pig专题

深入探索【Hadoop】生态系统:Hive、Pig、HBase及更多关键组件(下)
🐇明明跟你说过:个人主页 🏅个人专栏:《大数据前沿:技术与应用并进》🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是Hadoop 2、Hadoop生态系统的构成概览 二、HBase:分布式NoSQL数据库 1、什么是HBase 2、HBase架构解析:Region、RegionServer、Zookeeper的角色 3、HBase API与操作方式 4、

hadoop入门--使用Apache Pig统计每个航班班次
案例基于hadoop 2.73,伪分布式集群 1,数据包导入hadoop集群hdfs的/user/root目录下 hdfs dfs -copyFromLocal 2008.csv /user/root 2,编写totalmiles.pig脚本 records = LOAD '2008.csv' USING PigStorage(',') AS(Year,Month,DayofMont
Pig安装配置及基本使用
前提安装好jdk, hadoop集群。 下载并解压pig安装包 下载地址:http://pig.apache.org/ 解压pig安装包:tar -zxvf pig.tar.gz

pig的各种运行模式与运行方式详解
pig的各种运行模式与运行方式详解 .一、pig的运行模式: Pig 有两种运行模式: Local 模式和 MapReduce 模式。当 Pig 在 Local 模式运行的时候, Pig 将只访问本地一台主机;当 Pig 在 MapReduce 模式运行的时候, Pig 将访问一个 Hadoop 集群和 HDFS 的安装位置。这时, Pig 将自动地对这个集群进行分配和回收。因为 Pig

pig使用参考示例一
pig使用参考示例 下面是我在做高端客户分析系统时的部分pig实现代码,该段代码的主要功能是实现对清洗后的数据进行处理并输出加权计算后后的最终结果。虽然代码写的不是很好,但也希望晒出来和大家分享一下。 注:如果想查看pig的详细使用说明,请参考“pig学习教程”:http://blog.csdn.net/zhu_xun/article/details/168191

pig中各种sql语句的实现
pig中各种sql语句的实现 Pig是一个基于Hadoop的大规模数据分析平台,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。使用pig可以在处理海量数据时达到事半功倍的效果,比使用Java,C++等语言编写大规模数据处理程序的难度要小N倍,实现同样的效果的代码量也小N倍。我们可以在不
Pig加载配置的四种方式
Pig加载配置的四种方式 由于要在开发机器上源码调试Pig,同时也要在单机上通过PIG_HOME/bin/下的pig脚本去执行Pig,以及在内网集群,生产环境上运行Pig,所以不同的配置环境会导致一些问题,比如Lzo压缩.有时明显你机器上安装了lzo,你CLASS_PATH中也加载hadoop这些配置,但还是不行.所以花了点时间,看了下Pig这方面的源码,终于搞明白.这里分享下.
oozie中运行pig action-node时的错误提示参数参考
oozie中运行pig action-node时返回的错误参数参考 我在使用oozie运行pig时,经常会遇到如下异常:Main class [org.apache.oozie.action.hadoop.PigMain], exit code [6],后来查找了一些文档,知道了这是使用UDF函数时出的问题,今天把常见的错误返回值贴出来供大家参考。 Pig返回值及其意义

Pig 在 shell script中被调用,批量加载处理文件
首先,我想达到的目的是批量的处理一个文件夹下的的许多文档,这些文档保存了我要处理的数据,因为pig是初学,,所以不知到该怎么批量的load,没有写过 自己的UDF,只能一个一个文件的load,然后处理。 但是这个肯定不是我希望的处理方式,于是联想到是不是可以将pig脚本插入到shell中然后循环执行。 最后尝试成功了,当然我相信pig的udf中可以自己定义这种load的方式,但是如果出于快速
Hadoop Pig学习笔记:各种SQL在PIG中实现
本博客属原创文章,转载请注明出处:http://guoyunsky.iteye.com/blog/1317084 欢迎加入Hadoop超级群: 180941958 我这里以Mysql 5.1.x为例,Pig的版本是0.8 同时我将数据放在了两个文件,存放在/tmp/data_file_1和/tmp/data_file_2中.文件内容如下:
connection-error-in-apache-pig
出现这种错误: 2013-07-29 13:24:08,591 [main] INFO org.apache.hadoop.mapred.ClientServiceDelegate - Application state is completed. FinalApplicationStatus=SUCCEEDED. Redirecting to job history server 0

Apache Pig和Solr问题笔记(一)
记录下最近两天散仙在工作中遇到的有关Pig0.12.0和Solr4.10.2一些问题,总共有3个,如下: (1)问题一: 如何Pig中使用ASCII和十六进制(hexadecimal)的分隔符进行加载,和切分数据? 注意关于这个问题,在Pig中,会反应到2个场景中, 第一: 在Pig加载(load)数据时候 。 第二: 在Pig处理split,或则正则截取数据的时候。 先稍微说下,
Gitee最有价值开源项目:Pig RABC权限管理系统的技术解析与实践
一、引言 随着企业业务的不断扩张和复杂化,权限管理系统的设计和实现变得越来越重要。Pig RABC权限管理系统是基于Spring Boot 3.2、 Spring Cloud 2023 & Alibaba、 SAS OAuth2的微服务RBAC权限管理系统,旨在提供高效、安全的权限管理解决方案。本文将对Pig RABC权限管理系统的技术解析与实践进行深入探讨。 二、技术解析 基
BZOJ4216 Pig 解题报告【卡空间】【数据结构】【分块】
Description 红学姐和黄学长是好朋友。 有一天,黄学长想吃猪肉丸,于是他去找红学姐买猪。红学姐到她的猪圈中赶猪的时候发现有许多猪逃离了她的猪圈。同时红学姐发现,一个名叫wwf的魔法猪藏在某 个猪圈中施法。然而wwf实在太巨了,红学姐并没有办法捉住它,只好向方老师求救。 为了确定wwf的位置,方老师向红学姐提出了m组询问,每次询问标号在区间[l,r]内的猪圈剩余的猪的数量和,但红学

![[pig框架源码分析] 01 - 权限管理系统](https://img-blog.csdnimg.cn/431701168bf74cd198d26de6e11d6b46.png)
[pig框架源码分析] 01 - 权限管理系统
文章目录 pig白皮书介绍数据库关系接口统计部门用户角色菜单 登录登录请求用户信息导航菜单 参考资料 pig白皮书介绍 权限管理实现 基于角色的访问控制方法(Role-Based Access Control,简称 RBAC)是目前公认的解决大型企业的统一资源访问控制的有效方法。其显著的两大特征是: 减小授权管理的复杂性,降低管理开销;灵活地支持企业的安全策略,并对企业的变
pig微服务权限管理系统部署总结
开发环境准备 基于 Spring Cloud Hoxton 、Spring Boot 2.3、 OAuth2 的 RBAC 权限管理系统基于数据驱动视图的理念封装 element-ui,即使没有 vue 的使用经验也能快速上手提供对常见容器化支持 Docker、Kubernetes、Rancher2 支持提供 lambda 、stream api 、webflux 的生产实践 特别说明
pig-ui使用记录(貌似是全网第一篇?)-基于Spring Cloud 2021、Spring Boot 2.6、OAuth2 的 RBAC权限管理系统前端
前言 1.我在使用时遇到的问题 看了 pig官方文档(个人感觉有点不够详细)感觉还是一脸懵逼,网上搜索相关的文章也基本没搜到怎么使用的,还是得自己研究,。。。。自己写一篇笔记记录一下基本使用 2.pig,pig-ui 相关介绍 pig-ui源码 pig-ui gitee地址pig-ui 介绍 基于 Spring Cloud 2021 、Spring Boot 2.6、 OAuth2 的 R

Pig系统分析(1)-概述
本系列文章分析Pig运行主线流程,目的是借鉴Pig Latin on Hadoop,探索(类)Pig Latin on Spark的可能性。 Pig概述 Apache Pig是Yahoo!为了让研究人员和工程师能够更简单处理、分析和挖掘大数据而发明的。从数据访问的角度来看,可以把YARN当成大数据的操作系统,那么Pig是各种不同类型的数据应用中不可或缺的一员。 尽管Pig的学习成本

Hadoop之家族成员Pig简介
Hadoop发展很快,Hadoop作为Apache的一个顶级项目旗下有许多的子项目,今天的内容就是简单的介绍一下Hadoop家族的子项目中的Pig。 下图是一个Hadoop子项目的大体结构图 Pig简介 Pig是Hadoop数据操作的客户端是一个数据分析引擎,采用了一定的语法操作HDFS中的数据(Pig应该说是一种语言,有人说Pig是类SQL的语言我这里只能说它的功能类似Sql语言和数据
PIG 代码生成器独立模块部署 欢迎来喷
Pig 代码生成器代码部署 创建表 执行脚本 CREATE TABLE `sys_tenancy` ( `id` varchar(32) NOT NULL COMMENT '主键ID', `tenancy_name` varchar(64) NOT NULL COMMENT '租户名称',

pig的安装及简单的操作
解压 配置PIG_HONE vim ~/.bash_profile 验证 出现如下信息则成功 pig [-]help 启动 Pig 有两种运行模式:Local 模式和 MapReduce 模式。Local 模式只能访问本地 系统文件,一般用于处理小规模的数据集,不需要 Hadoop 集群环境的支持。 MapReduce 模式运行于 Hadoop 集群环境上,
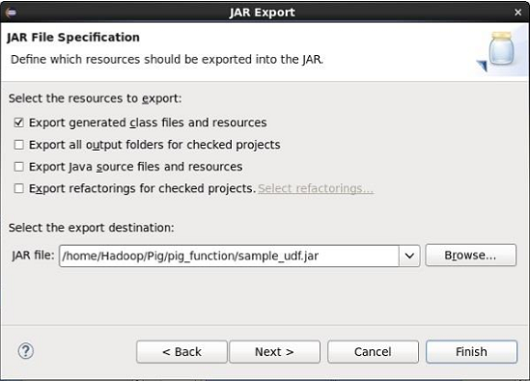
java udf for pig_pig 教程及 自定义udf 的java版-Go语言中文社区
Apache Pig 用户定义函数(UDF) 除了内置函数之外,Apache Pig还为User Defined Function(UDF:用户定义函数)提供广泛的支持。使用这些UDF,可以定义我们自己的函数并使用它们。UDF支持六种编程语言,即Java,Jython,Python,JavaScript,Ruby和Groovy。 对于编写UDF,在Java中提供全面的支持,并在所有其他语言中提供