nets专题

from nets.mobilenet import mobilenetv2 ModuleNotFoundError: No module named 'nets' conda安装slim
之前提供过一种解决方案。但是需要在代码中增加路径,并不是很通用。 第二种解决方案: https://github.com/tensorflow/models/tree/master/research/slim 下载这个包,解压后,找到setup.py所在目录:(如果你用conda,启用你的环境) python setup.py buildpython setup.py install

【论文阅读】Semantic Segmentation with deep convolutional nets and fully connected CRFs
一、摘要 深度卷积神经网络(DCNN)最近在高级视觉任务中展示了最先进的性能,例如图像分类和对象检测。这项工作汇集了来自DCNN和概率图形模型的方法,用于解决像素级分类(也称为“语义图像分割”)的任务。我们表明DCNN最后一层的响应没有充分定位,无法进行精确的对象分割。这是由于非常不变的属性使DCNN有利于高级任务。 我们通过将最终DCNN层的响应与完全连接的条件随机场(CRF

【论文阅读】semantic image segmentation with deep convolutional nets and fully connected CRFs
文章的主要贡献: 速度:带atrous算法的DCNN可以保持8FPS的速度,全连接CRF平均推断需要0.5s;准确:在PASCAL语义分割挑战中获得了第二的成绩;简单:DeepLab是由两个非常成熟的模块(DCNN和CRFs)级联而成。 一、概述 自LeCun(1998)以来,DCNN一直被选作版面识别的方法,如今已经成为高级视觉研究的主流,提高了计算机视觉性能,广泛应用于图像分割,对
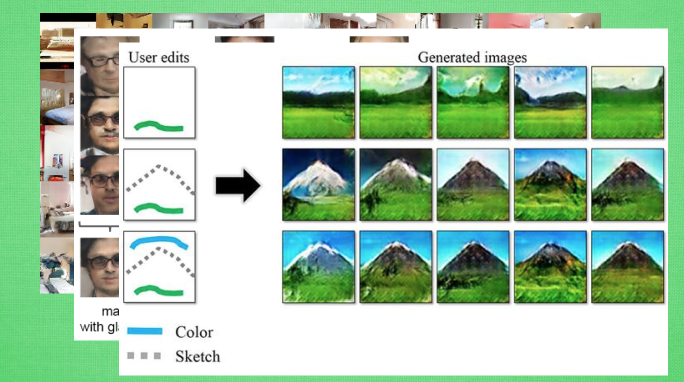
生成对抗网络(GAN Generative Adversarial Nets )简介
常见神经网络形式 神经网络分很多种, 有普通的前向传播神经网络 , 有分析图片的 CNN 卷积神经网络 , 有分析序列化数据, 比如语音的 RNN 循环神经网络 , 这些神经网络都是用来输入数据, 得到想要的结果, 我们看中的是这些神经网络能很好的将数据与结果通过某种关系联系起来. 生成网络 但是还有另外一种形式的神经网络, 他不是用来把数据对应上结果的, 而是用来”凭空”捏造结
![[转载] Conv Nets: A Modular Perspective](http://colah.github.io/posts/2014-07-Conv-Nets-Modular/img/Conv2-5x5-Conv2-XY.png)
[转载] Conv Nets: A Modular Perspective
原文地址:http://colah.github.io/posts/2014-07-Conv-Nets-Modular/ Conv Nets: A Modular Perspective Posted on July 8, 2014 neural networks, deep learning, convolutional neural networks, modular neural ne

学习笔记:生成对抗网络(Generative Adversarial Nets)(附代码)
同时训练两个模型:(1)生成模型G,不断捕捉训练库里真是图片的概率分布,将输入的随机噪声转变成新的样本(即假数据),使其像是一个真的图片。(2)判别模型D,用来估计一个样本来自训练数据的概率,即它可以同时观察真是和假造的数据,并判断这个数据的真假(这个数据是不是从数据集中获取的图片)。在训练的过程中让两个网络互相竞争。刚开始的时候这两个模型均未经过训练,然后生成模型产生一张假数据欺骗判别模型,判别

【论文阅读】An Introduction to Image Synthesis with Generative Adversarial Nets --- 文本to图像,图像to图像生成,图像合成
论文原文链接: 本博客根据博主对本论文的阅读和理解所写,重点关注个人理解方便,非逐句翻译,望周知。如需深入了解论文详情,请阅读原文。 作者:He Huang, Philip S. Yu (University of Illinois at Chicago) and Changhu Wang (ByteDance AI Lab); 发表位置:Arxiv 2018; 摘要:GAN在许多领域展现
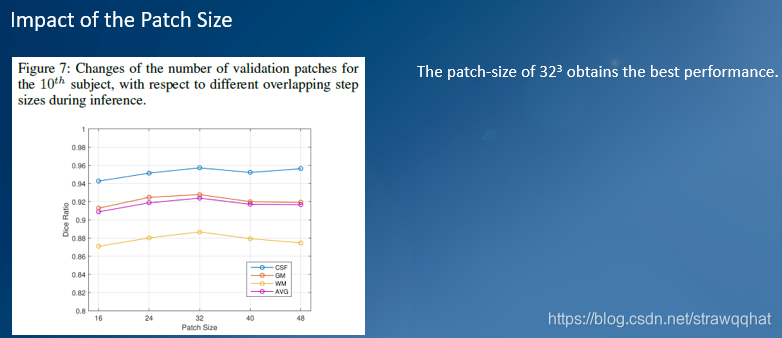
Day3_13 non-local U-Nets
背景 深度学习在各种生物医学图像分割任务重显示出巨大的应用前景。现有的模型一般基于U-Net,它依赖重复叠加的局部算子来聚合远程信息。这样做会限制模型的训练效率和最终效果。这篇文章提出了非局部的U-Nets网络架构,提出了全局聚合块的应用,它能够融合来自任何大小的特征映射的全局信息。通过在三维多模等强度婴儿脑磁共振图像分割任务上进行试验证明这个模型参数少,计算速度快,并且具有更好的分割效果。
PaperWeekly 第二十期 --- GAN(Generative Adversarial Nets)研究进展
Model 1、Unsupervised learning 首先我们从generative model说起。generative model的目的是找到一个函数可以最大的近似数据的真实分布。如果我们用 f(X; ?) 来表示这样一个函数,那么找到一个使生成的数据最像真实数据的 ? 就是一个maximum likelihood estimation的过程。问题在于,当数据的分布比较复杂时,我们
Large-scale Learning with SVM and Convolutional Nets(经典文献阅读)
一.文献名字和作者 Large-scale Learning with SVM and Convolutional Nets for Generic Object Categorization 二.阅读时间 2014年10月23日 三.文献的贡献点 将能够学习到不变性特征的CNN和能够学习到较好分界面的SVM进行融合
![XILINX VIVADO 找不着ILA或者是[Common 17-162] Invalid option value specified for ‘-nets‘. 的解决办法](https://img-blog.csdnimg.cn/20200814195254424.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1NoYXdnZQ==,size_16,color_FFFFFF,t_70)
XILINX VIVADO 找不着ILA或者是[Common 17-162] Invalid option value specified for ‘-nets‘. 的解决办法
vivado经常时不时出现找不着ILA或者是报下在这种错误, 出现这种问题的原因是ILA更新了,但是约束没有自动更新,导致找不着dbg_hub的时钟,而这种时钟名是软件生成的,每次都不一样,可以在XDC文件中注释或删除掉dbg_hub的相约束。 然后implement下打开IO,再然后取消一个IO的锁定并重新勾上之后按CTRL+S保存,这时会生成新的约束,如下图,然后重新编译工程吧
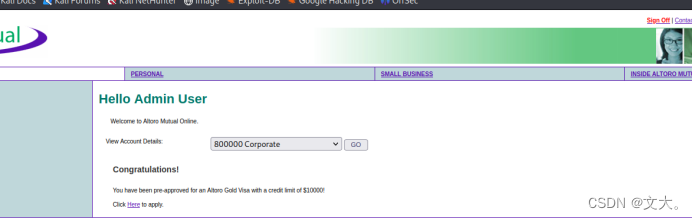
www.testfire.nets渗透测试报告
www.testfire.nets渗透测试报告 一、测试综述 1.1.测试⽬的 通过实施针对性的渗透测试,发现testfire.net⽹站的安全漏洞,锻炼自己的渗透水平 1.2.测试范围 域名:www.testfire.net IP:65.61.137.117 测试时间: 2023年11月21日 说明: 本次使用的渗透过程中使用的ip:192.168.85.128 1.3.数

Generative Adverarial Nets 原文阅读笔记
Generative Adverarial Nets 写在前面 G是用来逼近真实数据的分布的,但是G没有显式的给出分布,而是学习了一种映射,从噪声数据到目的数据的映射。 有一种说法是D其实是损失函数的一部分,GAN的优势就在于自动学习损失函数。可以这么理解,对于G生成的数据,我们没有人工的给出标签,而是通过D去给标签,判断好不好,或者说通过D给出G的损失,从而更新G。 总之,G给出了一个从
Generative Adversarial Nets论文阅读笔记
先附上本人使用pytorch实现的GAN: https://github.com/1991yuyang/GAN 如果觉得有用大家可以给个star。 这篇博客用于记录Generative Adversarial Nets这篇论文的阅读与理解。对于这篇论文,第一感觉就是数学推导很多,于是下载了一些其他有关GAN的论文,发现GAN系列的论文的一大特点就是基本都是数学推导,因此,第一眼看上去还是比较
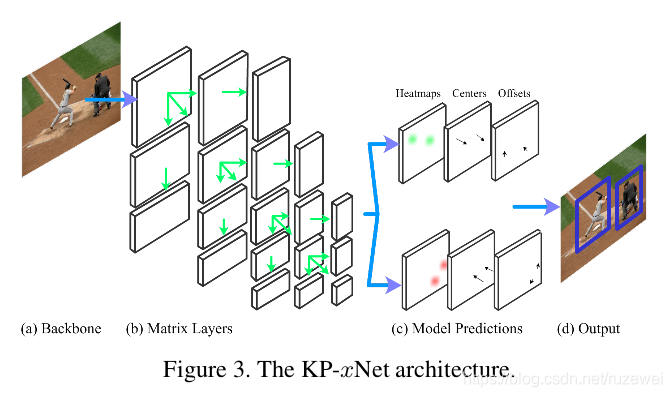
Matrix Nets 笔记
Matrix Nets (xNets) 是一种用于提高目标检测性能指标的网络架构,该架构可以用于一步、二步以及多步目标检测神经网络。论文作者将该架构用于一阶段目标检测网络,在 MS COCO 数据集上获得了 47.8 的 mAP,并且在 80 个 Epoch 的时候就收敛了。 xNets 主要缓解了以下两个问题: 使用正方形的 Kernel 来提取不同宽高比目标

具体问题具体分析“ModuleNotFoundError: No module named 'nets'”
具体问题具体分析“ModuleNotFoundError: No module named ‘nets’” 问题出现场景: 在第一次使用tensorflow的slim模块时,没有引入合适的系统变量,导致spyder找不到nets的模块,需要自己添加系统的环境变量 解决方法: 利用sys模块添加引用库路径 代码如下: import sysnets_path = r'slim
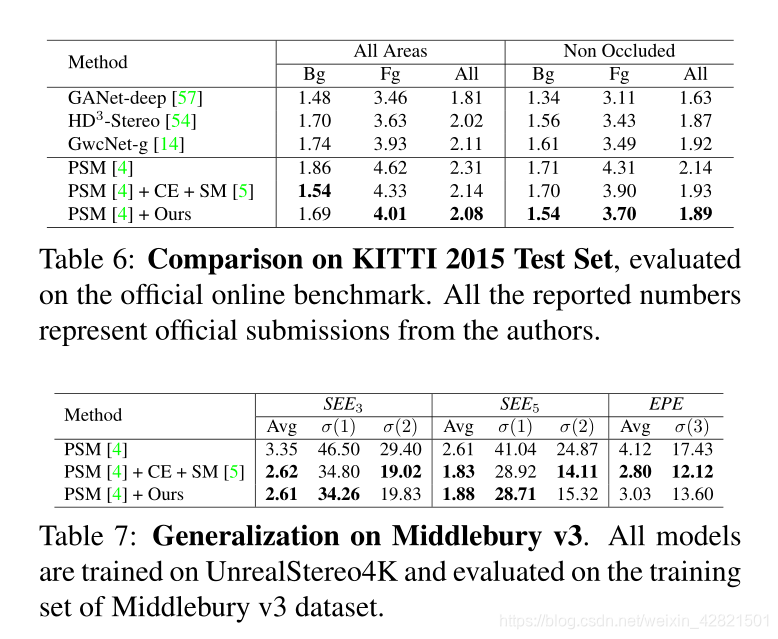
SMD-Nets: Stereo Mixture Density Networks
paper | project Abstract 尽管在过去的几年中,深度学习大大提高了立体匹配的精度,但有效地恢复尖锐边界和高分辨率输出仍然具有挑战性。在本文中,我们提出了立体混合密度网络(Stereo Mixture Density Networks, SMD-Nets),这是一种简单而有效的学习框架,可与广泛的2D和3D体系结构兼容,改善了这两个问题。 具体来说,我们利用双峰混合密度作