本文主要是介绍Raft共识算法笔记,MIT6.824,,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
-
处理leader和follow的一个重要思路是多数投票,确保系统中存在奇数个服务器(例如3台)。进行任何操作都需要来自多数服务器的同意,例如3台服务器中的2台。如果没有多数同意,系统会等待。为什么多数投票有助于避免脑裂问题呢?
- 至多一个candidate能够占据多数,这打破了只有两台服务器的情况下所见到的对称性。
- 注意:多数是基于所有服务器,而不仅仅是活跃的服务器。
- 注意:在获得多数后继续进行,不要等待更多,因为它们可能已经失效。
- 更一般地说,2f+1可以容忍f个失败的服务器,因为剩余的f+1是2f+1的多数。如果失败的服务器超过f个(或者无法联系),则无法取得进展。
- 至多一个candidate能够占据多数,这打破了只有两台服务器的情况下所见到的对称性。
-
多数投票的一个关键特性是,任意两个交集中的服务器都可以传达关于先前决策的信息,例如,另一个 Raft 领导者已经在这个任期内被选举出来。
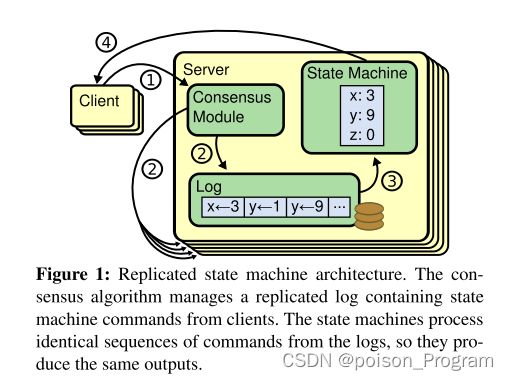
-
一个客户端命令的时间图如下:
- 命令序列:
[C, L, F1, F2]- C:client发送Put/Get "command"到leader的键值层(key/value layer)。
- L:leader的Raft层将命令添加到日志(log)。
- F1和F2:leader向follower发送AppendEntries RPCs(追加日志条目的远程过程调用)。
- 处理过程:
- leader等待来自多数(包括自身)follower的回复。
- 如果大多数follower将该命令添加到它们的日志中,则该命令被“提交”。
- 提交意味着即使发生故障,该命令也不会被遗忘。
- 大多数意味着下一位领导者的投票请求将看到这个提交的命令。
- leader执行命令并回复给客户端。
- 信息传递:
- 领导者在下一次的AppendEntries中“携带”提交信息。
- 在领导者说它已经提交时,follower执行相应的日志条目。
这个过程描述了在Raft协议中一个客户端命令的处理流程,包括命令的传递、提交和执行。这确保了在分布式系统中对于客户端命令的一致性和可靠性。
- 命令序列:
-
为什么需要日志呢?
- 状态机状态: 服务保持状态机的状态,例如键值数据库。
- 日志是相同信息的备用表示!为什么需要两者?
- 命令排序: 日志对命令进行排序。
- 有助于副本就单一执行顺序达成一致。
- 有助于领导者确保追随者的日志完全相同。
- 存储临时命令: 日志存储临时命令,直到它们被提交。
- 提交的意味着它们不会被遗忘,即使发生故障。
- 存储命令备份: 日志存储命令,以防领导者必须重新发送给追随者。
- 持久存储: 日志持久存储命令,以便在重启后进行重放。
简而言之,日志在分布式系统中的作用是有序地记录命令,确保一致性,防止丢失,并帮助系统在发生故障或重启后保持一致状态。这同时也是为了确保状态机状态的持久性和一致性。
- 状态机状态: 服务保持状态机的状态,例如键值数据库。
-
Raft对等体何时开始领导者选举:
- 当它没有从当前领导者收到消息,会等待一个"选举超时"。
- 它会增加本地的currentTerm(当前任期),并尝试收集选票。
- 注意:这可能导致不必要的选举;虽然速度较慢,但是是安全的。
- 注意:旧的领导者可能仍然存活并认为它是领导者。
- 由于其提高了任期,所以会开启一轮新的选举,这种情况虽然可能导致不必要的选举,但由于 Raft 协议的设计,最终只有一个对等体会成功地成为新的领导者,确保了一致性和可靠性。
-
为了确保一个任期内最多只有一个领导者,Raft采取了以下措施(参考图2中的RequestVote RPC和服务器规则):
- 领导者必须获取多数服务器的"yes"投票: 为了成为领导者,一位候选者必须获得来自多数服务器的"yes"投票。
- 每个服务器每个任期只能投一票:
- 如果是候选者,它会为自己投票。
- 如果不是候选者,它会为第一个请求它的候选者投票(在图2的规则内)。
- 同一任期内最多只有一个服务器可以获得多数投票:
- 这确保了在一个任期内最多只有一个领导者,即使发生网络分区。
- 即使一些服务器发生故障,选举也可以成功。
- 注意:多数是基于所有服务器的(而不仅仅是活跃的服务器): 这是为了防止网络分区导致的问题,确保在整个系统中只有一个领导者。
-
服务器如何知道新选举产生的领导者呢?
- 领导者发送AppendEntries心跳: 新选举产生的领导者会发送包含新的更高任期号的AppendEntries心跳。
- 只有领导者发送AppendEntries: 在Raft中,只有领导者才会发送AppendEntries消息,因为每个任期内只有一个领导者。因此,如果你看到带有任期号T的AppendEntries消息,你就知道T任期的领导者是谁。
- 心跳抑制新选举: 心跳消息可以抑制新的选举。领导者必须比选举超时更频繁地发送心跳消息,以确保其他服务器认识到领导者的存在并防止新的选举发生。
-
选举可能不会成功的两个原因:
- 大多数服务器不可达
- 同时存在多个候选者,分散了投票,没有获得多数
-
如果选举不成功会发生什么呢?
- 如果选举不成功,系统将没有收到心跳,然后在另一个超时后会启动新的选举以形成新的任期。较高的任期号具有优先权,因此具有较高任期号的候选者有望获得支持,而为较旧任期的候选者将退出竞选。
-
Raft是如何避免分散投票的呢?
- 每个服务器在其选举超时期间添加一些随机性。
- 随机性在服务器之间打破对称性,其中一个服务器将选择最低的随机延迟。
- 希望有足够的时间在下一个超时到期之前选出领导者。
- 其他服务器将看到新领导者的AppendEntries心跳,因此不会成为候选者。
- 随机延迟是网络协议中常见的模式
-
如何选择选举超时时间呢?
- 至少需要几个心跳周期的时间(以防网络丢失心跳): 避免不必要的选举,以免浪费时间。
- 随机部分足够长,以便在下一个开始之前让一个候选者成功: 这确保了不同服务器的选举不会在同一时间触发,防止了分散投票。
- 足够短以快速响应故障,避免长时间的停顿
- 足够短以允许在测试者感到不满之前进行几次重试: 在5秒钟或更短的时间内完成选举是测试者的要求。
-
如果旧领导者不知道新领导者已经当选会发生什么呢?
- 可能旧领导者没有看到选举消息。
- 可能旧领导者处于网络的少数分区中。
- 新领导者意味着大多数服务器已经增加了当前任期。
- 旧领导者将在AppendEntries回复中看到新任期并下台。
- 或者旧领导者将无法获得大多数的回复,因此旧领导者将不会提交或执行任何新的日志条目。
- 这样就避免了分裂脑问题。
- 但是,少数服务器可能会接受旧服务器的AppendEntries,因此在旧任期的末尾,日志可能会发生分歧。
-
如果是不确定性指令在raft中会产生不确定性结果
-
raft没有流量限制,当leader处理了上亿请求,但是follower只复制了几千命令,可能会出现follower内存溢出,需要加更多的操作限制,例如捎带发送
-
Raft的主要用途?
- Raft(以及Paxos)最常见的用途之一是构建容错的“配置服务”;这个配置的任务是跟踪当前在大规模部署中服务器的责任分配情况。Raft 在配置服务中的应用,通过维护服务器责任的有序分配,提供了一种可靠的机制,尤其在具有复制的大规模系统中;基于Raft的配置服务通常用于以避免分裂脑的方式选择主节点。VMware FT的test and set是配置服务的一个简单示例。Chubby、ZooKeeper和etcd是基于Raft或Paxos的更强大的容错配置服务;它们被广泛使用。
- 一些数据库,如Spanner、CockroachDB和Lab 3,使用Raft或Paxos来复制数据。相比之下,GFS、VMware FT和Chain Replication使用更简单的主备份方式来处理数据。一些数据库以两种不同的方式使用Raft或Paxos:一种是用于配置服务,分配服务器的责任(对于每个分片,当前主节点和备份是谁),另一种是独立处理每个分片内的数据。
-
Raft是否为简单性而牺牲了一些东西?
-
Raft在追求清晰度的同时放弃了一些性能,例如:
- 每个操作都必须写入磁盘以确保持久性;性能可能需要将许多操作批处理到每个磁盘写入中。
- 从领导者到每个追随者只能有一个有效的AppendEntries在传输中:追随者拒绝无序的AppendEntries,而发送方的nextIndex[]机制要求一次只能有一个(一次只能向一个追随者发送一条信息,不然nextIndex会冲突)。支持多个AppendEntries的流水线处理机制可能更好。
- 快照设计对于相对较小的状态才是实用的,因为它将整个状态写入磁盘。如果状态很大(例如,如果它是一个大型数据库),则希望有一种方法仅写入最近更改的状态部分。
- 类似地,通过向其发送完整快照将正在恢复的副本更新到最新状态将很慢,如果副本已经有一个略微过时的快照,则是不必要的。
- 由于操作必须按顺序(按日志顺序)执行,服务器可能无法充分利用多核。
这些问题可以通过修改Raft来解决,但结果可能不再具有作为教程的价值。
-
-
Raft和VMware FT有什么关系?
-
Raft没有单一故障点,而VMware FT在测试和设置服务器的形式上有一个单一故障点。从这个意义上说,Raft在基本上比VMware FT更具容错性。可以通过使用Raft或Paxos将FT的测试和设置服务器实现为一个复制的服务来解决这个问题。
VMware FT可以复制任何虚拟机客户机,因此可以复制任何类似服务器的软件,甚至是不知道正在被复制的软件。Raft被用作集成到应用软件中的库,这通常是专门设计为与复制良好配合的软件。
-
-
如果选举超时时间太短会怎么样?会导致Raft发生故障吗?
- 选举超时时间选择不当不会影响安全性,只会影响活性。
- 如果选举超时时间太短,那么跟随者可能会在领导者有机会发送任何AppendEntries之前反复超时。在这种情况下,Raft可能会花费所有时间选举新的领导者,而没有时间处理客户端请求。如果选举超时时间太长,那么在领导者故障后,在选举新领导者之前会有一个不必要的长暂停期。
-
除非发生崩溃,领导者是否会停止成为领导者?
- 是的。如果领导者的CPU速度较慢,或其网络连接断开,或者丢失太多数据包,或者传递数据包的速度太慢,其他服务器将无法看到其AppendEntries RPC,并将启动选举。
-
追随者的日志条目何时发送到其状态机?
- 只有在领导者使用AppendEntries RPC的leaderCommit字段宣布一个条目已经被提交后。此时,追随者可以执行(或应用)日志条目,对我们来说,就是将其发送到applyCh。
-
领导者是否应该等待AppendEntries RPC的回复?
-
领导者应该并发地发送AppendEntries RPC,而无需等待。随着回复的返回,领导者应该计数它们,并仅当它从大多数服务器(包括自己)收到回复时将日志条目标记为已提交。
-
在Go中实现这一点的一种方法是,领导者在每个迭代中都在一个单独的goroutine中发送AppendEntries RPC,以便领导者可以并发地发送RPC。类似这样的代码:
-
for each server {go func() {send the AppendEntries RPC and wait for the replyif reply.success == true {increment countif count == nservers/2 + 1 {this entry is committed}}} () }
-
-
如果一半或更多的服务器宕机会发生什么?
- 服务将无法取得任何进展;它将一遍又一遍地尝试选举领导者。当足够多的服务器带着持久的Raft状态重新上线时,它们将能够选举出一个领导者并继续进行。
-
Raft通过让跟随者采用新领导者的日志来强制达成一致
举例说明:
10 11 12 13 <- 日志条目号 S1: 3 S2: 3 3 4 S3: 3 3 5- S3被选为新的领导者,任期为6。
- S3希望在索引13处追加一个新的日志条目。
- S3向所有服务器发送一个AppendEntries RPC:
prevLogIndex=12prevLogTerm=5
- S2回复false(AppendEntries步骤2)。
- S3将
nextIndex[S2]减少到12。 - S3发送AppendEntries,携带条目12和13,
prevLogIndex=11,prevLogTerm=3。 - S2删除其条目12(AppendEntries步骤3),并附加新的条目12和13。
- 对于S1的情况类似,但S3必须再退一步。
回滚的结果是:
-
每个活动的追随者删除与领导者不同的日志尾部。
- 活动的追随者将其日志尾部与领导者的不同之处删除。
-
然后,每个活动的追随者接受领导者在此点之后的条目。
- 每个活动的追随者接受领导者在此点之后的所有日志条目。
现在,每个追随者的日志与领导者的日志相同。这确保了整个系统的一致性,所有追随者都达到了与领导者相同的状态。这个过程是为了纠正由于领导者和追随者日志不同步引起的问题,以确保日志的一致性。
-
重点:
- “至少与最新状态一致”规则确保了新领导人的日志至少包含:
- 所有可能已提交的条目
- 因此新任领导人不会回滚任何已提交的操作
- “至少与最新状态一致”规则确保了新领导人的日志至少包含:
-
在服务器崩溃后,我们希望发生什么呢?
Raft 可以在缺失一个服务器的情况下继续运行,但是必须尽快修复失败的服务器,以避免降到少数派以下。有两种修复策略:
-
用新的(空)服务器替换: 这需要将整个日志(或快照)传输到新服务器上(速度较慢)。我们必须支持这种情况,以防故障是永久性的。
-
或者重新启动崩溃的服务器,保持状态完整,然后赶上: 这需要状态在崩溃间保持。我们必须支持这种情况,尤其是在同时发生电源故障的情况下。
-
-
如果服务器崩溃并重新启动,Raft必须记住什么呢?
-
在图2中列出了"持久状态",包括log[]、currentTerm和votedFor。只有这些状态保持完整,Raft服务器才能在重新启动后重新加入。因此,必须将它们保存到非易失性存储中。
-
非易失性存储可以是硬盘、固态硬盘(SSD)、带有电池支持的RAM等。必须在更改非易失性状态的代码中的每个关键点之后,或在发送任何RPC或RPC回复之前保存这些状态。
-
为什么需要保存log[]呢?
- 如果一个服务器在领导者的多数派中提交一个条目,必须记住该条目,以防重新启动。这样下一位领导者的投票多数包括该条目,因此选举限制确保新的领导者也有该条目。
-
为什么需要保存votedFor呢?
- 为了防止客户端为一个候选人投票,然后重新启动,然后在同一个任期为不同的候选人投票。这可能导致同一个任期内出现两个领导者。
-
为什么需要保存currentTerm呢?
- 为了避免跟随一个被淘汰的领导者,以及避免在一个被淘汰的选举中投票。
-
-
解决日志条目过长;服务定期创建持久性的"快照"。
【图示:服务状态,磁盘上的快照,Raft日志(在内存中,磁盘上)】
-
快照是服务状态在执行特定日志条目时的副本,例如键/值表。服务将快照连同最后包含的日志索引一起交给Raft。
-
Raft将其状态和快照持久保存。然后,Raft会丢弃快照索引之前的日志。每个服务器都创建快照,而不仅仅是领导者。
-
-
在崩溃和重启时会发生什么?
- 服务从磁盘读取快照。
- Raft从磁盘读取持久化的日志。
- Raft将
lastApplied设置为快照的最后包含的索引,以避免重新应用已经应用过的日志条目。
问题是,如果跟随者的日志在领导者的日志开始之前结束会怎样?
问题是,如果跟随者有日志缺失部分,这部分日志领导者已经转化为了快照,怎么办?
- 因为跟随者处于离线状态,领导者丢弃了日志的早期部分。
nextIndex[i]将会备份到领导者的日志的头部更前边的位置。- 因此,领导者无法通过 AppendEntries RPC 修复该跟随者,因此引入了
InstallSnapshot RPC,将快照传给跟随者。
-
linearizability是一种常见的强一致性版本,类似于对单个服务器期望的行为。它可以在分布式系统中实现(付出一些代价)
- 线性一致性的定义是:
- 如果可以找到所有操作的总顺序,
- 这个总顺序在实时上是匹配的(对于非重叠的操作),并且
- 在这个总顺序中,每次读取都看到它前面的写入的值。
- 线性一致性的定义是:
这篇关于Raft共识算法笔记,MIT6.824,的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







