本文主要是介绍Spark MLlib系列(一):入门介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章转自:http://blog.csdn.net/shifenglov/article/details/43762705
前言
最新的情况是国内BAT已经都上了spark,而且spark在hadoop上的应用,大有为大象插上翅膀的效果。个人估计在未来两到三年,spark大有代替hadoop的mapreduce的趋势。应该说spark的在使用上面的经济成本,性能优势,一站式解决能力,一定会使其大放异彩。
因为个人对spark很感兴趣,加上项目中需要使用它解决一些机器学习的问题,在网上搜集资料时发现,spark machine learning这块的资料确实太缺少了,所以决定写一spark machine learning的一系列博客(只涉及机器学习部分)。
目前考虑是,这个系列,先讲一些入门的知识,然后是一些真正的实战应用,可能涉及到推荐,聚类,分类等问题,理论涉及不会太多,分享一些接地气的干货,让大家能够真正感受到spark machine learning的魅力。
为什么使用MLlib
MLlib 构建在apache spark之上,一个专门针对大量数据处理的 通用的、快速的引擎
- Speed.Spark has an advanced DAG execution engine that supports cyclic data flow and in-memory computing. Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
- Ease of Use .Write applications quickly in Java, Scala or Python.
- Generality.Combine SQL, streaming, and complex analytics.
- Runs Everywhere.Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, S3.
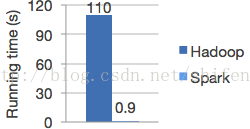
Logistic regression in Hadoop and Spark
概述
MLlib 是spark的可以扩展的机器学习库,由以下部分组成:通用的学习算法和工具类,包括分类,回归,聚类,协同过滤,降维,当然也包括调优的部分
- Data types
- Basic statistics (基本统计)
- summary statistics 概括统计
- correlations 相关性
- stratified sampling 分层取样
- hypothesis testing 假设检验
- random data generation 随机数生成
- Classification and regression (分类一般针对离散型数据而言的,回归是针对连续型数据的。本质上是一样的)
- linear models (SVMs, logistic regression, linear regression) 线性模型(支持向量机,逻辑回归,线性回归)
- naive Bayes 贝叶斯算法
- decision trees 决策树
- ensembles of trees (Random Forests and Gradient-Boosted Trees) 多种树(随机森林和梯度增强树)
- Collaborative filtering 协同过滤
- alternating least squares (ALS) (交替最小二乘法(ALS) )
- Clustering 聚类
- k-means k均值算法
- Dimensionality reduction (降维)
- singular value decomposition (SVD) 奇异值分解
- principal component analysis (PCA) 主成分分析
- Feature extraction and transformation 特征提取和转化
- Optimization (developer) 优化部分
- stochastic gradient descent 随机梯度下降
- limited-memory BFGS (L-BFGS) 短时记忆的BFGS (拟牛顿法中的一种,解决非线性问题)
MLlib当前在非常活跃的开发情况下,所以那些被标记成
Experimental/DeveloperApi 在未来的发布种可能会被修改 依赖
MLlib使用了线性代数包 Breeze, 它依赖于netlib-java和jblas。netlib-java 和 jblas 需要依赖native Fortran routines。所以你需要安装gfortran runtime library (安装方法在这个链接中),如果你的集群的节点中没有安装native Fortran routines。MLlib 会抛出一个link error,如果没有安装native Fortran routines。
如果你需要使用spark的python开发,你需要 NumPy version 1.4或以上版本.
当前最近版本1.2
个人认为当前1.2版本的最大的改进应该是发布了称为spark.ml的机器学习工具包,支持了pipeline的学习模式,即多个算法可以用不同参数以流水线的形式运行。在工业界的机器学习应用部署过程中,pipeline的工作模式是很常见的。新的ML工具包使用Spark的SchemaRDD来表示机器学习的数据集合,提供了Spark SQL直接访问的接口。此外,在机器学习的算法方面,增加了两个基于树的方法,随机森林和梯度增强树。还有貌似性能上有优化,看过一篇DataBricks的ppt,据说1.2版本的算法在性能上比1.1版本平均快了3倍
参考资料
Machine Learning Library (MLlib) Programming Guide http://spark.apache.org/docs/latest/mllib-guide.html
Spark ML Programming Guide http://spark.apache.org/docs/latest/ml-guide.html
这篇关于Spark MLlib系列(一):入门介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







