robots专题

<meta name=“robots“ content=““>介绍
是一个 HTML 元素,用于指示搜索引擎爬虫(如 Googlebot)如何处理网页的索引和抓取。它可以控制搜索引擎对页面的访问和索引行为。 content 属性可以包含以下指令: index:允许搜索引擎索引该页面(默认行为)。noindex:不允许搜索引擎索引该页面。follow:允许搜索引擎跟踪页面上的链接(默认行为)。nofollow:不允许搜索引擎跟踪页面上的链接。 例如: <m
seo robots.txt文件
robots.txt是一个纯文本文件,robots.txt是一个协议,而不是一个命令。robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。 robots.txt必须放在一个站点的根目录下,而且文件名必须全部小写。 robots.txt格式:<field>:<optionalspace><value><optiona
WordPress网站的Robots协议应该怎么写
相信许多博主和Joe一样用的是Wordpress建站程序,Wordpress确实是一个非常强大的博客建设程序,前些天在网上了解到了一些Robots知识,接下来与大家分享一下Wordpress的Robots协议到底该怎么写才好? 我们先来了解一下什么是robots协议,Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protoco

网站设置了robots.txt文件引起的不收录情况
网站设置了robots.txt文件引起的不收录情况 文章目录 前言一、各位网站管理员二、robots.txt介绍总结 前言 百度最近对于站长这块还是很重视的,不断的有声明或者是站长工具推出,看来,百度在将会对站长们更加的看重呀,毕竟想要留住用户就要有好的用户体验嘛。一个网站如果按照百度的标准去更新和建设网站的话,那搜索引擎的压力就会减少很多,推出更多的站长工具,不仅对于大多

robots.txt用法介绍,网站优化
robots.txt是一个纯文本文件,在这个文件中网站管理者可以声明该网站中不想被robots访问的部分,或者指定搜索引擎只收录指定的内容,注意这是一个针对搜索引擎的一个文件。 当一个搜索机器人(有的叫搜索蜘蛛)访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,那么搜索机器人就沿着链接抓
POJ 1548 Robots(最小路径覆盖)
POJ 1548 Robots 题目链接 题意:乍一看还以为是小白上那题dp,其实不是,就是求一共几个机器人可以覆盖所有路径 思路:最小路径覆盖问题,一个点如果在另一个点右下方,就建边,然后跑最小路径覆盖即可 代码: #include <cstdio>#include <cstring>#include <vector>#include <algorithm>us
10599 - Robots(II)
题目链接~~> 做题感悟:这题度题意就读了很久,很经典,主要是想到怎样转化。 解题思路: 如果第 i 个垃圾标号小于第 j 个垃圾,且i 列坐标不大于 j 的列坐标那么就可以由 i 到 j 形成一条路(机器人只向下 ,向右走),这样用dp 一边,跟求最长单调递增序列一样,同时记录到达每个点的方法数 ,还要注意如果在左下角没有垃圾要人为添加一个,到最后输出的
网站robots.txt文件
提要:每当用户试图访问某个不存在的URL时,服务器都会在日志中记录404错误(无法找到文件)。每当搜索蜘蛛来寻找并不存在的robots.txt文件时,服务器也将在日志中记录一条404错误,所以你应该在网站中添加一个robots.txt。 通常的robots.txt文件的使用只需要创建一个以robots为名的txt空白内容文件即可,这样搜索引擎就默认抓取全站。但如果您的网站内容有些隐私不希望被搜
Robots协议的一点知识
Robots协议,通常指的是robots.txt协议,是一种网站管理员用来告诉搜索引擎蜘蛛(也称为爬虫或机器人)哪些页面可以被抓取,哪些不可以的文本文件。这个协议也被称为排除标准(Robots Exclusion Protocol)。 robots.txt文件放置在网站的根目录下,搜索引擎在抓取一个网站之前,会首先查看这个文件的内容。文件中的指令告诉搜索引擎爬虫哪些目录或文件是可以访问的,哪些是
豆瓣的robots内容分析
豆瓣的robots内容如下: ======================================================== User-agent: * Disallow: /subject_search Disallow: /amazon_search Sitemap: http://www.douban.com/sitemap_index.xml Sitemap: http
网站中的 robots.txt 在爬虫中的指导作用
很多网站中都会设置robots.txt文件,用来规范、约束或者是禁止爬虫对于网站中数据的采集等操作。robots.txt文件用于禁止网络爬虫访问网站指定目录。robots.txt的格式采用面向行的语法:空行、注释行(以#打头)、规则行。规则行的格式为:Field: value。常见的规则行:User-Agent、Disallow、Allow行。 我们以豆瓣网为例,来看一下它的r
Leading Robots 单调栈+排序
链接:http://acm.hdu.edu.cn/showproblem.php?pid=6759. 来源:杭电多校第一场 题目描述 给n个机器人的初始位置p和加速度a,在无限长的跑道中,有多少机器人能成为领头羊。 分析 我们可以把所有机器人按照起始位置递减的顺序进行排序,然后建立一个栈。 我们尝试去扫描所有的机器人,如果他的加速度比上一个机器人大,那么他一定可以超过他成为领头羊,那么把它
robots.txt文件用法说明
robots.txt文件用法说明 例1. 禁止所有搜索引擎访问网站的任何部分 User-agent: * Disallow: / 例2. 允许所有的robot访问 (或者也可以建一个空文件 “/robots.txt”) User-agent: * Disallow: 或者 User-agent: * Allow: / 例3. 仅禁止baiduspider访问您的网站 Use
Robots文件信息泄露 原理以及修复方法
漏洞名称 :Robots文件信息泄露、Robots.txt泄露 漏洞描述: 搜索引擎可以通过robots文件可以获知哪些页面可以爬取,哪些页面不可以爬取。 Robots协议是网站国际互联网界通行的道德规范,其目的是保护网站数据和敏感信息、确保用户个人信息和隐私不被侵犯,如果robots.txt文件编辑的太过详细,反而会泄露网站的敏感目录或者文件,比如网站后台路径,从而得知其使用的系统类型,从而

robots协议详解:爬虫也要有边界感
随着互联网的迅猛发展,信息的获取变得越来越便捷,而网络爬虫(Spider)技术就是其中之一。网络爬虫是一种自动化程序,它能够遍历互联网上的网页,提取信息,用于各种用途,例如搜索引擎索引、数据挖掘、价格比较等。但是,爬虫技术虽然强大,但是也是一把双刃剑,在正当使用时,可以进行快速的获取资源,当非正当使用时,可能造成无法承担的后果。 认识爬虫及法律后果: 网络爬虫的基本原理是通过HTTP请求下
![[ABC216H]Random Robots](https://img-blog.csdnimg.cn/624ba4d2fb7548bbb748f9bcc2055fcf.png)
[ABC216H]Random Robots
Random Robots 题解 首先看到 k ⩽ 10 k\leqslant 10 k⩽10的数据范围限制,应该很容易联想到状压。 同时题目有时要求路径无交,很容易想到通过容斥来转移。 我们定义 d p S dp_{S} dpS为对于集合为 S S S的点的合法方法数,考虑怎么对其进行转移。 我们如何处理两点的路径是否有交,可以直接根据两点的终点进行判断。 我们可以从左到右枚举点作为终点,
网络机器人(Robots)
网络机器人(Robots): 是福还是祸? Martijn Koster, NEXOR April 1995 [1997: Updated links and addresses] Codehunter[程式猎人]翻译 摘要 机器人在万维网上使用已经有一年多了(相对于1995年)。在这段时间中,它们担当着有用的任务,同时也对网络造成了很大的破坏。本文着重研究机器人在资源收寻方面的优势以

【python】遵守 robots.txt 规则的数据爬虫程序
程序1 编写一个遵守 robots.txt 规则的数据爬虫程序涉及到多个步骤,包括请求网页、解析 robots.txt 文件、扫描网页内容、存储数据以及处理异常。由于编程语言众多,且每种语言编写爬虫程序的方式可能有所不同,以下将使用 Python 语言举例,提供一个简化的流程。 注意:以下代码只是一个示例,并不是一个完备的、可直接运行的程序。此外,实际应用中还需要处理网络错误、限速遵循礼貌
ROBOTS协议对SEO优化有什么影响?
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。Robots协议的本质是网站和搜索引擎爬虫的沟通方式,用来指导搜索引擎更好地抓取网站内容,更好的保护用户的隐私和版权信息。 Robots协议可能给我们网站带来的好处: 1、 可以制止不必要
如何使用robots.txt及其详解(与蜘蛛的协议)
如何使用robots.txt及其详解 在国内,网站管理者似乎对robots.txt并没有引起多大重视,应一些朋友之请求,今天想通过这篇文章来简单谈一下robots.txt的写作。 robots.txt基本介绍 Robots协议的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),它的功能是通过Robots文件告诉搜索引擎哪些页面可以抓取,哪些页面不

robots.txt 文件规则
robots.txt 是一种用于网站根目录的文本文件,其主要目的在于指示网络爬虫(web crawlers)和其他网页机器人(bots)哪些页面可以抓取,以及哪些页面不应该被抓取。可以看作是网站和搜索引擎机器人之间的一个协议。 robots.txt 文件支持一系列规则,主要包括“User-agent”, “Disallow”, “Allow”和“Sitemap”。以下是这些规则的基础用法:
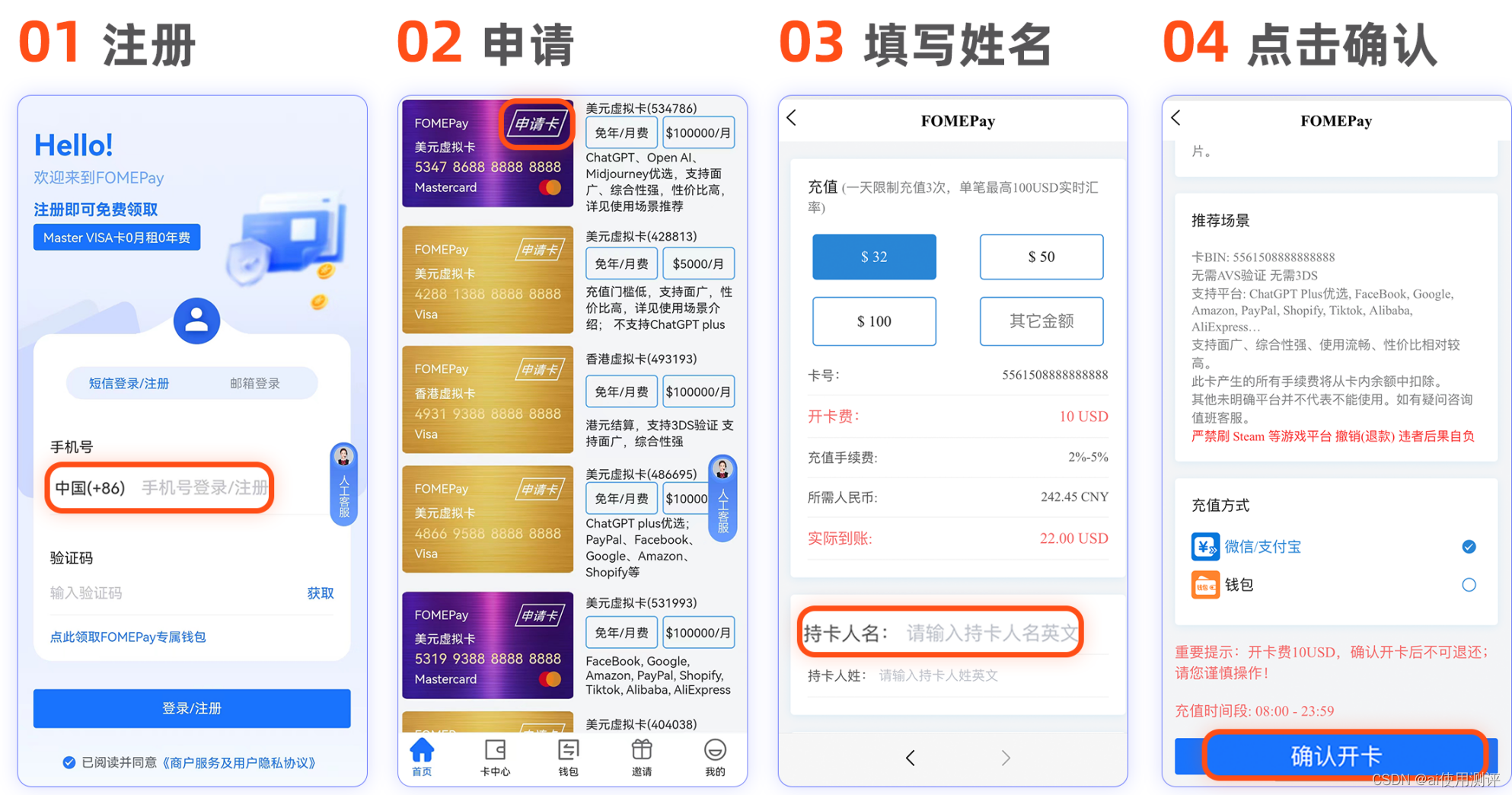
War Robots可以使用5347的卡支付
很多小伙伴想使用War Robots,但是不知道怎么弄,方法比较可靠,亲测有效~~~ 可以使用Fomepay的5347的卡支付 卡片cvc就是卡密,在首页点击更多时可以查看

网站管理新利器:免费在线生成 robots.txt 文件!
🤖 探索网站管理新利器:免费在线生成 robots.txt 文件! 你是否曾为搜索引擎爬虫而烦恼?现在,我们推出全新的在线 robots.txt 文件生成工具,让你轻松管理网站爬虫访问权限,提升网站的可搜索性和可发现性! 什么是 robots.txt 文件生成工具? robots.txt 文件生成工具是为网站管理员和 SEO 优化人员设计的在线工具。它能够帮助你快速生成 robots.tx
robots.txt和Robots META标签
我们知道,搜索引擎都有自己的“搜索机器人”(ROBOTS),并通过这些ROBOTS在网络上沿着网页上的链接(一般是http和src链接)不断抓取资料建立自己的数据库。 对于网站管理者和内容提供者来说,有时候会有一些站点内容,不希望被ROBOTS抓取而公开。为了解决这个问题,ROBOTS开发界提供了两个办法:一个是robots.txt,另一个是The Robots META标签。 一、 ro