mqa专题

YOLOv9改进策略【注意力机制篇】| 引入MobileNetv4中的Mobile MQA,提高模型效率
一、本文介绍 本文记录的是基于Mobile MQA模块的YOLOv9目标检测改进方法研究。MobileNetv4中的Mobile MQA模块是用于模型加速,减少内存访问的模块,相比其他全局的自注意力,其不仅加强了模型对全局信息的关注,同时也显著提高了模型效率。 文章目录 一、本文介绍二、Mobile MQA注意力原理三、Mobile MQA的实现代码四、添加步骤4.1 修改common.
MHD、MQA、GQA注意力机制详解
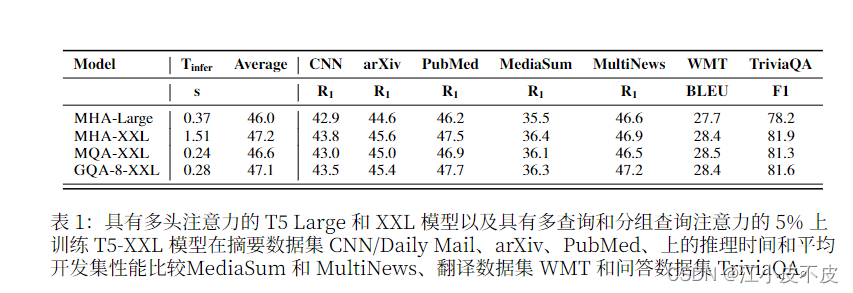
MHD、MQA、GQA注意力机制详解 注意力机制详解及代码前言:MHAMQAGQA 注意力机制详解及代码 前言: 自回归解码器推理是 Transformer 模型的 一个严重瓶颈,因为在每个解码步骤中加 载解码器权重以及所有注意键和值会产生 内存带宽开销 下图为三种注意力机制的结构图和实验结果 MHA 多头注意力机制是Transformer模型中的核心组
【NLP】MHA、MQA、GQA机制的区别
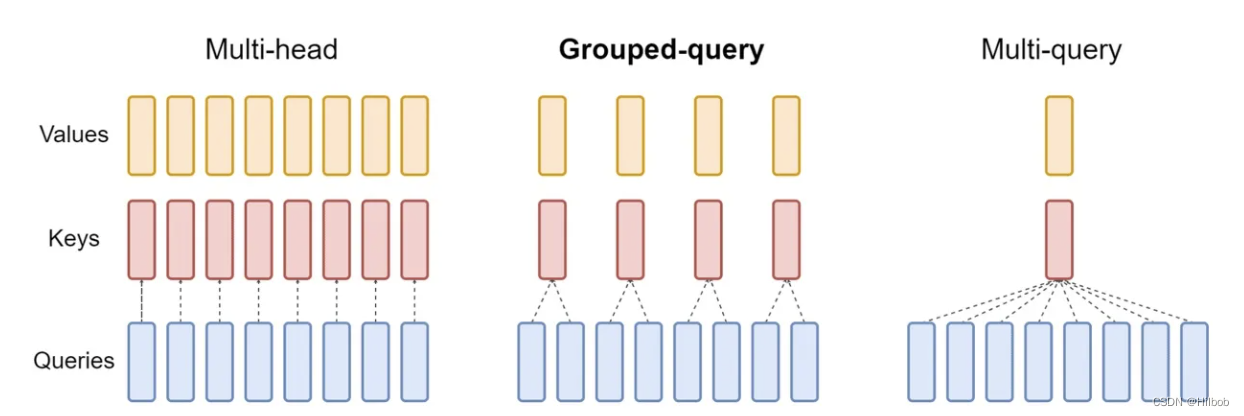
Note LLama2的注意力机制使用了GQA。三种机制的图如下: MHA机制(Multi-head Attention) MHA(Multi-head Attention)是标准的多头注意力机制,包含h个Query、Key 和 Value 矩阵。所有注意力头的 Key 和 Value 矩阵权重不共享 MQA机制(Multi-Query Attention) MQA(Multi-Que