raft专题

利用Go语言模拟实现Raft协议
近来学习到区块链,想要模拟实现 Raft 协议。但是发现网上教程很杂,或者说很多教程并不适合于新手从零开始进行实现。 本文将从头开始复现个人模拟实现 Raft 的过程,完成后整个模拟后,读者应该学会 Go 语言的基本语法、Rpc 编程的基本概念与用法、简易 Raft 协议的过程。 系统实现:本地 Raft 节点注册,Raft 节点的投票和选举,心跳监听,超时选举,Http监听,日志复

hashicorp/raft 介绍与源代码分析(三): 集群节点恢复介绍
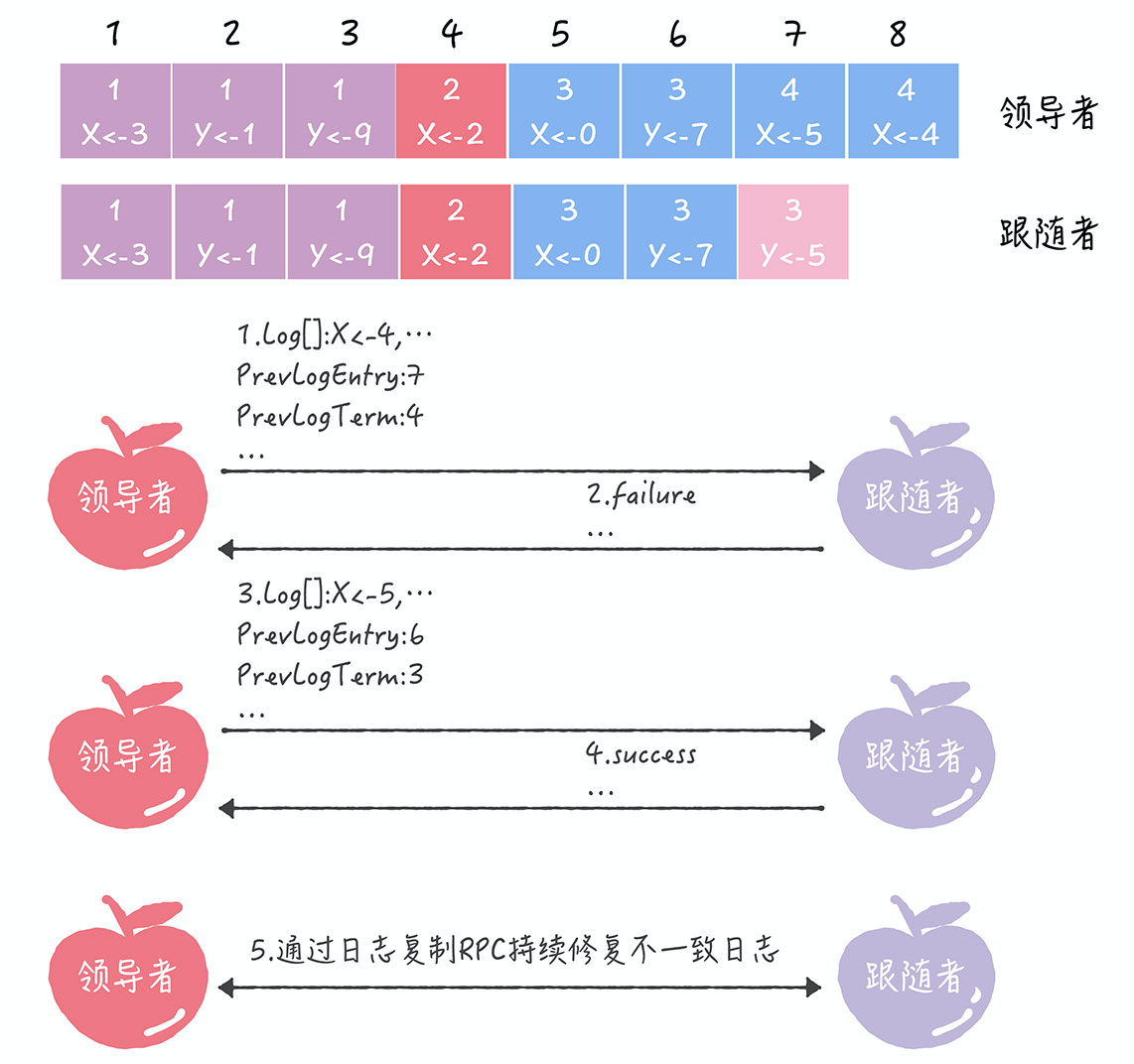
集群节点恢复 各种情况下,重新选主成功后,落后的 follower 需要赶上 leader 的状态: follower 已经落地的 log ,需要校对。与 leader 不一致的,直接丢弃follower 从头,或从最近的本地镜像中恢复,并追赶应用 log 到状态机 我们分析几种异常情况下,集群是如何自动恢复正常的: 1 个 follower 重启了,该 follower 如何最终使自己

hashicorp/raft 介绍与源代码分析(二): 领导人选举(二)
回顾 上章提到,基于节点的 keyCurrentTerm 、LastLogTerm 、 LastLogIndex 3 个持久化数据,在选举时,可以确定领导者 选择领导者的依据是哪个节点 log 最全,选谁 但是有附加条件的,该节点 log 最全,并且其他节点已经应用到状态机的 log ,该节点必须有 因此,不是所有情况下选举一定能成功的 最坏的情况下,找不到符合条件的 log 落地日志拥

Paxos、Raft不是一致性算法/协议?
点击上方“朱小厮的博客”,选择“设为星标” 后台回复”加群“获取公众号专属群聊入口 欢迎跳转到本文的原文链接:https://honeypps.com/architect/consistency-is-not-consensus/ 作为互联网中的一员,我们时常沉浸在“分布式”的氛围当中——高可用、高可靠、高性能等等词汇随处可见,CAP、BASE、2PC、Paxos、Raft等等名词也能信手捏来

RAFT实现之leader election
RAFT实现之leader election 测试全部通过 leader选举基本流程 所有节点以follower启动 follower的选举时钟超时,转为candidate candidate向其他节点发送投票请求,如果收到过半节点的投票,则成为leader leader周期性向其他节点发送心跳包以维持权威 实现关键点: 1.状态转移: raft节点的状态转移要严格依据下图,不管节点处于什么状态
RAFT:Adapting Language Model to Domain Specific RAG
论文链接 简单来说,就是你SFT微调的时候得考虑RAG的场景。 RAG什么场景?你检索top-k回来,里面有相关doc有不相关doc,后者是影响性能的重要原因,LLM需要有强大的识别能力才能分得清哪块和你的query相关。微调就是为了这个。你做领域微调时,根据chunk生成query、answer,然后直接拿这仨微调,这里面没有干扰项,没有“不相关doc”,就扛不住RAG的噪声。 RAFT就是针
![[etcd]raft总结/选举/数据同步,协议缺陷与解决/Multi Raft](https://i-blog.csdnimg.cn/blog_migrate/d647e80325d7ae7cffcb4081a74b6e75.jpeg)
[etcd]raft总结/选举/数据同步,协议缺陷与解决/Multi Raft
raft协议是multi paxos协议的实现.Etcd、Consu都使用了raft 1.角色 raft协议中包含这几种角色 领导者:带头大哥1.提出提议,但是不需要确认,因为我是大哥;2.复制日志,数据以大哥为准,3,领导者会定时发送心跳,确定自己的位置.告诉小弟老实呆着,一旦心跳超时,小弟就会重新选举大哥. 跟随者:只要大哥发送心跳,我就老实的同步日志.一旦没有心跳,我就变成候选人,开

Raft分区产生的脏读问题
Raft分区产生的脏读问题 前言网络分区情况1 4和5分到一个分区,即当前leader依然在多数分区情况2 1和2分到一个分区,即当前leader在少数分区 脏读问题的解决官方解答其他论文 参考链接 前言 昨天面试阿里云被问到了这个问题,在此记录一下。 网络分区 有一个raft集群如下所示,然后发生网络分区: 情况1 4和5分到一个分区,即当前leader依然在多数分区
分布式共识算法(故障容错算法)系列整理(四):Raft
五篇分布式共识系列文章合集: 分布式共识算法(拜占庭容错算法)的系列整理一:PBFT、PoW、PoS、DPos 分布式共识算法(故障容错算法)系列整理(二):Bully、Gossip、NWR 分布式共识算法(故障容错算法)系列整理(三):Paxos 分布式共识算法(故障容错算法)系列整理(四):Raft 分布式共识算法(故障容错算法)系列整理(五):ZAB Raft算法的成员身份(服务器节点状态
分布式一致性和CAP理论、Paxos算法、Raft算法、Zab协议
1.分布式一致性的重要性 在分布式系统中,一致性是一个至关重要的概念。分布式系统由多个节点组成,这些节点通过网络进行通信和协作。然而,由于网络延迟、节点故障等原因,分布式系统中的数据一致性往往面临着挑战。 一致性指的是在分布式系统中的所有节点上,对于某一数据的操作结果都是一致的。换句话说,所有节点应该具备相同的数据视图。如果一个节点对数据进行了修改,其他节点也应该能够感知到这个修改,并且在
分布式协议之巅 — 揭秘基础Paxos与Raft协议如何实现分布式系统达成一致性(非变种Paxos协议)
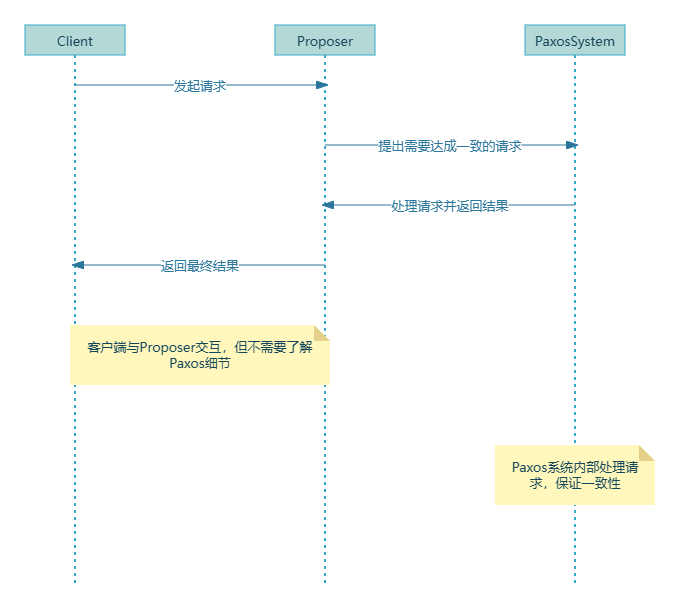
揭秘Paxos与Raft协议如何实现分布式系统达成一致性 前提介绍Paxos专题大纲Paxos协议Paxo协议的角色标准Paxos角色Proposer(提案者)Acceptor(接受者)Learner(学习者) 提案编号与确认值的组合解析Paxos协议的基石:Basis Paxos执行流程解析阶段一Prepare阶段Promise阶段 阶段二Accept阶段Accepted阶段 最后总

【基于Raft的k-v存储数据库实现】
基于Raft的k-v存储数据库实现 基本概念1. 什么是分布式系统2. 什么是Raft协议3. 什么是序列化和反序列化4. RPC相关5. c11的部分新特性6. 什么是共识,一致性算法7. 共识算法要满足的性质8. Raft中的一些重要概念8.1 Raft是如何保证一个Term只有一个Leader的?8.2 过程 原文链接 基本概念 1. 什么是分布式系统 建立在网络之

算法学习之:Raft-分布式一致性/共识算法
基础介绍 Raft是什么? Raft is a consensus algorithm that is designed to be easy to understand. It's equivalent to Paxos in fault-tolerance and performance. The difference is that it's decomposed into relat
Raft论文阅读笔记+翻译:In Search of Understandable Consensus Algorithm
In Search of Understandable Consensus Algorithm 摘要 Raft是一种管理复制日志的共识算法。它产生与(多)Paxos等效的结果,并且与Paxos一样高效,但其结构与Paxos不同。这使得Raft比Paxos更易理解,也为构建实际系统提供了更好的基础。为了增强可理解性,**Raft将共识的关键元素(如领导选举,日志复制和安全性)分离,并强制执
CP模型--Raft协议介绍
文章目录 前言一、Raft 是什么:二、Raft的工作原理:2.1 Raft 节点的3中状态:2.2 集群启动 leader 节点的选举:在这里插入图片描述2.3 数据的同步(日志复制):2.4 leader 重新选举:2.5 网络分区故障:2.6 超时时间控制: 总结:参考: 前言 本文对分布式系统下,强一致性模型(cp)之Raft 算法的实现进行介绍。 一、Ra

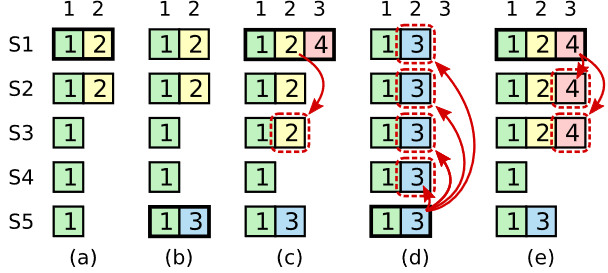
raft算法-顺带处理前任的事-看似随心却是精心
今天在跑raft算法的时候,突然发现一个有意思的细节:如何处理前任未提交的日志。 我们都知道raft选举的时候会综合考虑任期(term)和日志索引(index),优先选择具备最新的数据的节点成为master,这个其实非常容易理解,这是为了最大化保持数据。 但这里面有个小细节就是,如下图所示,S3在任期7的时候提交了一个日志,但它还没来得及复制就挂了。 之后master切换到其他节点。如果此时其

RAFT:引领 Llama 在 RAG 中发展
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/ 引言 经过广泛训练的预训练模型(如 Meta Llama 2)可以对各
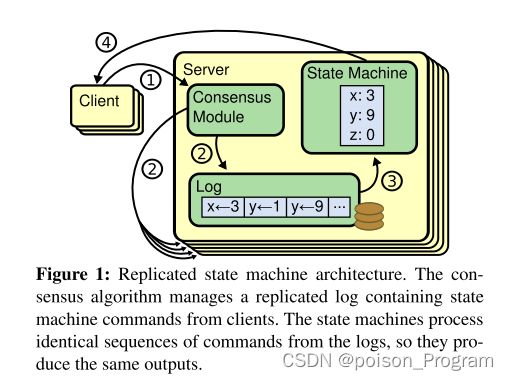
Raft共识算法笔记,MIT6.824,
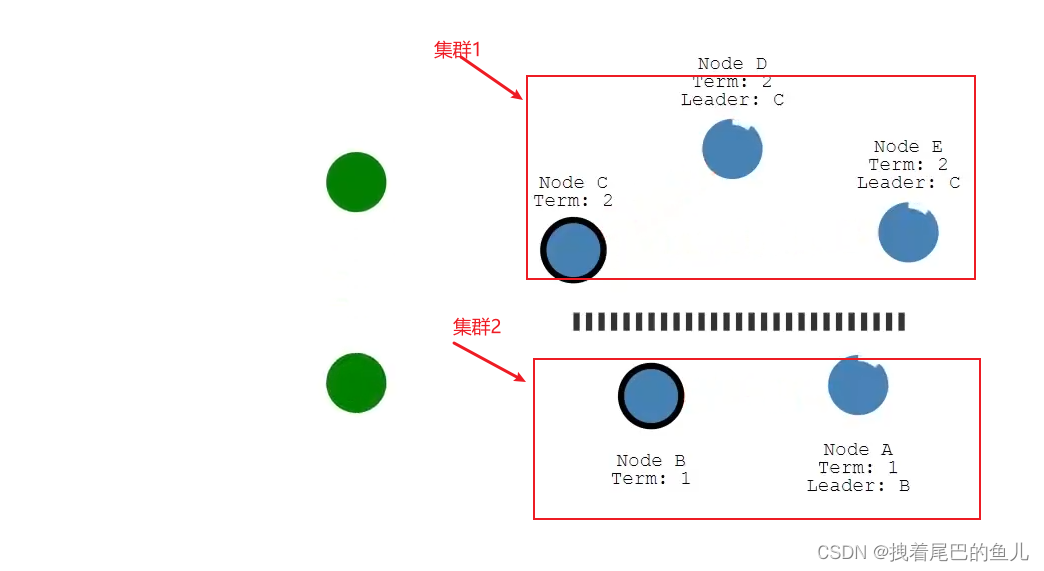
处理leader和follow的一个重要思路是多数投票,确保系统中存在奇数个服务器(例如3台)。进行任何操作都需要来自多数服务器的同意,例如3台服务器中的2台。如果没有多数同意,系统会等待。为什么多数投票有助于避免脑裂问题呢? 至多一个candidate能够占据多数,这打破了只有两台服务器的情况下所见到的对称性。 注意:多数是基于所有服务器,而不仅仅是活跃的服务器。注意:在获得多数后继续进行,不
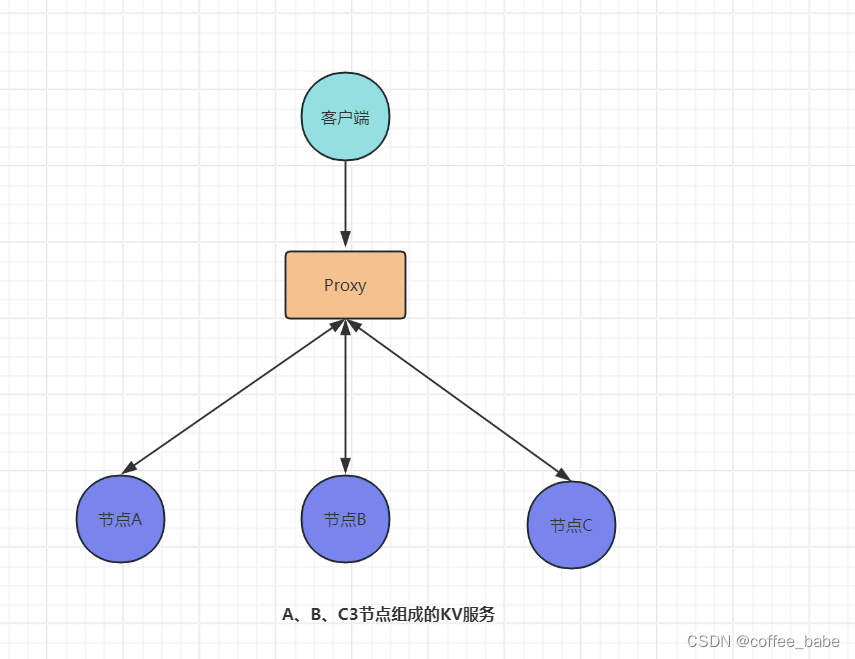
分布式与一致性协议之Raft算法与一致哈希算法(一)
Raft算法 Raft与一致性 有很多人把Raft算法当成一致性算法,其实它不是一致性算法而是共识算法,是一个Multi-Paxos算法,实现的是如何就一系列值达成共识。并且,Raft算法能容忍少数节点的故障。虽然Raft算法能实现强一致性,也就是线性一致性(Linearizability),但需要客户端协议的配合。在实际场景中,我们一般需要根据场景特点,在一致性强度和实现复杂度之间进行权衡。
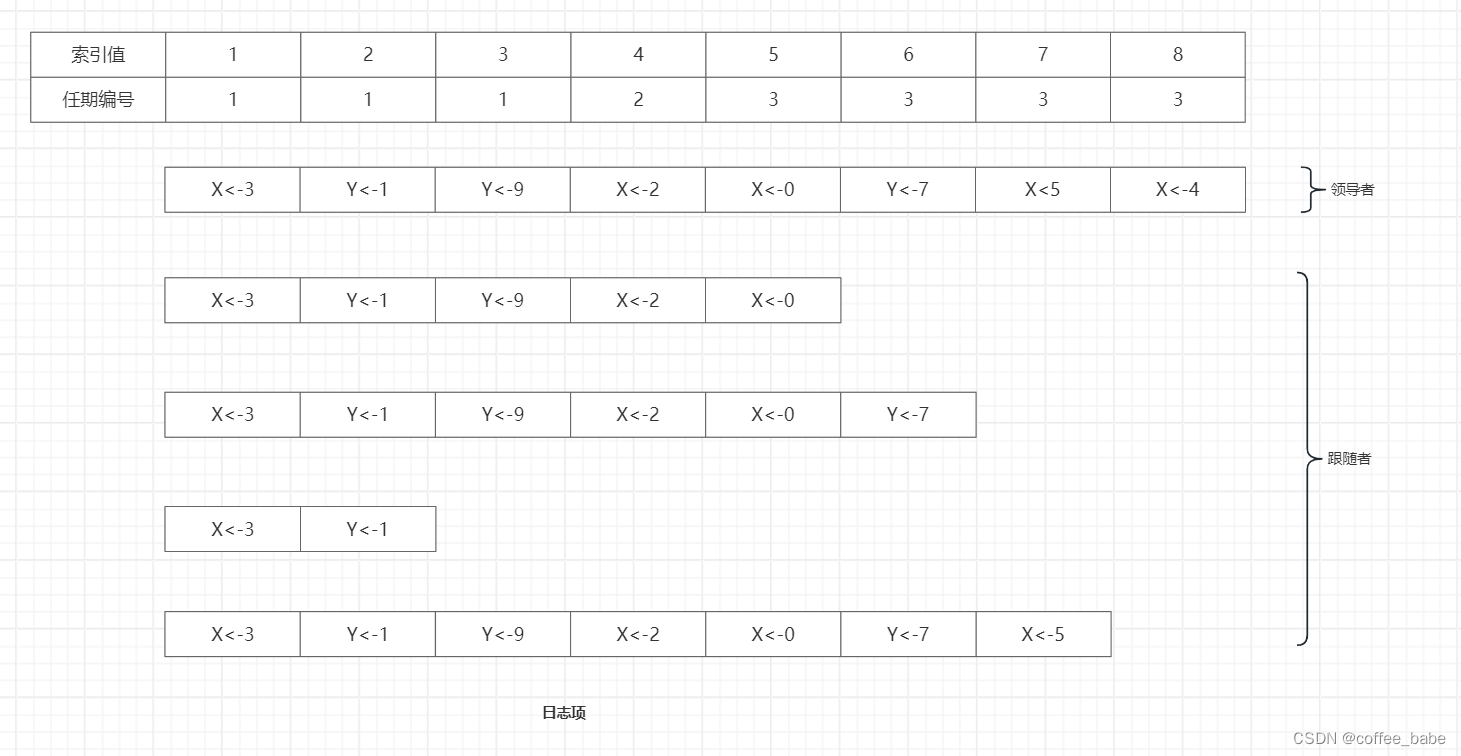
分布式与一致性协议之Raft算法(二)
Raft算法 什么是任期 我们知道,议会选举中的领导者是有任期的,当领导者任命到期后,需要重新再次选举。Raft算法中的领导者也是有任期,每个任期由单调递增的数字(任期编号)标识。比如,节点A的任期编号是1。任期编号会随着选举的举行而变化,分析如下。 1.跟随者在领导者心跳信息超时并推荐自己为候选人时,会增加自己的任期编号,比如节点A的当前任期编号为0,那么在推荐自己为候选人时,它会将自己的
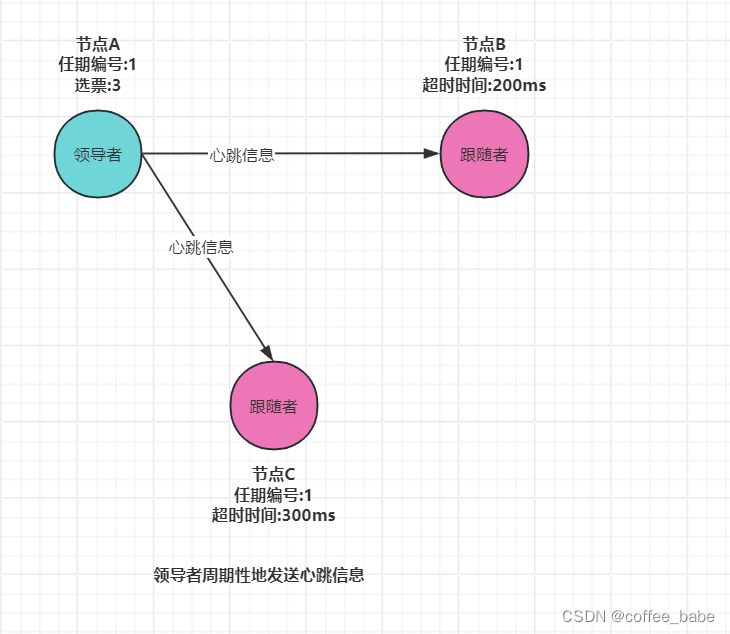
分布式与一致性协议之Raft算法(一)
Raft算法 概述 Raft算法属于Multi-Paxos算法,它在兰伯特Multi-Paxos思想的基础上做了一些简化和限制,比如日志必须是连续的,只支持领导者(Leader)、跟随者(Follwer)和候选人(Candidate)3种状态。在理解和算法实现上,Raft算法相对容易许多。 除此之外,Raft算法是现在分布式系统首选的共识算法。绝大多数选用Paxos算法的系统(比如Chubby
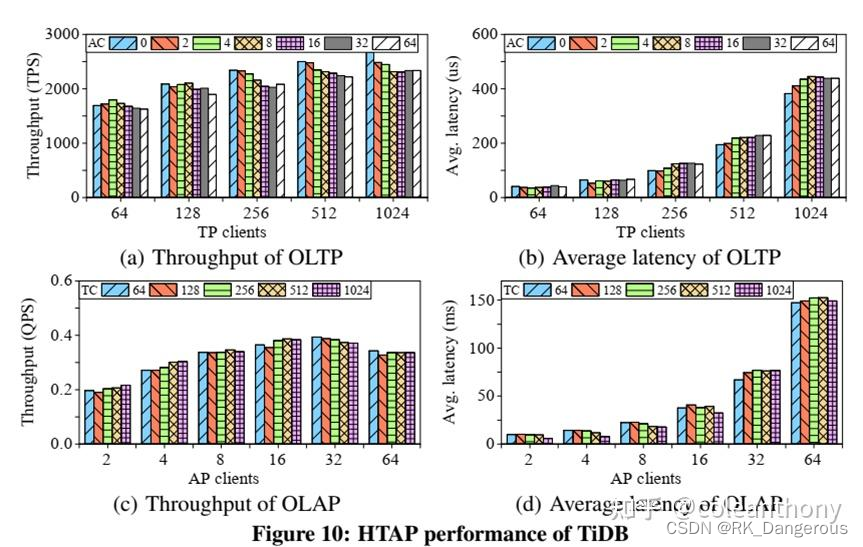
【大数据】TiDB: A Raft-based HTAP Database
文章目录 数据库知识介绍数据库系统的ACID特性分布式系统和CAP理论关系型数据库与非关系型数据库关系型数据库非关系型数据库 OldSQL、NoSQL、NewSQLOldSQLNoSQLNewSQL OLTP、OLAP、HTAP 前言:为什么选择TiDB学习?pingCAP介绍TiDB介绍TiDB的影响力TiDB概括创作背景 论文阅读:TiDB: A Raft-based HTAP Dat
初识共识算法POW、POS、DPOS、PBFT、RAFT
浏览区块链工程师招聘要求,都会由这么一条: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c2wOONBW-1570761152120)(D:\Wangdb\Typora\Typora图片\共识算法.png)] 共识机制(Consensus) 由于加密货币多数采用去中心化的区块链设计,节点是各处分散且平行的,所以必须设计一套制度,来维护系统的运作顺序与公平