keyed专题

Apache Flink:Keyed Window与Non-Keyed Window
Apache Flink中,Window操作在流式数据处理中是非常核心的一种抽象,它把一个无限流数据集分割成一个个有界的Window(或称为Bucket),然后就可以非常方便地定义作用于Window之上的各种计算操作。本文我们主要基于Apache Flink 1.4.0版本,说明Keyed Window与Non-Keyed Window的基本概念,然后分别对与其相关的WindowFunction

Flink Keyed State ,Operator State 作用 区别 用法
Flink的State类型 基本类型划分: 在Flink中,按照基本类型,对State做了以下两类的划分: Keyed State,和Key有关的状态类型,它只能被基于KeyedStream之上的操作,方法所使用。我们可以从逻辑上理解这种状态是一个并行度操作实例和一种Key的对应, <parallel-operator-instance, key>。 Operator State(或者non

Flink Keyed State 实例
1 sourceStream必须要先keyBy然后才能使用Keyed State 2 需要继承RichxxxxFunction才行,在open之前声明,在open中初始化,在算子方法中使用和处理。不能继承xxxxxFunction,因为没有open方法,无法初始化,会报错。 3 open方法中只能初始化Keyed State,无法使用Keyed State(比如:获取值等操作),不然报错。因为
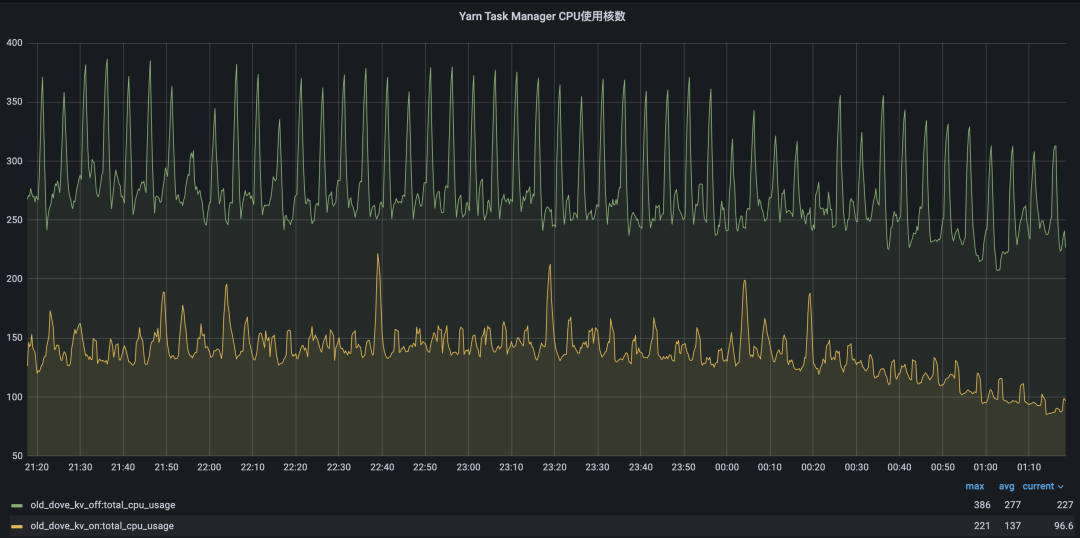
Flink Keyed State的优化与实践
本期作者 1.背景 Flink SQL在业务使用中有较多的双流join场景,当左右流的流量都较大,Join的等待时间即使为1小时,Flink Keyed State(Flink State分Operator State和Keyed State,后文所有State均代表后者)的存储大小也很容易达到TB级(内部默认使用的是RocksDBStateBackend)。 在State我们内部[

【flink番外篇】7、flink的State(Keyed State和operator state)介绍及示例(1) - Keyed State
Flink 系列文章 一、Flink 专栏 Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 3、Flik Table API和SQL基础系列 本部