kudu专题

实时数仓链路分享:kafka =SparkStreaming=kudu集成kerberos
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! 本文档主要介绍在cdh集成kerberos情况下,sparkstreaming怎么消费kafka数据,并存储在kudu里面 假设kafka集成kerberos假设kudu集成kerberos假设用非root用户操作spark基

通过java程序对kudu表进行权限操作
对kudu表进行权限操作除了上述通过impala-shell和hue界面进行SQL操作外,还可以通过Java client、C++ client、Python client操作kudu表,这里介绍通过java程序对kudu表进行权限操作。 一、Impala jdbc连接hive和kudu准备工作 1.配置环境IDEA和JDK 此处不做说明,请自行完成。 2.IDEA搭建maven安装、下载

对kudu表进行权限管理
对kudu表操作之前,需要先安装impala并配置sentry服务,因为kudu表可以通过impala-shell的SQL操作。详情请参考https://blog.csdn.net/u013168084/article/details/99690353 Kudu是Cloudera开源的新型列式存储系统,是Apache Hadoop生态圈的新成员之一(incubating),专门为了对快速变化的数


关于kudu使用的一些问题及解决办法
在client 1.5之前,由于kudu客户端链接的token有效时间是7天,当时间大于7天的时候token失效,客户端不会主动去刷新token,导致写入数据报错; 解决办法:kudu-client 版本使用1.5以上的版本 kudu数据flush的模式问题 AUTO_FLUSH_BACKGROUND:异步刷新可能会导致写入的时候乱序,因此有严格的顺序的写入操作可能要使用AUTO_

ubuntu 16.04部署安装kudu
由于ubuntu 16.04自带的源中没有kudu相关的包,需要配置系统的源 一、配置如下: 1、从 http://archive.cloudera.com/kudu/ubuntu/xenial/amd64/kudu/cloudera.list 下载源的配置,下载之后如下: 2、把下载的内容添加到/etc/apt/sources.list中 3、 添加公匙: 从http://cl
impala和kudu使用的小细节
之前入门的小错误总结,建表都会出错,真的好尴尬 还是要做好笔记 第一个错误: error:AnalysisException:Table property 'kudu.master_addresses' is required when the impalad startup flat -kudu_master_hosts is not used. answer:'kudu.maste

kudu-impala分区表(hash和range分区)
展开 1、分区表支持hash分区和range分区,根据主键列上的分区模式将table划分为 tablets 。每个 tablet 由至少一台 tablet server提供。理想情况下,一张table分成多个tablets分布在不同的tablet servers ,以最大化并行操作。 2、Kudu目前没有在创建表之后拆分或合并 tablets 的机制。 3、创建表时,必须为表提供分区模式。
KUDU的相关内容,KUDU的优劣势
KUDU的相关内容 kudu的简介kudu是什么那么怎么读取数据呢什么是IMPALA? kudu适用场景对比 kudu的简介 kudu是什么 kudu其实是一种引擎,是一种针对HIVE的引擎。 那么怎么读取数据呢 使用IMAPALA读取数据,IMPALA可以选择各种hive引擎,而KUDU就是其中之一 什么是IMPALA? 说得明白一点其实就相当于是mysql中得nav

Apache Kudu 1.4.0 中文文档
ApacheCN cwiki 地址为 : http://cwiki.apachecn.org/pages/viewpage.action?pageId=10813594 已完成 80%,欢迎加入我们一起来完成翻译!~ 还差一点点就完工了,欢迎有想法的朋友,一起来维护迭代更新,另找找一位 kudu 的 admin,专门跟进这个事情,需要花的时间,稍微多一点点,有兴趣的联系我!!!
导出 CDH 中各组件(HDFS、Hive、Impala、Kafka、Kudu、YARN和Zookeeper)指标到 Prometheus
文章目录 前言一、提取准备1. 下载jmx2. 创建规则文件 二、HDFS指标提取1. namenode指标提取2. datanode指标提取 二、Hive指标提取1. Hive Metastore Server 指标提取2. HiveServer2 指标提取 三、Impala 指标提取1. Impala Catalog Server 指标提取2. Impala Daemon 指标提取 四、

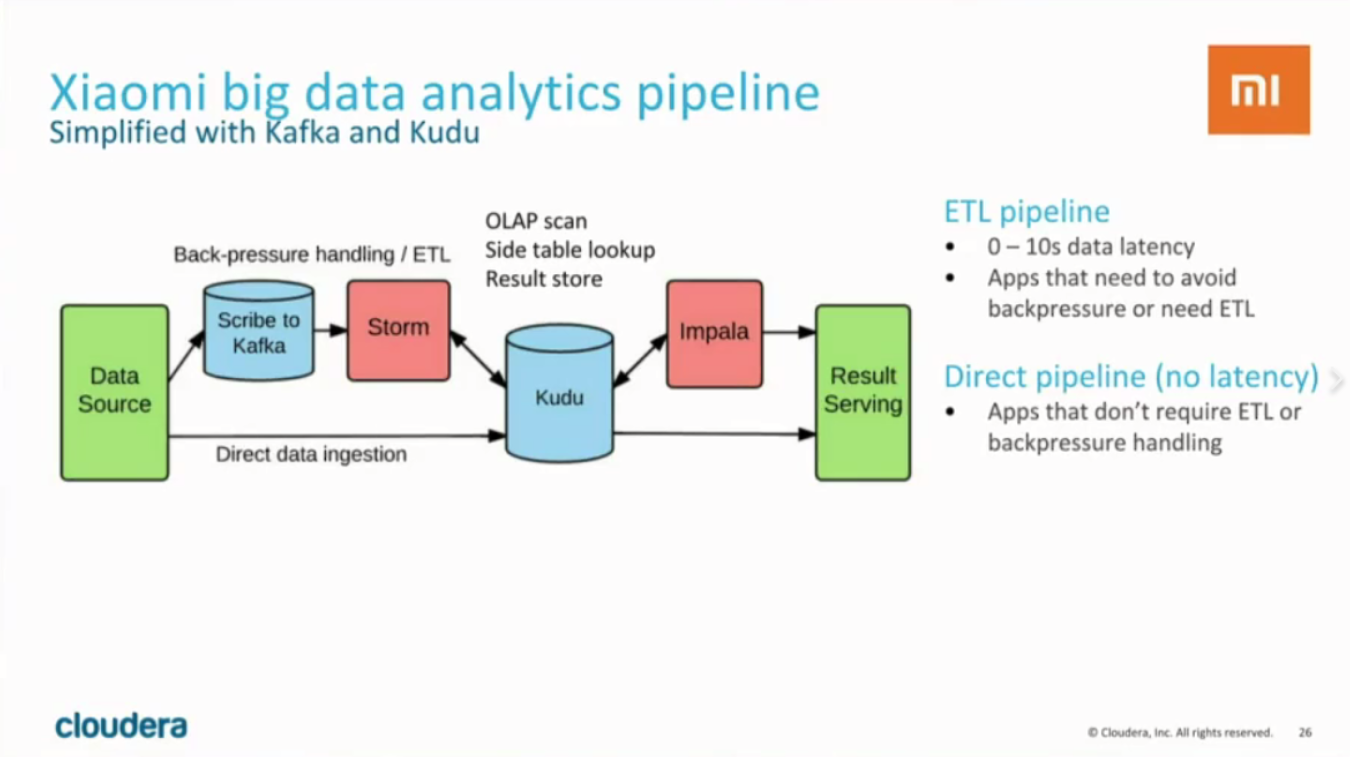
Apache kudu在网易的实践
导读:Kudu作为一款新型分布式系统,能够实现在数据快速读写的同时,提供媲美HDFS顺序扫描的性能,是对大数据生态的补充,是构建实时数仓的一款利器。我们把kudu深度集成进了网易有数大数据平台,用来支持和构建网易云音乐和网易传媒的实时数据仓库。本次分享的主要内容是网易在使用kudu的一些实践经验。
![[Spark SQL]Spark SQL读取Kudu,写入Hive](https://img-blog.csdnimg.cn/06e551a7a0d54922bff511126b300587.png)
[Spark SQL]Spark SQL读取Kudu,写入Hive
SparkUnit Function:用于获取Spark Session package com.example.unitlimport org.apache.spark.sql.SparkSessionobject SparkUnit {def getLocal(appName: String): SparkSession = {SparkSession.builder().appName(
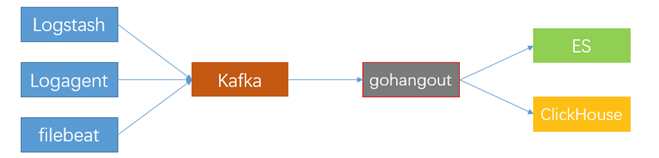
Hbase、Kudu和ClickHouse横向对比
好记忆不如烂笔头,能记下点东西,就记下点,有时间拿出来看看,也会发觉不一样的感受. 目录 1 前言 2 安装部署方式对比 3 组成架构对比 4 基本操作对比 4.1 数据读写操作 4.2 数据查询操作 5 HBASE在滴滴出行的应用场景和最佳实践 5.1 订单事件 5.2 司机乘客轨迹 5.3 ETA 5.4 监控工具DCM 5.5 小结 6 网易考拉基于KUDU构建实
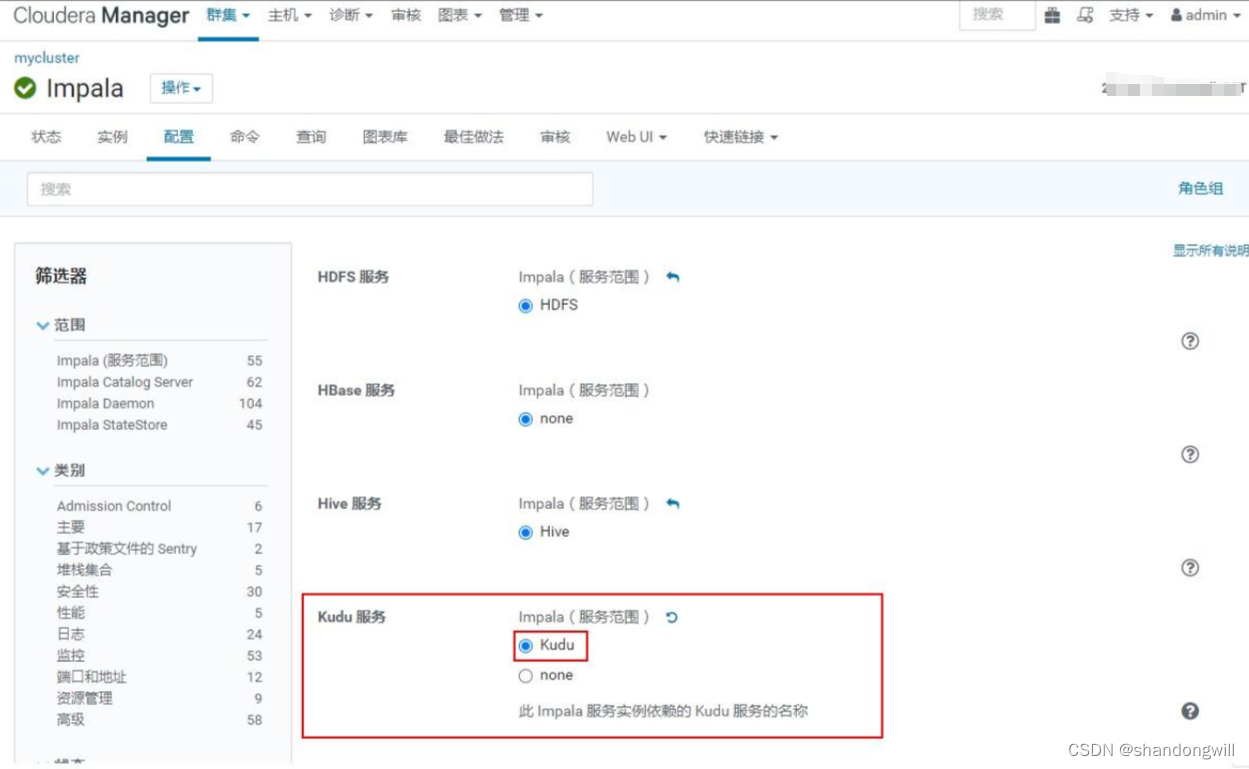
impala与kudu进行集成
文章目录 概要Kudu与Impala整合配置Impala内部表Impala外部表Impala sql操作kuduImpala jdbc操作表如果使用了Hadoop 使用了Kerberos认证,可使用如下方式进行连接。 概要 Impala是一个开源的高效率的SQL查询引擎,用于查询存储在Hadoop分布式文件系统(HDFS)中的大规模数据集。它提供了一个类似于传统关系型数据库的
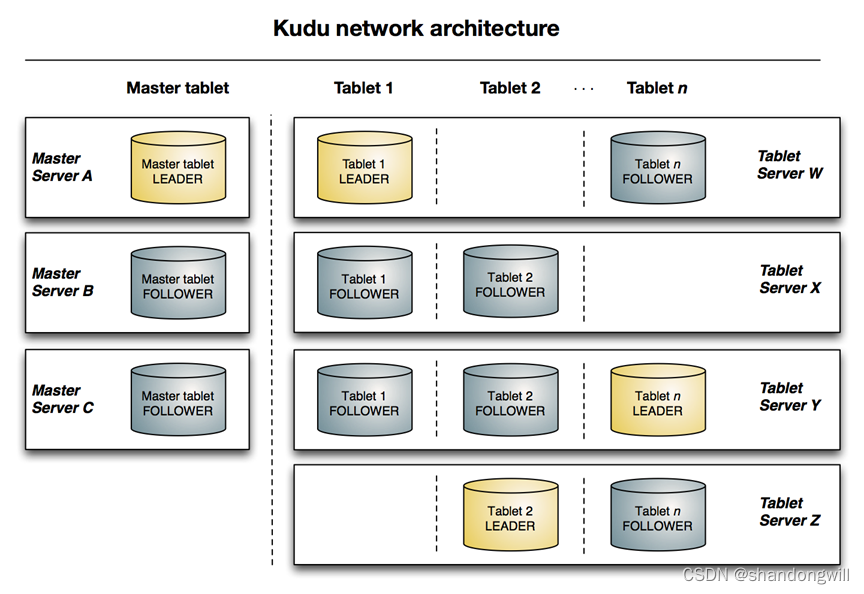
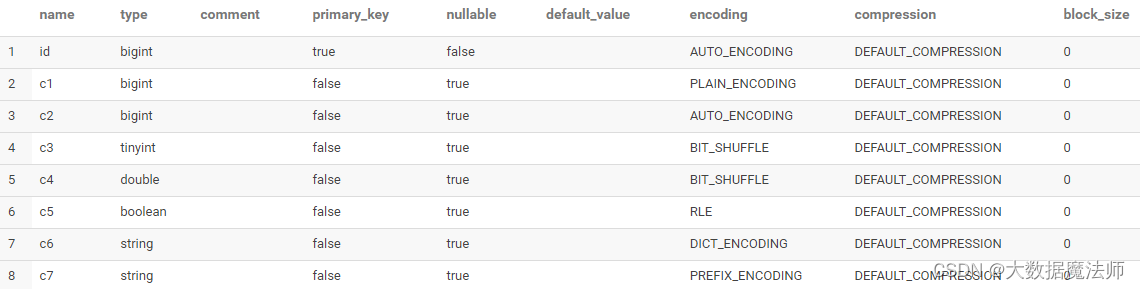
Impala-查询Kudu表详解(超详细)
文章目录 前言一、使用Impala查询kudu表介绍1. 使用Impala与Kudu表的好处2. 配置Impala以使用Kudu3. Kudu副本因子 二、Impala DDL增强功能1. Kudu表的主键列2. Kudu表特定的列属性1. 主键属性2. NULL | NOT NULL属性3. DEFAULT属性4. ENCODING属性5. COMPRESSION属性6. BLOCK_SI
Impala、Kudu和Hive综合示例
1. 引言 Impala、Kudu和Hive是常用的大数据处理工具和技术。Impala是一个快速的SQL引擎,用于实时查询大规模数据集。Kudu是一种高性能、分布式的列式存储引擎,用于实时分析和快速随机访问数据。Hive是一个基于Hadoop的数据仓库基础设施,支持使用HiveQL进行数据分析。 本文将通过一个综合示例展示如何使用Impala、Kudu和Hive进行数据处理和分析。 2. 示
python操作kudu
具体代码如下 import kudufrom kudu.client import Partitioningfrom datetime import datetime# 连接到kudu主服务器client = kudu.connect(host='kudu.master', port=7051)# 为新表定义架构builder = kudu.schema_builder()builde
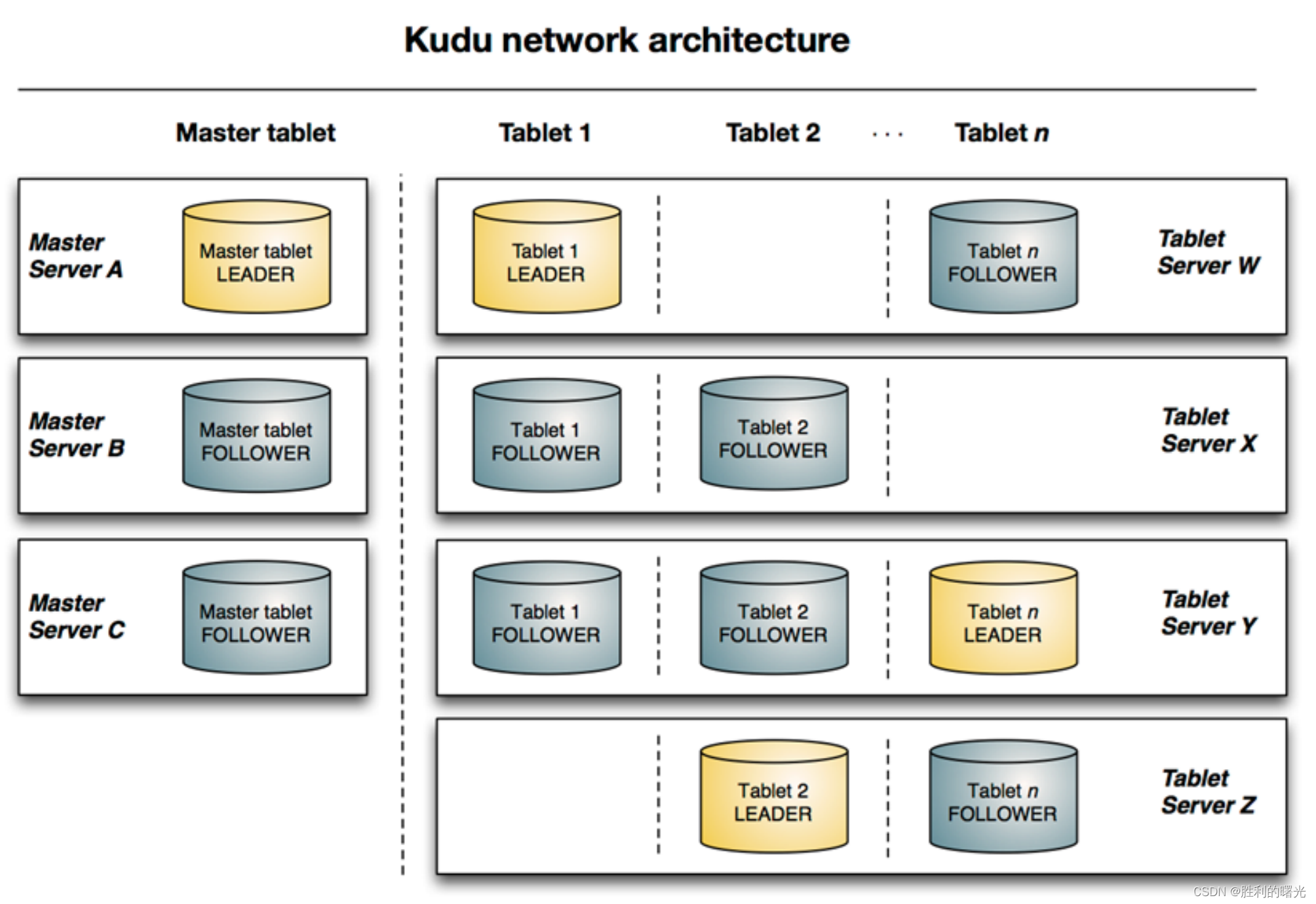
数据存储折中法——Kudu介绍
Kudu介绍 背景介绍 在Kudu之前,大数据主要以两种方式存储: 静态数据: 以 HDFS 引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景。这类存储的局限性是数据无法进行随机的读写。 动态数据: 以 HBase、Cassandra 作为存储引擎,适用于大数据随机读写场景。这类存储的局限性是批量读取吞吐量远不如 HDFS,不适用于批量数据分析的场景。 从上面分析可知,这两种数据在
转载:一文读懂 Apache Kudu
原始链接:https://www.jianshu.com/p/83290cd817ac 一文读懂 Apache Kudu 前言 Apache Kudu是由Cloudera开源的存储引擎,可以同时提供低延迟的随机读写和高效的数据分析能力。Kudu支持水平扩展,使用Raft协议进行一致性保证,并且与Cloudera Impala和Apache Spark等当前流行的大数据查询和分析工具结合
一文读懂 Apache Kudu
前言 Apache Kudu是由Cloudera开源的存储引擎,可以同时提供低延迟的随机读写和高效的数据分析能力。Kudu支持水平扩展,使用Raft协议进行一致性保证,并且与Cloudera Impala和Apache Spark等当前流行的大数据查询和分析工具结合紧密。本文将为您介绍Kudu的一些基本概念和架构以及在企业中的应用,使您对Kudu有一个较为全面的了解。 一、为什么需要Ku

Streamsets Postgresql 实时同步到Kudu
Streamsets提供两种方式同步Postgresql,一种是JDBC、query,另一种是CDC方式,实时同步需要两者结合来首次同步。 首先需要全表同步,采用JDBC方式比较好: 这个比同步Mysql方便,可以写多个模式多个表同时同步。 这个是完成一次同步就触发,不至于没有数据进来报错。下一次事务继续同步。 这个一定要配置,不然_int json 格式就会报错。

streamsets3.21 Elasticsearch数据处理,输入到kudu、mysql
部分用法的官方链接: https://streamsets.com/documentation/datacollector/3.21.x/help/index.html 中文站: http://streamsets.vip/ 上一篇文章写了mysql实时同步kudu,链接放这里 https://blog.csdn.net/kkHMou/article/details/115330489 一、e