 蛋白质和氨基酸:蛋白质是由氨基酸残基构成的长链分子,每种氨基酸具有特定的质量。前缀质谱:这是指蛋白质序列从起始到某个点的所有片段的质量。例如,蛋白质“ACD”的前缀质谱包括氨基酸“A”的质量,氨基酸“AC”的质量,以及整个序列“ACD”的质量。单体同位素质量表:这是一个表,列出
Rosalind 041 Introduction to Set Operations
背景: 这个问题是关于集合论的基础练习,集合论是数学的一个基本领域,涉及到集合的研究,集合是对象的集合。 并集 (A∪B):这个操作结合了集合 A 和 B 中的所有元素,并去除了重复的元素。它的结果是一个新的集合,包含了在 A、B 中或同时在 A 和 B 中的每个元素。 交集 (A∩B):这个操作找出集合 A 和 B 之间的共同元素。结果集合包含了同时在 A 和 B 中的所有元素。

Rosalind 040 Distances in Trees
这个问题涉及到图论中的树结构以及如何使用Newick格式来表示树。下面是关键概念的解释和解决问题的方法: 图论中的树理解 树中的唯一路径:在树这种图结构中,任意两个节点之间总是存在一条唯一的路径。这种唯一性是因为树是一个连通的、无循环的图。如果两个节点之间存在多条路径,就会形成一个循环,这在树中是不允许的。 在系统发育学中的应用:在系统发育学中,树用来表示物种或群体之间的进化关系。两个分类
Rosalind 035 Creating a Distance Matrix
题目背景: 这个问题涉及到计算一组DNA字符串的p距离矩阵。p距离是衡量序列间进化距离的一种方法。以下是问题和过程的详细说明: 理解P距离:两个DNA字符串之间的p距离是指在相应位置上两个字符串不同的核苷酸比例。数学上来说,如果你有两个长度相同的字符串s1和s2,那么p距离dp(s1, s2)就是不同位置的数量除以字符串的总长度。 距离矩阵:距离矩阵D是一个方阵,其中每个元素Di,j代表数
Rosalind 034 Ordering Strings of Varying Length Lexicographically
题目背景: 这个题目要求生成并排序一个由给定字母表构成的字符串集合。首先,你会得到一个由最多12个符号组成的排列,这个排列定义了一个有序的字母表A。接着,给定一个正整数n(n不大于4),任务是生成所有可能的、长度最多为n的字符串,这些字符串由字母表A中的符号构成,并且需要按字典顺序排列。 例如,如果字母表是D、N、A,且n=2,那么你需要生成所有由这三个字母构成、长度不超过2的字符串,并将它们
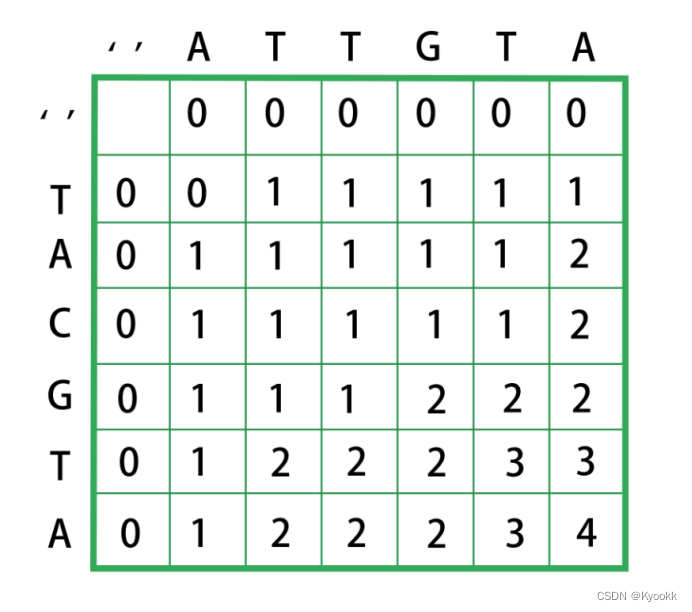
Rosalind 033 Finding a Shared Spliced Motif
题目背景: 上述问题的解决方法是使用动态规划来找出两个DNA字符串的最长公共子序列(LCS)。 https://rosalind.info/problems/lcsq/ 很经典的动态规划问题了。直接给出解题步骤: 1. 初始化矩阵:创建一个大小为 (len(s) + 1) x (len(t) + 1) 的矩阵。将第一行和第一列的元素初始化为零。这些代表了一个字符串与空字符串的LCS,其长度
生物信息学算法之Python实现|Rosalind刷题笔记:006 计算点突变数
汉明距离的定义:对于两条长度相等的字符串来说,汉明距离指的是它们之间不相同的字符数。对于两条 DNA,则是它们之间的点突变数目。 给定:两条长度相等的 DNA 序列(不超过 1kb)。 需得:计算汉明距离。 示例数据 GAGCCTACTAACGGGATCATCGTAATGACGGCCT 示例结果 7 Python 实现 Counting_Point_Mutations.py import