lz77专题
![[原创]用哈希表优化的lz77压缩算法的实现](http://images.csdn.net/syntaxhighlighting/OutliningIndicators/InBlock.gif)
[原创]用哈希表优化的lz77压缩算法的实现
最近终于有空研究研究E*F的K*KYU2。和预料到的一样仍然是广泛使用LZ77,而且是毫不改变地使用LZ77……但是,时代进步了,图片文件都是真彩色的了,大小变大了3倍,仍然使用LZ77的代价就是速度……大家都知道LZ77的特点就是解压超快,压缩巨慢(不然就不会有LZW这种不伦不类的算法出来了……)在png的相关网站上查找了一下优化方案,自己写了一下优化代码,虽然目前速度仍然不能很让人满意(
![[数据结构和算法]LZ77压缩算法三部曲——3.解压算法(C语言)](https://img-blog.csdnimg.cn/20181027140927495.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NsaW1tbQ==,size_27,color_FFFFFF,t_70)
[数据结构和算法]LZ77压缩算法三部曲——3.解压算法(C语言)
压缩算法后面有需要再补写,先记录一下解压算法吧。 压缩算法用Java写的,压缩的是字节流。(测试原数据1024bytes–压缩后为201bytes) 直接上菜吧 #include <stdio.h>#include <stdlib.h>#include <string.h>#define BUFFER_LEN 128#define SLIDE_LEN 512#define MAX

LZ77编码和部分实现 20级孙溢
LZ77编码 由Ziv和Lempel于1977年提出,故称为LZ77算法。 编码器通过一个滑动窗口来查看输入序列,其中滑动窗口包含搜索缓冲区和前瞻缓冲区, 搜索缓冲区包含字典——最近编码的数据,而前瞻缓冲区包含要编码的输入数据序列的下一部分,滑动窗口的尺寸是影响压缩性能的关键因素。编码过程为:编码前瞻缓冲区,编码器在编码时会一直在搜索缓冲区搜索直到找到最大匹配字符串。匹配字符串的开始字符串与
无损压缩编码(上):LZ编码——详解LZ77 (LZSS)、LZ78和LZW的编码与译码
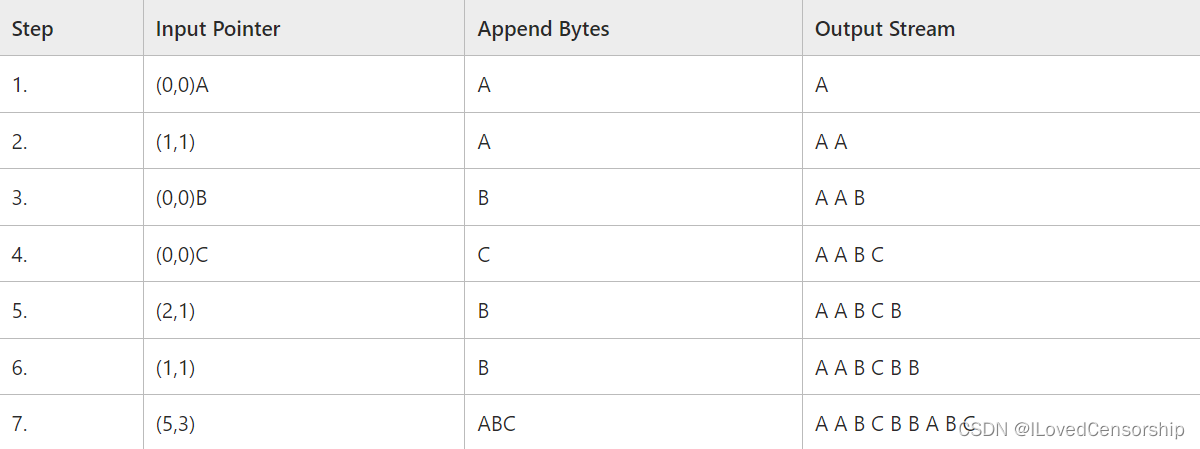
LZ77和LZ78由Abraham Lempel和Jacob Ziv分别于1977年和1978年发表,LZ即为Lempel和Ziv的首字母拼在一起。1984年Terry Welch在LZ78的基础上进行改进,发表了LZW(即Lempel–Ziv–Welch)编码。三种编码均为无损压缩编码,旨在不产生信息失真的同时降低信息冗余度。 三种编码的核心在于,按顺序读取待编码数据流,如果后面的数据流出现了

基于Huffman和LZ77压缩(三)LZ77思路分析
Huffman压缩详细分析 LZ77: 基于重复语句的压缩 1 什么是LZ77 1977年两个以色列人提出的基于重复语句上的通用的压缩算法--------将重复语句替换成更短的<长度, 距离, 下个字符串首字母>对的方式。 真正的LZ77用的是一个三元组(长度距离对 + 下一个语句的首字母 ) 为什么叫基LZ77算法的压缩? 上边介绍了 原LZ77 的处理方式: <长度, 距离, 下