mllib专题

Spark MLlib模型训练—聚类算法 PIC(Power Iteration Clustering)
Spark MLlib模型训练—聚类算法 PIC(Power Iteration Clustering) Power Iteration Clustering (PIC) 是一种基于图的聚类算法,用于在大规模数据集上进行高效的社区检测。PIC 算法的核心思想是通过迭代图的幂运算来发现数据中的潜在簇。该算法适用于处理大规模图数据,特别是在社交网络分析、推荐系统和生物信息学等领域具有广泛应用。Spa
Spark 0.9.1 MLLib 机器学习库
翻译自Spark官方文档。by月禾 Spark 0.9.1 MLLib 机器学习库简介 依赖 二元分类 线性回归 聚类 协同过滤 隐性反馈 vs 显性反馈 梯度下降基础算法 用Scala调用MLLib 二元分类 线性回归 聚类 协同过滤 用Java调用MLLib 用Python调用MLLib 二元分类 线性回归 聚类 协同过滤 MLlib 是Spark对常用的机器学

mllib之随机森林与梯度提升树
随机森林和GBTs都是集成学习算法,它们通过集成多棵决策树来实现强分类器。 集成学习方法就是基于其他的机器学习算法,并把它们有效的组合起来的一种机器学习算法。组合产生的算法相比其中任何一种算法模型更强大、准确。 随机森林和梯度提升树(GBTs)。两者之间主要差别在于每棵树训练的顺序。 随机森林通过对数据随机采样来单独训练每一棵树。这种随机性也使得模型相对于单决策树更健壮,且不易在

Spark MLlib模型训练—回归算法 Linear regression
Spark MLlib模型训练—回归算法 Linear regression 线性回归是回归分析中最基础且应用广泛的一种方法。它用于建模目标变量和一个或多个自变量之间的关系。随着大数据时代的到来,使用像 Spark 这样的分布式计算框架进行大规模数据处理和建模变得尤为重要。本文将全面解析 Spark 中的线性回归算法,介绍其原理、参数、Scala 实现、代码解读、结果分析以及实际应用场景。 1

Spark MLlib模型训练—回归算法 GLR( Generalized Linear Regression)
Spark MLlib模型训练—回归算法 GLR( Generalized Linear Regression) 在大数据分析中,线性回归虽然常用,但在许多实际场景中,目标变量和特征之间的关系并非线性,这时广义线性回归(Generalized Linear Regression, GLR)便应运而生。GLR 是线性回归的扩展,能够处理非正态分布的目标变量,广泛用于分类、回归以及其他统计建模任务。

Spark Mllib之集成算法:梯度提升树和随机森林
微信公众号:数据挖掘与分析学习 集成算法是将其他基础模型进行组合的一中算法。spark.mllib支持两种主要的集成算法:GradientBoostedTrees和RandomForest。 两者都使用决策树作为基础模型。 1.梯度提升树和随机森林 Gradient-Boosted Trees(GBTs)和Random Forest都是用于学习树集成的算法,但训练过程是不同的。 有几个

Spark Mllib之线性SVM和逻辑回归
微信公众号:数据挖掘与分析学习 1.Mathematical formulation 许多标准机器学习方法可以被公式化为凸优化问题,即找到取决于具有d个条目的变量向量w(在代码中称为权重)的凸函数f的最小化的任务。形式上,我们可以将其写为优化问题,其中目标函数形式如下: 这里向量xi∈Rd是训练数据的样本,对于1≤i≤n,yi∈R是它们对应的我们想要预测的标签。如果L(w; x,y)可以

Spark Mllib之数据类型 - 基于RDD的API
微信公众号:数据挖掘与分析学习 MLlib支持存储在单个机器上的局部向量和矩阵,以及由一个或多个RDD支持的分布式矩阵。局部向量和局部矩阵是用作公共接口的简单数据模型。其底层线性代数运算由Breeze提供。在监督学习中使用的训练示例在MLlib中称为“labeled point”。 1.局部向量(Local Vector) 局部向量具有整数类型和基于0的索引和双精度浮点型,存储在单个机器上。
Spark Mllib之基本统计 - 基于RDD的API
1.概要统计(Summary statistics) 我们通过Statistics中提供的函数colStats为RDD [Vector]提供列摘要统计信息。 colStats()返回MultivariateStatisticalSummary的一个实例,其中包含列的max,min,mean,variance和非零数,以及总计数。 SparkConf conf = new SparkConf

Spark Mllib之相关性计算和假设检验
Spark Mllib之相关性计算和假设检验 原创: 小小虫 一、皮尔逊相关性和斯皮尔曼相关性 1.1 皮尔逊相关性 要理解 Pearson 相关系数,首先要理解协方差(Covariance)。协方差表示两个变量 X,Y 间相互关系的数字特征,其计算公式为: Pearson 相关系数公式如下: 由公式可知,Pearson 相关系数是用协方差除以两个变
Spark MLlib模型训练—分类算法 Decision tree classifier
Spark MLlib模型训练—分类算法 Decision tree classifier 决策树(Decision Tree)是一种经典的机器学习算法,广泛应用于分类和回归问题。决策树模型通过一系列的决策节点将数据划分成不同的类别,从而形成一棵树结构。每个节点表示一个特征的分裂,叶子节点代表最终的类别标签。 在大数据场景下,Spark MLlib 提供了对决策树的高效实现,能够处理大规模数据
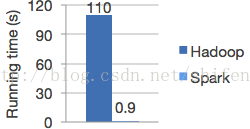
Spark MLlib系列(一):入门介绍
文章转自:http://blog.csdn.net/shifenglov/article/details/43762705 前言 最新的情况是国内BAT已经都上了spark,而且spark在hadoop上的应用,大有为大象插上翅膀的效果。个人估计在未来两到三年,spark大有代替hadoop的mapreduce的趋势。应该说spark的在使用上面的经济成本,性能优势,
Spark MLlib 特征工程系列—特征转换Tokenizer和移除停用词
Spark MLlib 特征工程系列—特征转换Tokenizer和移除停用词 Tokenizer和RegexTokenizer 在Spark中,Tokenizer 和 RegexTokenizer 都是用于文本处理的工具,主要用于将字符串分割成单词(tokens),但它们的工作方式和使用场景有所不同。 1. Tokenizer 功能: Tokenizer 是最简单的分词器,它基于空格(wh
Spark MLlib 特征工程系列—特征转换SQLTransformer
Spark MLlib 特征工程系列—特征转换SQLTransformer 1. 什么是 SQLTransformer SQLTransformer 是 Spark 提供的一个特征转换工具,它允许你通过 SQL 查询来对数据进行灵活的转换。使用 SQLTransformer,你可以直接在 DataFrame 上编写 SQL 语句,进行特征工程或数据预处理。这种方法特别适合那些对 SQL 熟悉,
Spark MLlib 特征工程系列—特征转换Polynomial Expansion
Spark MLlib 特征工程系列—特征转换Polynomial Expansion 1. Polynomial Expansion 简介 PolynomialExpansion 是 Spark MLlib 中的一种特征转换工具,主要用于将原始特征进行多项式扩展。多项式扩展通过生成原始特征的所有多项式组合来增加特征的维度,从而提高模型的表达能力。这种方法在非线性问题的建模中非常有用,因为它允

spark mllib 入门学习(二)--LDA文档主题模型
http://www.aboutyun.com/thread-22359-1-1.html 问题导读: 1.什么是LDA文档问题模型? 2.LDA 建模算法是什么样的? 3.spark MLlib中的LDA模型如何调优? 4.运行LDA有哪些小技巧? 上次我们简单介绍了聚类算法中的 KMeans算法 ,并且介绍了一个简单的KMeans的例
Spark MLlib LDA主题模型(1)
转http://blog.csdn.net/sunbow0/ Spark MLlib LDA主题模型是Spark1.3开始加入的,具体介绍看以下文档: 官方编程指南: http://spark.apache.org/docs/latest/mllib-clustering.html#latent-dirichlet-allocation-lda Spark MLlib LDA 简介: h

Parallelize your massive SHAP computations with MLlib and PySpark
https://medium.com/towards-data-science/parallelize-your-massive-shap-computations-with-mllib-and-pyspark-b00accc8667c (能翻墙直接看原文) A stepwise guide for efficiently explaining your models using SHAP.
《Learning Spark》第十一章:Spark(MLlib)与机器学习
2020/07/06 - 引言 我一直以为这部分内容,其实没有什么大不了的,反正就是弄出来数据,然后跑算法就完事了嘛。但是仔细读了读这小节,发现了一些不一样的地方。这里来列举一下,我读完这个章节之后的一些想法,然后再具体来记录这部分的主要内容。 1)他算法的输入是需要转化一下的(向量),我看到的大多是通过了某种特征工程的东西,然后这种就已经是满足的数据格式了,不知道普通的矩阵向量应该怎么弄呢?m
Apache Spark MLlib机器学习详解
Apache Spark MLlib 是 Spark 的一个核心组件,用于提供可扩展的机器学习算法库。MLlib 包含了各种常见的学习算法和实用程序,如分类、回归、聚类、协同过滤、降维等,以及底层的优化原语和高层次的管道API。 以下是关于 Spark MLlib 的一些关键特点和功能: 算法丰富:MLlib 提供了大量的机器学习算法,包括线性模型(如逻辑回归、线性回归)、决策树、随机森林、
Spark MLlib 机器学习
Spark MLlib是一个在Apache Spark上构建的机器学习库,用于解决大规模数据集上的机器学习问题。它提供了一组丰富的机器学习算法和工具,可以用于分类、回归、聚类、推荐和协同过滤等任务。同时,它还提供了一些特征提取、特征转换和特征选择的工具,可以帮助用户准备数据集以供机器学习算法使用。 Spark MLlib的设计目标是兼容Spark的分布式计算框架,以便能够处理大规模数据集和实现分

小白的学习资料:Spark MLlib 机器学习详细教程
Spark MLlib 机器学习详细教程 Apache Spark 是一个强大的开源分布式计算框架,广泛用于大数据处理和分析。Spark 提供了丰富的库,其中 MLlib 是其机器学习库,专为大规模数据处理设计。本教程将详细介绍 Spark MLlib,包括其主要功能、常见应用场景、具体实现步骤和示例代码。 目录 Spark MLlib 简介安装与配置数据准备常见算法与应用场景 线性回归逻辑

Spark MLlib 机器学习详解
目录 🍉引言 🍉Spark MLlib 简介 🍈 主要特点 🍈常见应用场景 🍉安装与配置 🍉数据处理与准备 🍈加载数据 🍈数据预处理 🍉分类模型 🍈逻辑回归 🍈评价模型 🍉回归模型 🍈线性回归 🍈评价模型 🍉聚类模型 🍈K-means 聚类 🍈评价模型 🍉降维模型 🍈PCA 主成分分析 🍉 协同过滤 🍈ALS
Spark Mllib数据挖掘入门十一——综合案例
本文主要研究一个较为基础的、经典的数据挖掘任务,包括数据的预处理、数据的分析性挖掘和多种MLlib算法的使用。 具体目标是研究不同的鸢尾花的生长分布,以及种类的判定方法,其中会使用到回归分析方法以及决策树方法,这些都是现实中常用的数据挖掘方法。 1.建模说明 不同种类的鸢尾花有着不同的特征外貌,相同一类的鸢尾花有不同的特征,而不同类的鸢尾花可能会有着相同的特征,因此研究其分类并对其做出预测以提
Spark Mllib数据挖掘入门十——数据降维
数据降维又称为维数约简,从名称上看就是降低数据的维数。目前MLlib中使用的降维方法主要有两种:奇异值分解(SVD)和主成分分析(PCA)。 1.奇异值分解(SVD) 奇异值分解是矩阵分解计算的一种常用方法,将一个矩阵分解成带有方向向量的矩阵相乘。将一个大矩阵分解为若干个低维度的矩阵来表示是其最终目的。对于数据中包含的一些不是很重要的信息,可以通过不同的方式给予去除,从而可以节省资源以投放在更
Spark Mllib数据挖掘入门九——特征提取和转换
与数据降维相同,特征提取和转换也是处理大数据的一种常用方法和手段,其目的是创建新的能够代替原始数据的特征集,更加合理有效地展现数据的重要内容。特征提取指的是由原始数据集在一定算法操作后创建和生成的新的特征集,这种特征集能够较好地反映原始数据集的内容,同时在结构上大大简化。 MLlib中目前使用的特征提取和转换方法主要有TF-IDF、词向量化、正则化、特征选择等。 1.TF-IDF MLlib中