本文主要是介绍Generative Adverarial Nets 原文阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Generative Adverarial Nets
写在前面
G是用来逼近真实数据的分布的,但是G没有显式的给出分布,而是学习了一种映射,从噪声数据到目的数据的映射。
有一种说法是D其实是损失函数的一部分,GAN的优势就在于自动学习损失函数。可以这么理解,对于G生成的数据,我们没有人工的给出标签,而是通过D去给标签,判断好不好,或者说通过D给出G的损失,从而更新G。
总之,G给出了一个从噪声分布到g分布的映射,g分布是要来逼近data分布(真实分布);D指导G的训练,判断G生成数据假得够不够;G也指导D训练,生成更假的数据给D去判断,增强D。
Abstract
提出了一种通过一个对抗网络来评估生成网络的框架,在这个框架中同时训练两个模型
- 生成模型 G ——抓取数据分布
- 识别模型 D ——评估一个输入是真实数据还是G生成的数据
在训练中G的目的是最大化D犯错的概率。
类比于一个minmax游戏,零和博弈。
在理想的条件下,存在唯一解,对应于G恢复原始的数据分布,D恒等于1/2
如果G D用多层感知机来实现,整个框架可以用反向传播来实现。
Adversarial nets
p g p_g pg : 生成模型的分布
x x x : 真实/生成数据
p z ( z ) p_z(z) pz(z) : 噪声变量,服从分布 P z P_z Pz
G ( z ; θ g ) G(z; \theta _ g) G(z;θg) : 模型G,z作为输入, θ g \theta _g θg 是参数,输出x
D ( x ; θ d ) D(x; \theta _d) D(x;θd) : 模型D, x作为输入, θ d \theta _ d θd 是参数,输出x是真实数据的概率
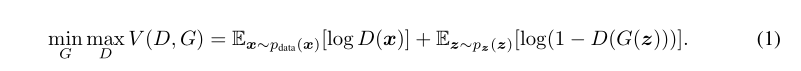
这是一个不规范的公式,但是有意义
min max指明了G和D训练的目的
E应该是example的意思,E的下标表面服从分布,
第一项是D判断真实数据为真实的概率加log
第二项是1减判断生成数据为真实的概率加log
D的目的是最大化这两个,也就是尽量判断正确
而G的目的是最小化这两个,也就是尽量让D判断错误,也就是尽量让自己的分布逼近真实的分布
优化
内层循环优化D,外层循环优化G
但是不能在内层循环中把D最优化,因为一个有限集合会造成过拟合
所有内层循环优化D k次,就跳出,对G优化一次
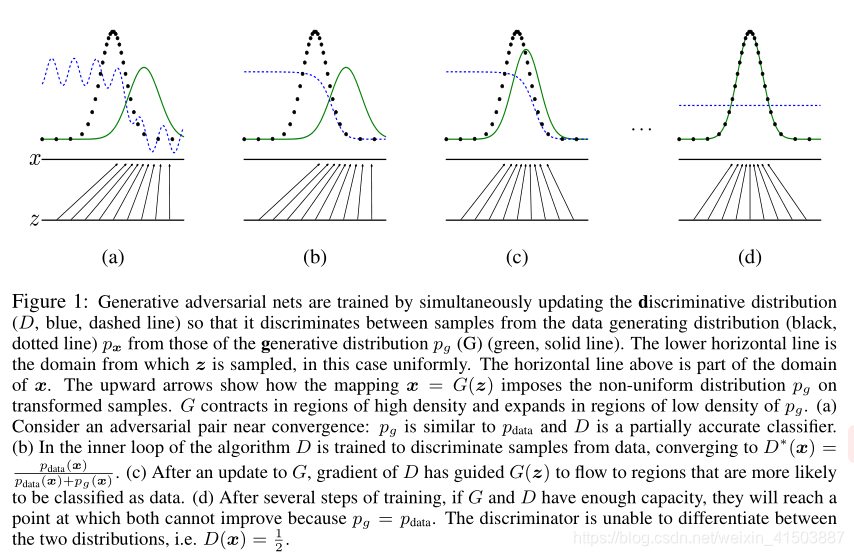
第一张图:一个接近收敛的状态,
第二张图:训练完D,在左边高,对于G拟合的好,右边低,G拟合的不好
第三张图:训练网络G,G更接近真实数据了
第四张图:非常好,G的分布和真实数据一样了,D彻底模糊,处处为1/2
Theoretical Results
没看懂。。。
最后贴算法图

可以看到,训练D,用到了两种数据——真实数据,和噪声(通过G去生成虚假数据)
训练G只用一种数据,就是噪声数据,因为真实数据不是G的输入,对模型的梯度是没有贡献的
可以看到,训练D,用到了两种数据——真实数据,和噪声(通过G去生成虚假数据)
训练G只用一种数据,就是噪声数据,因为真实数据不是G的输入,对模型的梯度是没有贡献的
注意:在反向传播的时候,内层循环只更新D的权重,外层循环只更新G的权重
这篇关于Generative Adverarial Nets 原文阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









