mpi专题

poj 1502 MPI Maelstrom(单源最短路dijkstra)
题目真是长得头疼,好多生词,给跪。 没啥好说的,英语大水逼。 借助字典尝试翻译了一下,水逼直译求不喷 Description: BIT他们的超级计算机最近交货了。(定语秀了一堆词汇那就省略吧再见) Valentine McKee的研究顾问Jack Swigert,要她来测试一下这个系统。 Valentine告诉Swigert:“因为阿波罗是一个分布式共享内存的机器,所以它的内存访问

MPI与OpenMP 基本使用
MPI 注意,MPI是多进程的。 1.在程序中加入MPI支持: 加入头文件mpi.h,并在程序开头做初始化,退出时,关闭MPI。 2.编译: c文件用mpicc编译,c++文件用mpicxx编译。如: $ mpicxx how_to_use_mpi.cpp -o how_to_use_mpi 3.运行: mpirun使用mpi运行程序,-n参数指定进程数: $ m

MPI中如何发送 C++对象或结构体
1、自己把对象中需要发送/接收的元素放进一个数组中,接收之后再按照数组中的数据的顺序重新建立一个对象。如果对象中只有int,bool的话,这个还比较好办,double,string就麻烦一些。改变类的话就可能牵一发而动全身。 2、自己定义一个结构体,把对象中需要传输的信息都复制进结构体中,然后MPI_Type_struct()定义一个数据类型,就可以直接用MPI收发了。不要忘了MPI_Type_
MPI分布式计算开发和优化【王老师的嵌入式Linux实战课】
本期课程大纲 多节点运行环境配置多节点编程运行测试 课程详情 MPI分布式计算开发和优化(二) 对课程内容感兴趣或有疑问的小伙伴欢迎点击关注~ 与我起探索嵌入式Linux技术。
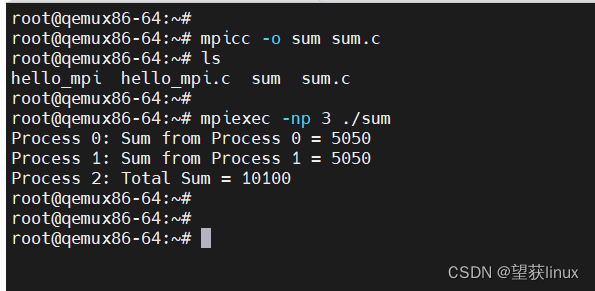
MPI并行计算关键点讲解及使用入门
MPI(Message Passing Interface)是并行计算领域的一个关键标准,它定义了一套用于在多个计算节点间进行高效消息传递和数据交换的通信协议和库。在高性能计算(HPC)领域,MPI尤为重要,特别是在处理大规模科学计算、模拟和数据分析等复杂任务时。 MPI关键点讲解 分布式内存模型 MPI基于分布式内存模型,每个计算节点(可能是独立的计算机或处理器)拥有其独立的内

编译mumps库时无法链接mpi库中的函数
安装AGMG并行版时需要mumps库。在编译mumps库链接mpi库时ld报错如下, 可以看出ld并没有报找不到mpi库的error,而是报了找到了mpi库但找不到具体的函数实现的error。 我也可以确定报的error不是mpi库自身的问题,因为(1)已经用-L 和 -l进行了显式指定,(2)这个mpi库在其他地方已经有过成功的应用。 那么为什么还是找不到相应的实现文件呢? 在sta

C++ MPI多进程并发
下载 用法 mpiexec -n 8 $PROCESS_COUNT x64\Debug\$TARGET.exe 多进程并发启动 mpiexec -f hosts.txt -n 3 $PROCESS_COUNT x64\Debug\$TARGET.exe 联机并发进程,其它联机电脑需在相同路径下有所有程序 //hosts.txt 192.168.86.16 192.168.86

分布式MPI实现矩阵乘法、卷积以及池化运算
参考文章:1. 相关代码:https://blog.csdn.net/weixin_56273009/article/details/131280755 2.多主机配置:https://blog.csdn.net/m0_62346268/article/details/134139495、https://blog.csdn.net/liu_feng_zi_/article/details/1084

4. 初探MPI——集体通信
系列文章目录 初探MPI——MPI简介初探MPI——(阻塞)点对点通信初探MPI——(非阻塞)点对点通信初探MPI——集体通信 文章目录 系列文章目录前言一、集体通信以及同步点二、`MPI_Bcast` 广播2.1 使用`MPI_Send` 和 `MPI_Recv` 来做广播2.2 `MPI_Bcast` 和 `MPI_Send` 以及 `MPI_Recv` 的比较2.3 Block

CUDA 以及MPI并行矩阵乘连接服务器运算vscode配置
一、CUDA Vscode配置 (一)扩展安装 本地安装 服务器端安装 (二) CUDA 配置 .vscode c_cpp_properties.json {"configurations": [{"name": "Linux","includePath": ["${workspaceFolder}/**"],"defines": [],"compilerPath": "/us
POJ - 1502 MPI Maelstrom dij模板题
题目链接 POJ-1502 题意 有n个基站,给定m条线路,线路上有不同的时间,从1号基站开始发送信息,当每一个基站接到信息时,它同时向其他基站发送信息,问多久能传输给所有基站。 解法 裸的最短路,画出图手推一下就知道任意基站得到信息的时间就是最短路跑出来的dis数组的值。跑一遍最短路算法找到dis数组最大值输出即可。注意输入,x代表inf,需要拿字符串处理一下,不能无脑cin。 代码

一不小心装了两个MPI,怎么卸载?
应该是不影响你使用的,反正linux只认路径,你装几个都无所谓的,请高手再详细指正,呵呵。 locate mpirun就找到mpi的位置了。至于正在使用哪个,可以查看.bashrc或.bash_profile文件。

POJ - 1502 MPI Maelstrom
MPI Maelstrom - POJ 1502 - Virtual Judge (csgrandeur.cn) 涉及算法:快读,dijkstra,链式前向星 快读模板 - AcWing POJ 1502 - MPI Maelstrom(链式前向星 + dijkstra模板题) 题意:从司令部可以走出若干个成员,每个成员去给其他营的保信,问什么时候所有营知道消息
基于Lustre文件系统的MPI-IO编程接口改进
摘 要: 针对传统MPI集群并行I/O效率不高的问题,通过分析Lustre并行文件系统的特点和MPI-IO集中式I/O操作的算法,提出了一种基于MPI-IO编程接口的改进方案,用以改善集群I/O瓶颈,提高I/O并行效率,并通过实验验证了该方案的可行性。 关键词:并行文件系统; 编程接口; 集中式I/O; Lustre; MPI-IO 为解决这一问题,通常的方法是在Lustre的上层加
MPI-2 并行IO的使用方法
转自 http://www.cnblogs.com/LCcnblogs/p/6050075.html 写的MPI程序需要用到并行IO来操作文件,但是搜遍了度娘都没有找到多少关于并行IO函数的使用方法。最后在知网搜到了一些有用的论文,看了一下,感觉豁然开朗。 MPI-1对文件的操作是使用绑定语言的函数调用来进行的,通常采用的是串行IO的读写方式,一般情况下是用一个主进程
OpenMP、MPI 和 MapReduce 对比
OpenMP和MPI是并行编程的两个手段,对比如下: OpenMP:线程级(并行粒度);共享存储;隐式(数据分配方式);可扩展性差;MPI:进程级;分布式存储;显式;可扩展性好。 OpenMP采用共享存储,意味着它只适应于SMP,DSM机器,不适合于集群。 MPI虽适合于各种机器,但它的编程模型复杂: 需要分析及划分应用程序问题,并将问题映射到分布式进程集合;需要解决
CUDA 问题解决 —— CUDA+MPI出错:mpi.h No such file or directory
在CUDA源文件里使用MPI时,编译出错 Makefile文件: CUDA_INSTALL_PATH = /usr/local/cuda-8.0MPI_INSTALL_PATH = /opt/intel/compilers_and_libraries_2017.0.098/linux/mpi/intel64NVCC = $(CUDA_INSTALL_PATH)/bin/nvccMPI
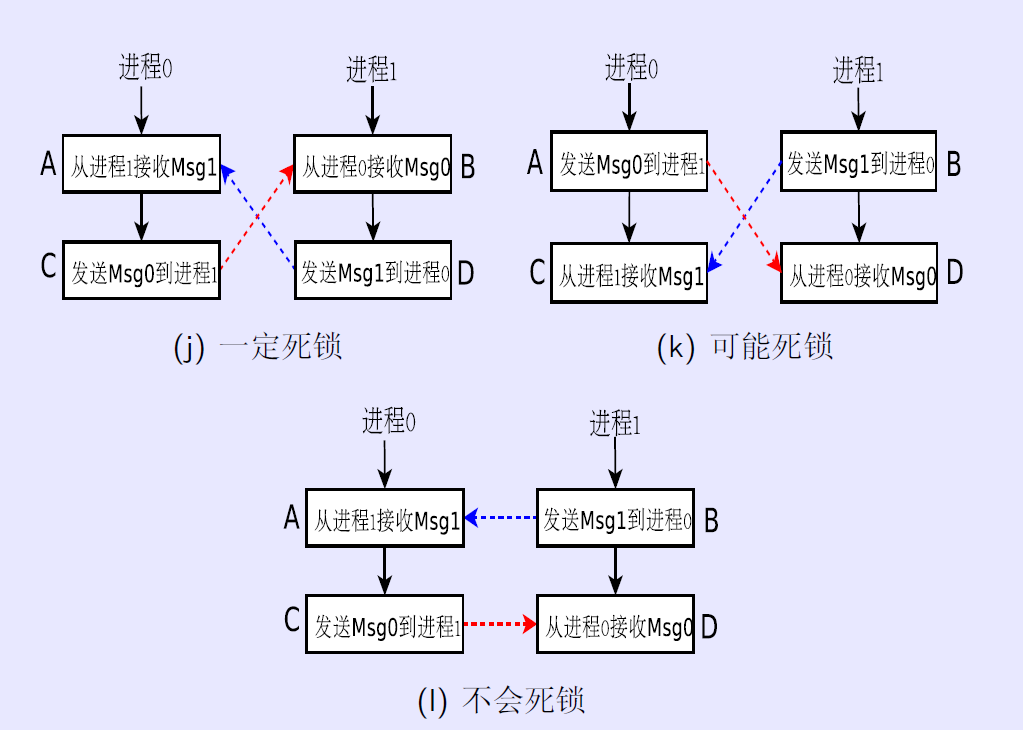
MPI学习-MPI_Sendrecv and MPI_Sendrecv_replace
死锁现象:点对点通信中存在死锁现象: MPI_Send 与MPI_Recv 1.MPI_Send调用返回时表明数据已被发出或被MPI系统复制,随后对发送缓冲区的修改不会改变所发送的数据; 2.MPI_Recv返回时表明数据接收已经完成; 3.让计算和通信重叠进行,通常先等待receive的完成,然后做计算,再等待send的完成。 4.需要采用MPI_Test()检测传输是

【MPI并行计算】Parallel Rank程序
该题的背景是不同的进程在运行时可能会有不同的状态,在这里用数值表示,有时需要让每个进程知道自己在所有进程中处于什么位置。 首先每个进程使用自己的进程号作为随机数种子生成自己的一个随机数 由于选择一个进程对所有进程数值进行排序时,该进程不仅要知道每个进程的数值,还要知道这个数值来自于哪个进程,所以这里使用结构体来存储进程号和进程数值,使用MPI_Gather时传递的是一个结构体 用于计

【MPI并行计算】对一个大规模数组求最大值
1. 首先要创建一个大规模数组,这里使用python程序生成指定长度的随机数数组,然后写入到txt文件中 2. 查看txt文件中生成的随机数数组 3. 编写mpi程序读取文件中的每一行,然后生成一个数组,这里创建10个进程,1~9进程负责计算数组的一部分,然后将其负责部分数组的最大值发送给0进程,0进程将收到的数组组成一个数组,然后对这个数组求最大值,得出最终结果 4. 程序执行结果,

【MPI并行计算】计算cosx在a~b的积分
先将a~b分成p份,然后将每个p份分为n份,对于最小的n份,其在x轴的长度为(b-a)/p/n=h,那么这最小的一份的面积就是h乘以高度,高度是cos(该长方形的在x轴的中点的坐标),其中该长方形的在x轴的中点的坐标=a+(i*n+j)+h/2(也就是按最小的长方形来计算,从a开始到这个长方形有几个,然后加上该长方形的宽的一半),所以其具体流程为:创建n个进程,将a~b分成n-1大份,然后将每一大
MPI Maelstrom MPI 大漩涡(最短路Dijkstra算法详解)
MPI Maelstrom MPI 大漩涡 目录 MPI Maelstrom MPI 大漩涡 题意描述 解题思路 注意 :里面我们会用到 atoi()函数 AC BIT has recently taken delivery of their new supercomputer, a 32 processor Apollo Odyssey distributed shared
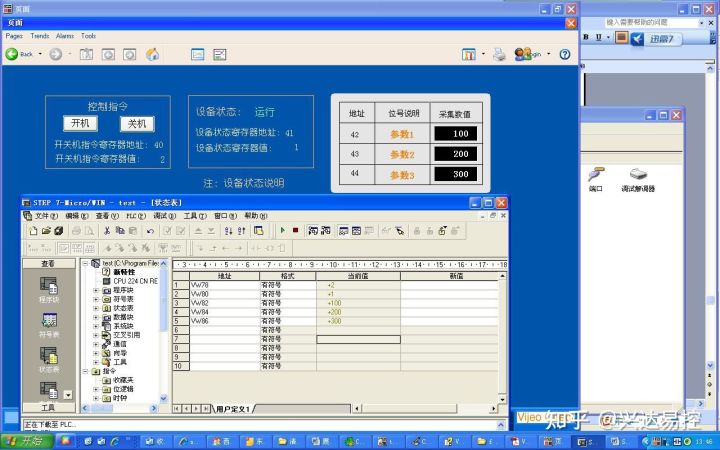
MPI转以太网模块在施耐德Vijeo_Citect 中的配置方式
西门子 PLC(S7200,S7300,S7400)连接施耐德组态软件 Vijeo_Citect,通过兴达易控MPI转以太网模块 MPI-ETH-XD1.0实现西门子系列PLC与第三方上位机软件通信 协议; 1、打开Citect 组态软件,在项目的“通信”目录下设置相关参数; 2、如下图,分别设置“集群”,“I/O 服务器”及“网络地址”; 3、如下图,分别

并行计算(MPI + OpenMP)
文章目录 并行计算MPI(进程级并行)基本结构数据类型点对点通信阻塞非阻塞非连续数据打包 聚合通信Communicator & Cartisen Grid OpenMP(线程级并行)简介基本制导语句worksharing constructSectionsSingleFor 临界区 & 原子操作Task 并行计算 并行类型: 进程级并行:网络连接,内存不共享线程级并行:共享内

Windows 7系统下搭建MPI(并行计算)环境
Windows系统下搭建MPI环境 MPI的全称是Message Passing Interface即标准消息传递界面,可以用于并行计算。MPI的具体实现一般采用MPICH。下面介绍如何在Windows XP系统下VC6中搭建MPI环境来编写MPI程序。 一.准备工作 1.1 安装MPI的SDK——MPICH2。 mpich2-1.4.1p1-win-ia32安装程序的下载地

MPI(Message-Passing Interface)实现奇偶排序
MPI奇偶排序的实现: 各个进程拿到自己需要做排序那一部分数据时即需要需要的总数除进程数(其中有不能整除问题,对于不能整除的进行填补,用最大的数填充数组最后几个元素使之能整除),先进行局部排序。第一轮偶排序时,0和进程和1号交换数据,2和3交换,进程号小的保留数据小的那一半。进行奇排序时,1和2进行交换。0和3号进程闲置。以此类推,进行p个阶段。这个根据定理。参考书籍:Introductio